【相关问题解答2】bert中文文本摘要代码
- 写在最前面
- 问题1:tokenizer.py中encode函数,不能使用lower操作
- 关于提问
- 问题描述1
- 一些建议1
- 问题更新2:结果输出为一些重复的标点符号和数字
- 一些建议2
- 1. 数据检查和预处理
- 2. 模型和训练配置
- 3. 过拟合和欠拟合
- 4. 检查训练过程
- 5. 进行实验和记录
- 问题2:结果输出为一些重复的标点符号和数字
- 问题描述
- 一些建议
- 1. 检查模型输入
- 2. 检查预训练模型和权重
- 3. 检查模型配置
- 4. 调试代码
- 5. 代码和数据问题
- 6. 运行示例数据
- 7. 查找错误信息

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
感谢大家的支持和关注。
最近好多人咨询之前博客【bert中文文本摘要代码】的相关代码报错问题,由于报错有一定的相似性,因此这里统一进行答复
之前的相关博客链接,感兴趣的uu可以点击跳转:
bert中文文本摘要代码(1)
bert中文文本摘要代码(2)
bert中文文本摘要代码(3)
【相关问题解答1】bert中文文本摘要代码:import时无法找到包时,几个潜在的原因和解决方法
【相关问题解答2】bert中文文本摘要代码:结果输出为一些重复的标点符号和数字
问题1:tokenizer.py中encode函数,不能使用lower操作
关于提问
题外话:这样清晰的提问真的爱了,描述的特别清晰,也方便根据我的一点经验给出一写些可供参考的想法建议
有些uu提问,让我回想起之前自己请教大佬hh
我的视角like:其实特别想给出点建议,但是有点“抽象”,描述的问题不具体
再加上可能我也没学到位,所以很难给出对应的问题解决方案,有点爱莫能助
让我想起了之前写的一篇博客笔记,感兴趣的uu可以看看:开发中遇到问题如何更好地提问
问题描述1
您好,我想请教一个问题,在tokenizer.py中,关于encode函数这里,将first_text先转为小写是为什么,我在调试时发现first_text类型为int,不能使用lower操作,请问应该怎么操作能行得通,还是我其他地方出了问题?
encode函数
@classmethoddef encode(cls, first_text, second_text=None, max_length=512):first_text = first_text.lower()first_text = unicodedata.normalize('NFD', first_text)first_token_ids = [cls.word2idx.get(t, cls.unk_id) for t in first_text]first_token_ids.insert(0, cls.cls_id)first_token_ids.append(cls.sep_id)if second_text:second_text = second_text.lower()second_text = unicodedata.normalize('NFD', second_text)second_token_ids = [cls.word2idx.get(t, cls.unk_id) for t in second_text]second_token_ids.append(cls.sep_id)else:second_token_ids = []
一些建议1
在encode函数中遇到的问题可能是因为,您的使用场景和函数预期的输入类型不匹配。
encode函数设计的目的是对文本进行编码。函数中使用first_text.lower()是为了将输入文本统一转换为小写,这样做的目的是为了减少单词的变体数量,从而增强模型对不同形式的相同单词的识别能力。同时,使用unicodedata.normalize('NFD', first_text)是为了将文本规范化,这有助于统一字符的表示(例如,去除重音符号等)。
如果在您的调试过程中发现first_text的类型为int而不是预期的字符串类型,这很可能是因为在调用encode方法前,传入的参数类型不正确。要解决这个问题,请检查以下几个方面:
-
调用
encode函数的位置: 确保在调用此函数之前,传入的first_text和second_text参数确实是字符串类型的文本。如果您在使用过程中某个地方传入了整数(int),请仔细检查为什么会出现这种情况。 -
数据处理流程: 回顾和检查整个数据处理流程,确认在传入
encode函数之前,所有的文本数据都正确地以字符串形式处理和传递。这可能涉及到对数据源和预处理步骤的审核。 -
参数检查: 为了提高代码的健壮性,您可以在
encode函数的开头添加参数类型检查的代码。如果发现参数类型不符,可以抛出异常或转换类型。例如:if not isinstance(first_text, str):raise ValueError(f"Expected first_text to be a str, got {type(first_text)} instead.")
