作品展示:——word表格的关键词批量加粗

背景需求:
生成正确的19周周计划内容

每个教案里面的“重点提问:”“小结:”“过渡语:”都是加粗设置

但是由于提取的是“活动过程下面的的整段内容,所以的加粗字体进入新的模板后,都变成了宋体小4不加粗
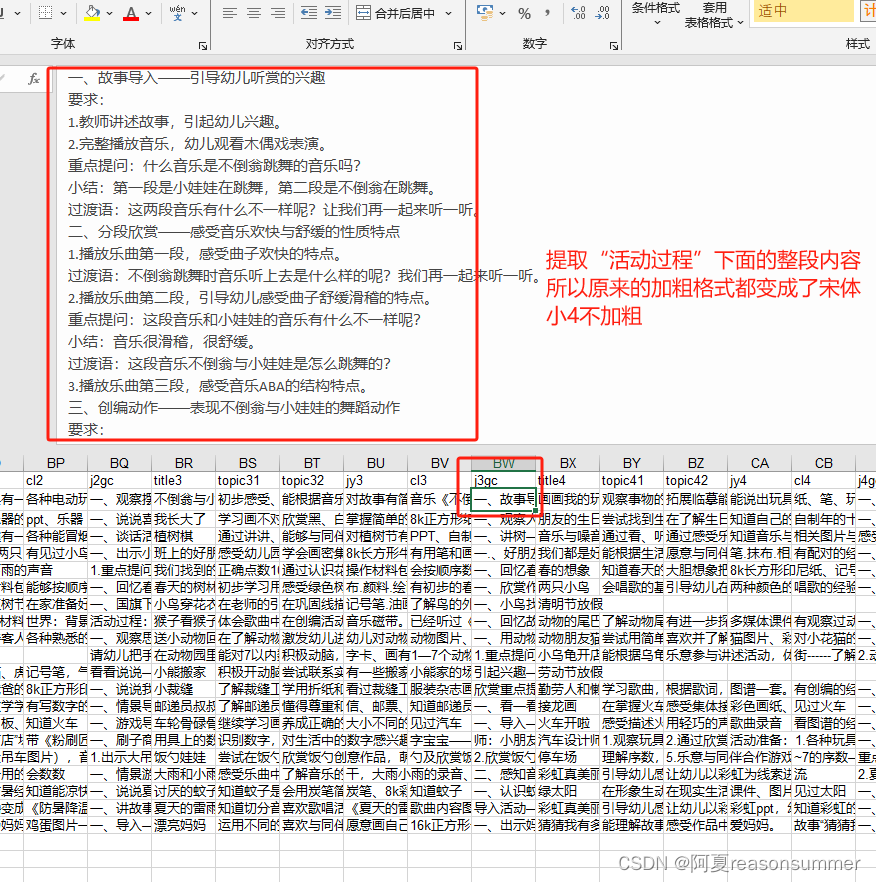

