原文地址:Using A Large Language Model For Entity Extraction
LLM 能否比传统 NLP 方法更好地提取实体?
2022 年 7 月 12 日
Large Language Models for Generative Information Extraction: A Survey
实体简介
使用Co:here大型语言模型。
实体可以被视为句子或用户输入中的名词。在对话设计中,有两种实体提取方法......
第一个是更基本的、顺序的槽填充过程。聊天机器人会逐个提示用户输入每个实体,并且用户需要遵循这种高度结构化的方法。
例如,在航班预订的情况下,机器人通过以下方式提示用户捕获实体。

像AWS Lex V2这样的框架在很大程度上具有槽填充方法,其中界面不是对话式的且非结构化的,并且框架以槽填充为中心。
其次,更复杂的方法是设计实体类型的复合和上下文方法。就Microsoft LUIS而言,机器学习嵌套实体正在被开创;您可以在此处阅读有关嵌套实体的更多信息。
这种方法的一个特点是聊天机器人彻底挖掘用户输入的实体。聊天机器人不会重新提示用户输入用户已提供的任何输入。用户也不必遵守预定义的结构并格式化他们的输入。
下图说明了这种方法,用户输入包含从用户话语中根据上下文提取的复合实体。
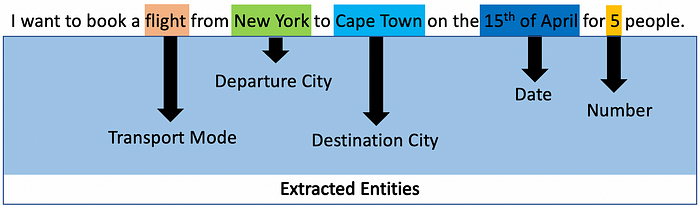
Gartner 领导者还倾向于拥有与特定意图相关的实体。因此,一旦检测到意图,NLU 就会拥有与所识别的意图相关的较小的预期可能实体池。
三种类型的实体
有人可能会说存在三种实体提取方法……

NLU 定义的实体
这些实体是自定义实体,主要在聊天机器人开发框架内定义。详细了解聊天机器人中实体结构的出现,以及为什么它对于准确和高效地捕获非结构化数据很重要。
命名实体
在NLP中,命名实体是现实世界的对象,例如人、地点、公司、产品等。命名实体不需要训练或任何定义命名实体的过程(在大多数情况下)NLP/NLU系统会自动检测它。唯一的障碍是特定人类语言中命名实体功能的可用性。
这些命名实体可以是抽象的,也可以是实际存在的。以下是Riva NLU检测到的命名实体的示例。
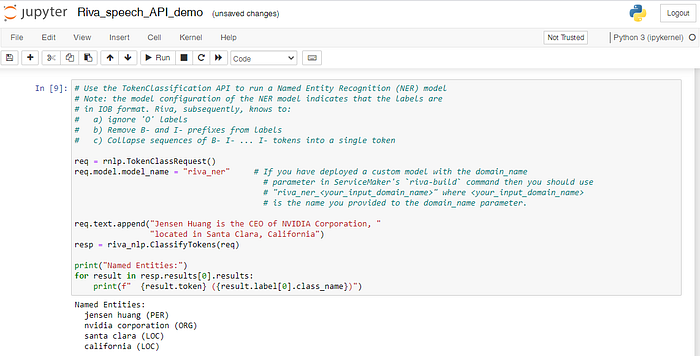
Jupyter Notebook 中的命名实体代码块
输入示例:
Jensen Huang is the CEO of NVIDIA Corporation, located in Santa Clara, California.示例输出:
Named Entities:jensen huang (PER)nvidia corporation (ORG)santa clara (LOC)california (LOC)spaCy还有一个非常高效的命名实体检测系统,该系统也可以分配标签。默认模型标识大量命名和数字实体。这可以包括地点、公司、产品等。
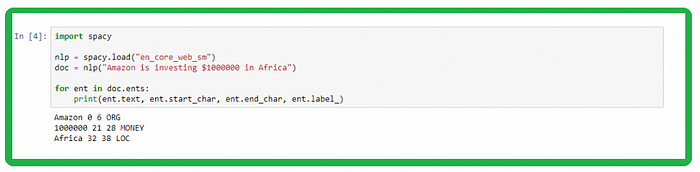
检测到的每个命名实体的详细信息
- 文本:原始实体文本。
- 开始:文档中实体开始的索引
- End:文档中实体结尾的索引
- label:实体标签,即类型
返回大型语言模型
在我们讨论 LLM 和实体之前……LLM 的功能可以分为两个广泛的实现:生成和表示。
在本文中,您可以关于如何使用生成和表示模型来引导聊天机器人,利用语义搜索、语言生成和我喜欢称之为意图文档的概念。
表示语言模型用于分类和语义搜索。
使用 LLM 进行实体提取
对于实体提取,我们将使用Co:here的生成语言模型,该模型可用于补全、文本摘要和实体提取。
使用像Co:here这样的大型语言模型来训练模型和提取实体有以下几个方面的不同:
- 几次训练方法需要少量的训练数据。
- 差异很大的数据的准确性令人震惊。
- 具有多个训练样本和多个实体的管理和环境可能会变得复杂。图形管理工作室环境将是通过无代码界面直观地管理实体的理想选择。
- 我没有测试使用复合实体、每个话语或句子多个实体的实体提取。该系统在检测多词实体方面表现出色,而传统的实体提取经常无法做到这一点。
- 在某些情况下,提取意图的话语相当长,这使得LLMs的表现更加令人印象深刻。
- 这种类型的提取很有趣,因为它不只是盲目地看文本。该模型在预训练过程中获取了电影信息,这有助于它仅从几个示例中理解任务。
下面是使用的训练数据,JSON 格式:
movie_examples = [
("Deadpool 2", "Deadpool 2 | Official HD Deadpool's \"Wet on Wet\" Teaser | 2018"),