通过这些步骤,应该能够识别出问题所在,并确保encode函数能够接收正确类型的文本数据进行处理。
如果在检查和调整后仍然遇到问题,请仔细检查调用encode函数的上下文,确保没有其他地方错误地修改了数据类型。
问题更新2:结果输出为一些重复的标点符号和数字
我是在test.py中遇到的上述问题,后来我尝试使用str将其变为字符串类型,能够顺利运行了,但是test的结果很糟糕,形式为:“摘要:,,,,,,,”,就基本都是标点符号,不只是逗号还有句号问好等,甚至出现好几行的“的”,并没有出现摘要表情包,不知道是不是我的训练出了问题,训练结果的损失值也比较大,可能是参数调的不对,还请您提点我一下
一些建议2
看来已经解决了之前遇到的运行错误,但现在的问题是模型的测试结果不理想,主要输出是重复的标点符号和“的”字,没有生成有效的摘要。
这种情况通常指向几个潜在的问题,包括模型训练不足、数据处理不当或参数配置不适当。以下是一些改进模型表现和调试的建议:
1. 数据检查和预处理
- 数据质量:确保训练数据质量高,数据中的文本摘要对应关系准确无误。数据的噪声和错误会直接影响模型的学习。
- 数据预处理:确保文本数据的预处理步骤正确执行,包括但不限于分词、去除无关字符、文本规范化等。不恰当的预处理会导致模型无法学习到有效的信息。
2. 模型和训练配置
- 参数调优:可能需要调整模型的学习率、批处理大小、训练周期数等参数。过大或过小的学习率都可能导致训练结果不佳。
- 模型结构:确认模型结构是否适合您的任务。对于文本摘要任务,可能需要特定的注意力机制或更深的网络结构来捕捉长距离依赖关系。
- 损失函数:检查使用的损失函数是否适合文本摘要任务,以及是否正确实现和应用。
3. 过拟合和欠拟合
- 过拟合:如果训练数据很少,模型可能会过拟合,即只学习到训练数据上的特定模式,而无法泛化到未见过的数据。尝试增加数据量,或使用正则化技术如dropout。
- 欠拟合:如果模型太简单或训练不足,可能会欠拟合,表现为训练和测试性能都不佳。增加模型复杂度或延长训练时间可能有所帮助。
4. 检查训练过程
- 损失值监控:密切监控训练和验证损失值,以判断模型是否在学习。如果损失值减少很慢或不减少,可能需要调整学习率或其他参数。
- 早期停止:如果验证损失开始增加,即出现过拟合,考虑使用早期停止来终止训练过程。
5. 进行实验和记录
- 实验记录:记录每次实验的配置、训练过程和结果,以便比较不同配置的效果,找出最佳实践。
- 逐步调整:一次只调整一个参数,这样可以更清楚地看到每个变更对模型性能的影响。
如果在调整以上方面后模型性能仍未改善,可能需要回到数据集和任务定义上来,重新审视数据集的质量和适用性,或考虑是否需要更多的数据或不同类型的数据来改进模型。
如果还有问题,欢迎继续交流探讨 ~
问题2:结果输出为一些重复的标点符号和数字
问题描述
题外话:如果方便的话,除了报错截图,还可以私信,把输出复制给我
(因为有些之前也没遇到过,方便百度、问gpt哈哈)
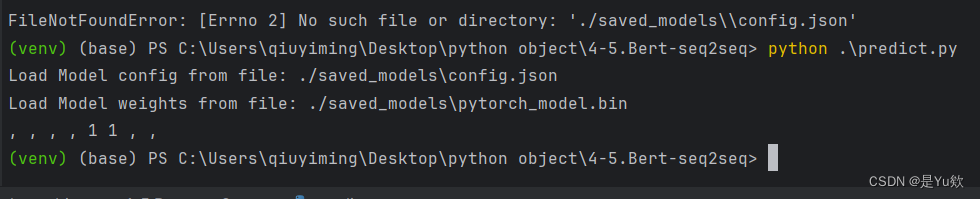
请教一下bert中文文本摘要的代码,我copy运行出来了,但是它是这样的
(venv) (base) Ps C:\UserslgiuyiminglDesktoplpython object\4-5.Bert-seg2seg> python ,\predict.py
Load Model config from file: /saved_models\config.json
Load Model weights from file: ./saved_models\pytorch_model.bin
,,,,1 1 ,,
一些建议
出现这种情况可能有几个原因,导致在运行BERT中文文本摘要代码时只得到了一些重复的标点符号和数字。
这里提供几个可能的解决方案和检查点,希望能帮助解决问题。
1. 检查模型输入
- 确保输入数据格式正确,且已经按照模型要求进行了适当的预处理。例如,文本是否已经正确分词,是否添加了必要的特殊标记(如CLS、SEP等)。
- 确认输入的文本不是空的或仅包含标点符号。
2. 检查预训练模型和权重
- 确认您加载的预训练模型和权重文件是完整的,没有损坏,且与您的任务相匹配。损坏的模型文件或不匹配的模型权重可能导致输出异常。
- 如果可能,尝试重新下载或使用不同的预训练模型进行测试。
3. 检查模型配置
- 查看
config.json文件,确认模型配置(比如词汇表大小、隐藏层维度等)是否与预训练模型一致。 - 确认模型配置是否适合您的特定任务,比如文本摘要。
4. 调试代码
- 在
predict.py中添加打印语句,以便在模型推理过程中观察输入数据、模型输出以及任何中间变量的状态。这可以帮助您确定问题发生的具体位置。 - 检查是否有任何数据处理或模型输出处理的步骤被错误实现或遗漏。
5. 代码和数据问题
- 如果您是从网络上复制的代码,可能存在代码的版本不兼容或依赖库版本问题。确认您的环境与原代码的环境设置相匹配。
- 确认输入数据的质量。如果输入数据不适合模型或存在问题,可能会导致输出结果异常。
6. 运行示例数据
- 尝试使用原作者提供的示例数据或已知能正常工作的数据运行模型,以确定问题是出在数据还是代码上。
7. 查找错误信息
- 如果程序产生了任何错误信息或警告,请仔细阅读这些信息,它们可能会提供问题的线索。
如果还有问题,欢迎继续交流探讨 ~