”重点提问“”小结“”过渡语“的数量很多,过去通过网络查询,我找到可以批量替换表格里的文字并加粗的代码,
【办公类-22-05】周计划系列(5)-Word关键词加粗(把所有“小结”“提问”的文字设置加粗)_word关键字加粗-CSDN博客文章浏览阅读179次。【办公类-22-05】周计划系列(5)-Word关键词加粗(把所有“小结”“提问”的文字设置加粗)_word关键字加粗https://blog.csdn.net/reasonsummer/article/details/130476685
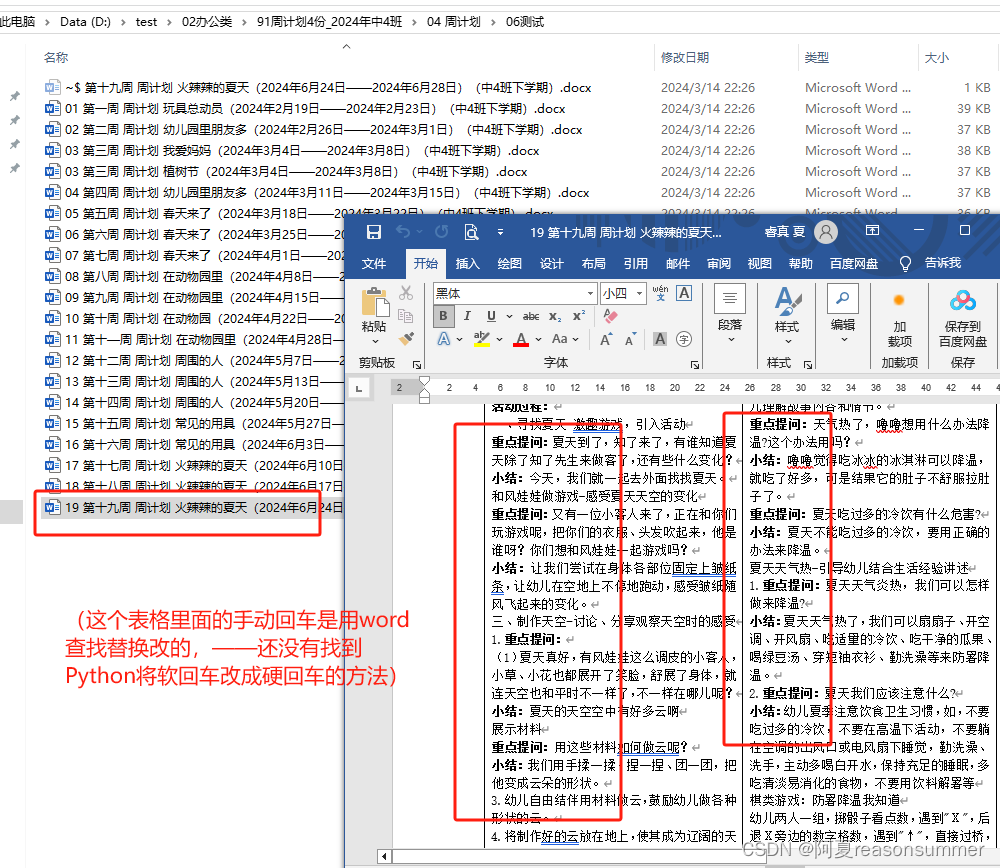
但是上学期实验后,发现它只是把docx段落文字加粗,不能把docx表格文字加粗,于是在Python批量导入生成新的周计划后,我只能是手动打开19份,然后用查找、替换、批量加粗,
问题:
1、手动容易遗漏:三组文字替换下来很费时间,而且有时候会遗漏某一篇,
2、无法满足重复生成:如果周计划内容有错误,就会再次Python一套内容,这样就要重复得打开19篇,批量替换加粗19*3次,实在太不方便了 。
设计思路
本次我在使用AI对话大师过程中,发现可以指定从”Word表格"提取文字,从word段落里加粗段落文字。
那么是否可以实现——Python 读取123文件下所有docx文件里面的表格文字,如果文字是“重点提问:”,就改成“重点提问:”加粗

同时,我发现有的教案内没有“重点提问”,而是“提问”,所以要先把“提问”改成“重点提问”,然后把“重点重点提问”改成“重点提问”

通过4个小时的反复测试,AI了57条,终于获得了我想要的结果
'''
docx教案里面的“重点提问”“过渡语”“小结”加粗
作者:AI对话大师、阿夏
时间:2024年3月14日
'''
import os
from docx import Document# 文件夹路
path=r'D:\test\02办公类\91周计划4份_2024年中4班\04 周计划'folder_path = path+r'\04合成新周计划'
new_path = path+r'\06测试'# 替换“提问”变成“重点提问”
for file_name in os.listdir(folder_path):if file_name.endswith(".docx"):file_path = os.path.join(folder_path, file_name)doc = Document(file_path)# 遍历所有表格并查找并修改内容for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:if "提问" in paragraph.text:for run in paragraph.runs:if "提问" in run.text:run.text = run.text.replace("提问", "重点提问")# 保存修改后的文档doc.save(os.path.join(new_path, file_name))# 替换“重点重点提问”变成“重点提问”
for file_name in os.listdir(new_path):if file_name.endswith(".docx"):file_path = os.path.join(new_path, file_name)doc = Document(file_path) for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:if "重点重点" in paragraph.text:for run in paragraph.runs:if "重点重点" in run.text:run.text = run.text.replace("重点重点", "重点")doc.save(os.path.join(new_path, file_name))# 把“重点提问”改成加粗
#
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Pt
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml# 包含中文状态冒号,英文状态冒号
# t=['重点提问:','重点提问:','小结:','小结:','过渡语:','过渡语:']# # 遍历文件夹下所有.docx文件
# # for i in t:
for file_name in os.listdir(new_path):if file_name.endswith(".docx"):file_path = os.path.join(new_path, file_name)doc = Document(file_path) for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:for run in paragraph.runs:if '重点提问:' in run.text:text = run.textindex = text.find('重点提问:')if index != -1:run.text = text[:index]new_run = paragraph.add_run('重点提问:')new_run.font.bold = Truenew_run = paragraph.add_run(text[index+len('重点提问:'):])new_run.bold = run.bolddoc.save(os.path.join(new_path, file_name))#

