机器学习模型—随机森林
随机森林(Random Forest)是由斯坦福大学教授Tin Kam Ho在1995年提出的一种组合学习模型。它可以用于分类和回归任务,并在很多现实世界的问题中表现出优异的性能。
随机森林本质上是通过构建多颗决策树,然后将单个树的预测结果进行组合,从而获得更加准确可靠的最终预测值。它不仅易于参数调优和训练,而且对数据的缺失值也有较强的鲁棒性
随机森林回归是一种用于预测数值的多功能机器学习技术。它结合了多个决策树的预测,以减少过度拟合并提高准确性。Python 的机器学习库可以轻松实现和优化这种方法。
集成学习是一种机器学习技术,它结合多个模型的预测来创建更准确、更稳定的预测。它是一种利用多个模型的集体智慧来提高学习系统整体性能的方法。随机森林也是集成学习的一种
随机森林的工作原理
随机森林是一种集成学习方法,它结合了多个决策树的预测以产生更准确和稳定的预测。它是一种监督学习算法,可用于分类和回归任务。
每个决策树都有很高的方差,但是当我们并行组合所有决策树时,所得方差很低,因为每个决策树都在特定样本数据上得到了完美的训练,因此输出不依赖于一个决策树,而是依赖于多个决策树。决策树。在分类问题的情况下,最终输出是通过使用多数投票分类器获得的。在回归问题的情况下,最终输出是所有输出的平均值。这部分称为Aggregating。
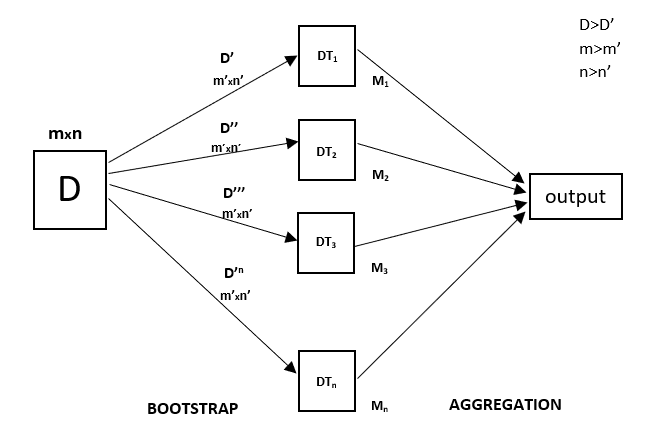
算法流程
- 从原始数据中通过有放回抽样获得N个训练集 这一步就是我们所说的bagging(bootstrap aggr