手把手写深度学习(0):专栏文章导航
前言:训练自己的视频扩散模型的第一步就是准备数据集,而且这个数据集是text-video或者image-video的多模态数据集,这篇博客手把手教读者如何写一个这样扩散模型的的Video DataLoader。
目录
准备工作
下载数据集
视频数据打标签
代码讲解
纯视频文件夹+txt描述prompt 读取方式
CSV描述文件读取方式
准备工作
下载数据集
一般会去下载webvid数据集,但是这个数据集非常大,如果读者不做预训练的话不建议下载。
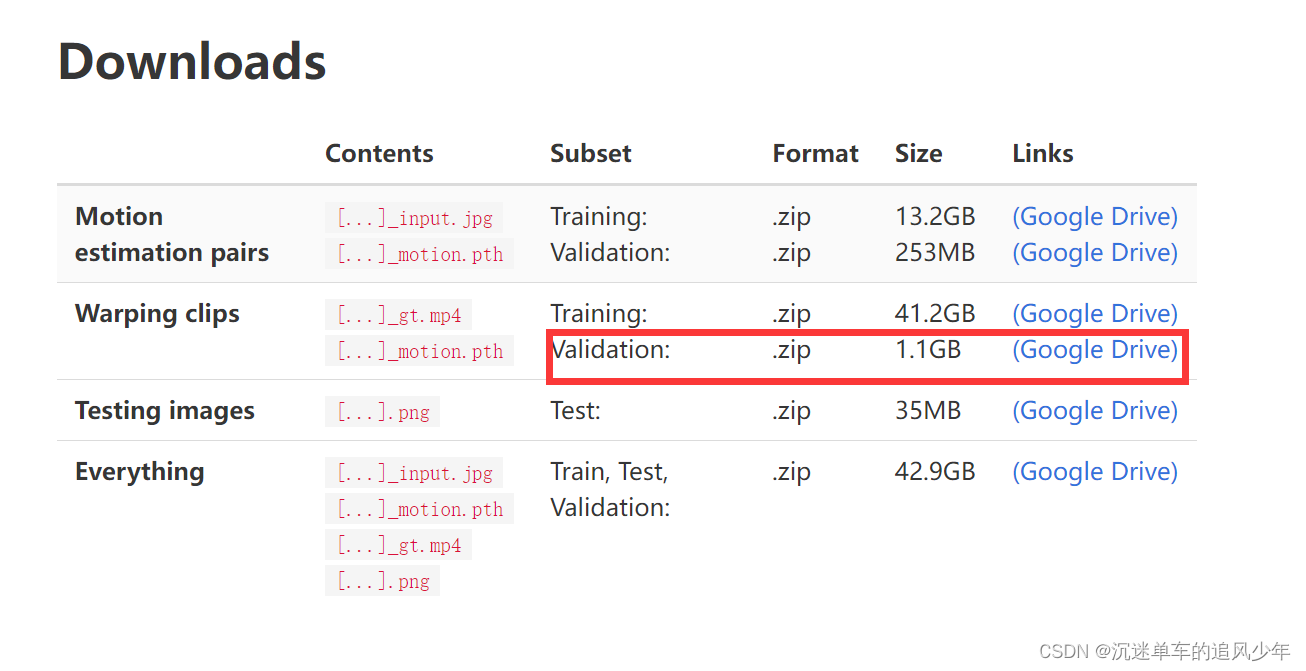
《Animating Pictures with Eulerian Motion Fields》提供了一个比较小的测试数据集:Animating Pictures with Eulerian Motion Fields
大概一个GB左右,谷歌云盘的链接如下:
https://drive.google.com/file/d/1-MKuNxO1mjopgY6UoEVGDVt5I_QvVeDn/view
下载之后的.pth文件我们暂时不用管,可以先删除掉,只保留.mp4文件。
视频数据打标签
很多数据集是没有一个比较好的文字描述的,如果我们要训练text-to-video的任务,第一步要做的事情是对视频数据打上文字标签。
如果有,那么就算了,主打一个淘气(不是)
还是下一讲专门讲一下如何用V-BLIP给视频数据打上text标签吧
代码讲解
纯视频文件夹+txt描述prompt 读取方式
第一个DataLoader只需要输入视频的文件夹路径,prompt要么是全部指定成相同的(那肯定不行),要么从同名的txt文件中读取:
if os.path.exists(self.video_files[index].replace(".mp4", ".txt")):with open(self.video_files[index].replace(".mp4", ".txt"), "r") as f:prompt = f.read()else:prompt = self.fallback_prompt注意这里的text我们直接用预训练的tokenizer编码了,如果不想要的话也可以把这里注释掉:
def get_prompt_ids(self, prompt):return self.tokenizer(prompt,truncation=True,padding="max_length",max_length=self.tokenizer.model_max_length,return_tensors="pt",).input_ids获取视频的部分需要特别注意的是,要把"f h w c"转换成"f c h w":
video = rearrange(video, "f h w c -> f c h w")完整代码如下:
class VideoFolderDataset(Dataset):def __init__(self,tokenizer=None,width: int = 256,height: int = 256,n_sample_frames: int = 16,fps: int = 8,path: str = "./data",fallback_prompt: str = "",use_bucketing: bool = False,**kwargs):self.tokenizer = tokenizerself.use_bucketing = use_bucketingself.fallback_prompt = fallback_promptself.video_files = glob(f"{path}/*.mp4")self.width = widthself.height = heightself.n_sample_frames = n_sample_framesself.fps = fpsdef get_frame_buckets(self, vr):h, w, c = vr[0].shape width, height = sensible_buckets(self.width, self.height, w, h)resize = T.transforms.Resize((height, width), antialias=True)return resizedef get_frame_batch(self, vr, resize=None):n_sample_frames = self.n_sample_framesnative_fps = vr.get_avg_fps()every_nth_frame = max(1, round(native_fps / self.fps))every_nth_frame = min(len(vr), every_nth_frame)effective_length = len(vr) // every_nth_frameif effective_length < n_sample_frames:n_sample_frames = effective_lengtheffective_idx = random.randint(0, (effective_length - n_sample_frames))idxs = every_nth_frame * np.arange(effective_idx, effective_idx + n_sample_frames)video = vr.get_batch(idxs)video = rearrange(video, "f h w c -> f c h w")if resize is not None: video = resize(video)return video, vrdef process_video_wrapper(self, vid_path):video, vr = process_video(vid_path,self.use_bucketing,self.width, self.height, self.get_frame_buckets, self.get_frame_batch)return video, vrdef get_prompt_ids(self, prompt):return self.tokenizer(prompt,truncation=True,padding="max_length",max_length=self.tokenizer.model_max_length,return_tensors="pt",).input_ids@staticmethoddef __getname__(): return 'folder'def __len__(self):return len(self.video_files)def __getitem__(self, index):video, _ = self.process_video_wrapper(self.video_files[index])if os.path.exists(self.video_files[index].replace(".mp4", ".txt")):with open(self.video_files[index].replace(".mp4", ".txt"), "r") as f:prompt = f.read()else:prompt = self.fallback_promptprompt_ids = self.get_prompt_ids(prompt)return {"pixel_values": normalize_input(video[0]), "prompt_ids": prompt_ids, "text_prompt": prompt, 'dataset': self.__getname__()}
CSV描述文件读取方式
这种方法每次都要打开一个txt文件去读取prompt,很不方便。而且如果读取的量级大了之后IO的开销会很大!
所以建议使用CSV方式的读取,CSV文件中存放着video-prompt的对应关系,样例如下:
video_path,prompt
...
video_path建议写成绝对路径,这样更方便读取。
完整代码如下:
class VideoCSVDataset(Dataset):def __init__(self,tokenizer=None,width: int = 256,height: int = 256,n_sample_frames: int = 16,fps: int = 8,csv_path: str = "./data",use_bucketing: bool = False,**kwargs):self.tokenizer = tokenizerself.use_bucketing = use_bucketingif not os.path.exists(csv_path):raise FileNotFoundError(f"The csv path does not exist: {csv_path}")self.csv_data = pd.read_csv(csv_path)self.width = widthself.height = heightself.n_sample_frames = n_sample_framesself.fps = fpsdef get_frame_buckets(self, vr):h, w, c = vr[0].shape width, height = sensible_buckets(self.width, self.height, w, h)resize = T.transforms.Resize((height, width), antialias=True)return resizedef get_frame_batch(self, vr, resize=None):n_sample_frames = self.n_sample_framesnative_fps = vr.get_avg_fps()every_nth_frame = max(1, round(native_fps / self.fps))every_nth_frame = min(len(vr), every_nth_frame)effective_length = len(vr) // every_nth_frameif effective_length < n_sample_frames:n_sample_frames = effective_lengtheffective_idx = random.randint(0, (effective_length - n_sample_frames))idxs = every_nth_frame * np.arange(effective_idx, effective_idx + n_sample_frames)video = vr.get_batch(idxs)video = rearrange(video, "f h w c -> f c h w")if resize is not None: video = resize(video)return video, vrdef process_video_wrapper(self, vid_path):video, vr = process_video(vid_path,self.use_bucketing,self.width, self.height, self.get_frame_buckets, self.get_frame_batch)return video, vrdef get_prompt_ids(self, prompt):return self.tokenizer(prompt,truncation=True,padding="max_length",max_length=self.tokenizer.model_max_length,return_tensors="pt",).input_ids@staticmethoddef __getname__(): return 'csv'def __len__(self):return len(self.csv_data)def __getitem__(self, index):print(self.csv_data.iloc[index])video_path, prompt = self.csv_data.iloc[index]video, _ = self.process_video_wrapper(video_path)prompt_ids = self.get_prompt_ids(prompt)return {"pixel_values": normalize_input(video[0]), "prompt_ids": prompt_ids, "text_prompt": prompt, 'dataset': self.__getname__()}