("none", "Jordan Peele Just Became the First Black Writer-Director With a $100M Movie Debut"),
("Joker", "Joker Officially Rated “R”"),
("Free Guy", "Ryan Reynolds’ 'Free Guy' Receives July 3, 2020 Release Date - About a bank teller stuck in his routine that discovers he’s an NPC character in brutal open world game."),
("none", "James Cameron congratulates Kevin Feige and Marvel!"),
("Guardians of the Galaxy", "The Cast of Guardians of the Galaxy release statement on James Gunn"),
("Inception", "Inception is a movie about dreams and levels in dreams."),
]接下来我们获取数据进行分析:
['Hayao Miyazaki Got So Bored with Retirement He Started Directing Again ‘in Order to Live’',
"First poster for Pixar's Luca",
'New images from Space Jam: A New Legacy',
'Official Poster for "Sonic the Hedgehog 2"',
'Ng Man Tat, legendary HK actor and frequent collborator of Stephen Chow (Shaolin Soccer, God of Gambler) died at 70',
'Zack Snyder’s Justice League has officially been Rated R for for violence and some language',
'HBOMax and Disney+ NEED to improve their apps if they want to compete with Netflix.',
'I want a sequel to Rat Race where John Cleese’s character dies and invites everyone from the first film to his funeral, BUT, he’s secretly set up a Rat Maze to trap them all in. A sort of post-mortem revenge on them for donating all his wealth to charity.',
"'Trainspotting' at 25: How an Indie Film About Heroin Became a Feel-Good Classic",
'‘Avatar: The Last Airbender’ Franchise To Expand With Launch Of Nickelodeon’s Avatar Studios, Animated Theatrical Film To Start Production Later This Year']结果如下:
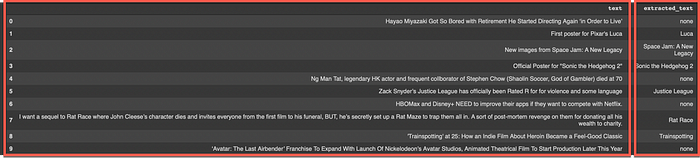
- 该模型十分之九正确。
- 错过了该盘中的第四(4)号。
- 需要进行实验来检测沿途的边缘情况。例如,如果有人提到两个电影名称怎么办?我们在提示中添加的解决这些情况的示例越多,结果就越有弹性。
结论
通过笔记本的一些观察:
- 少样本训练方法确实为实体提取提供了更灵活、更令人兴奋的前景。
- 聊天机器人可以在某种程度上进行引导,并且可以将实体添加到我在这里讨论的意图文档方法中。
- 仅通过几个训练示例,似乎确实涵盖了更广泛的潜在用户话语基础。
- 我看到一个新兴的用例,其中 LLM 实体提取可以作为扩展或引导实体提取的途径在聊天机器人中实现。这是我想在不久的将来探索的事情。
- 最后,迫切需要一种无代码工作室方法,用户可以通过该方法访问 LLM 功能、创建和提交训练数据以及构建实体提取功能。