通过修改,让“重点提问”“小结”“过渡语”都批量加粗

全部代码:
'''
docx教案的表格里的“重点提问”“过渡语”“小结”加粗
作者:AI对话大师、阿夏
时间:2024年3月14日
'''
import os
from docx import Document
from docx.enum.text import WD_BREAK
from docx.oxml.ns import nsdeclsfrom docx.oxml import OxmlElement
from docx.oxml.ns import qn# 文件夹路
path=r'D:\test\02办公类\91周计划4份_2024年中4班\04 周计划'folder_path = path+r'\04合成新周计划'
new_path = path+r'\06测试'# print("-----0、手动换行符改成段落回车--------")
# import os,re
# from docx import Document
# from docx import Document
# from docx.oxml import OxmlElement
# from docx.oxml.ns import qn
# from docx.shared import Pt# # 遍历文件夹内所有docx文件
# for file_name in os.listdir(folder_path):
# if file_name.endswith('.docx'):
# file_path = os.path.join(folder_path, file_name)# # 读取docx文件
# doc = Document(file_path) # # 遍历文档中的所有表格
# for table in doc.tables:
# for row in table.rows:
# for cell in row.cells:
# # 获取单元格中的文本
# text = cell.text
# # 替换文本中的换行符为硬回车
# cell.text = text.replace('\n', '\r')# # 保存修改后的文档
# doc.save(os.path.join(new_path, file_name))print("-----1、替换'提问'变成'重点提问'--------")for file_name in os.listdir(folder_path):if file_name.endswith(".docx"):file_path = os.path.join(folder_path, file_name)doc = Document(file_path)# 遍历所有表格并查找并修改内容for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:if "提问" in paragraph.text:for run in paragraph.runs:if "提问" in run.text:run.text = run.text.replace("提问", "重点提问")# 保存修改后的文档doc.save(os.path.join(new_path, file_name))print("-----2、替换'重点重点提问'变成'重点提问'--------")
for file_name in os.listdir(new_path):if file_name.endswith(".docx"):file_path = os.path.join(new_path, file_name)doc = Document(file_path) for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:if "重点重点" in paragraph.text:for run in paragraph.runs:if "重点重点" in run.text:run.text = run.text.replace("重点重点", "重点")doc.save(os.path.join(new_path, file_name))print("-----3、把'重点提问、小结、过渡语'等内容改成加粗--------")
#
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import Pt
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml# 包含中文状态冒号,英文状态冒号
t=['重点提问:','重点提问:','小结:','小结:','过渡语:','过渡语:']# # 遍历文件夹下所有.docx文件
for content in t: for file_name in os.listdir(new_path):if file_name.endswith(".docx"):file_path = os.path.join(new_path, file_name)doc = Document(file_path) # 循环读取100次# for x in range(100):for table in doc.tables:for row in table.rows:for cell in row.cells:for paragraph in cell.paragraphs:for run in paragraph.runs:if content in run.text:text = run.textindex = text.find(content)if index != -1:run.text = text[:index]new_run = paragraph.add_run(content)new_run.font.bold = Truenew_run = paragraph.add_run(text[index+len(content):])new_run.bold = run.bold doc.save(os.path.join(new_path, file_name))