文章目录
- 产生背景
- 编程模型
- 统计词频案例
- 实现机制
- 容错机制
- Master的容错机制
- Worker的容错机制
产生背景

MapReduce是一种分布式数据处理模型和编程技术,由Google开发,旨在简化大规模数据集的处理。产生MapReduce的背景:
- 数据量的急剧增长:随着互联网的快速发展,产生的数据量急剧增加,传统的数据处理方法已经无法有效处理如此庞大的数据集。需要一种能够在数以千计的计算机上并行处理大数据的方法。
- 分布式计算需求增加:为了处理大规模数据集,需要将数据分布在多个计算节点上进行并行处理。这就要求有一种可靠的方法来协调这些节点之间的工作,处理节点间的通信,以及处理节点故障时的数据恢复。
- 简化并行计算:虽然分布式和并行计算技术已经存在,但它们往往需要开发者具有高度的专业知识。Google希望开发一种简单的编程模型,让开发者不需要深入了解分布式系统的底层细节,也能开发出高效的分布式应用。
- Google的实际需求:Google需要处理网页索引、搜索结果排序等涉及大量数据的任务。这些任务不仅数据量大,而且需要频繁更新。MapReduce的设计就是为了优化这些任务的处理效率,提高资源利用率和处理速度。
- MapReduce:封装并行处理、容错处理、本地化计算、负载均衡的细节,还提供简单而强大的接口,通过该接口可以把大尺度的计算自动地并发和分布执行,并具备较好的通用性。
编程模型
-
- MapReduce模型包含两个关键步骤:Map(映射)和Reduce(归约)。在Map阶段,输入数据被分成独立的小块,然后并行处理。在Reduce阶段,处理结果被汇总为最终结果。这种模型大大简化分布式计算的复杂性,使得程序员可以用较少的代码行数处理大量数据。
- MapReduce的成功推动了大数据和分布式计算技术的发展,Hadoop就是受其启发创建的一个开源框架,它允许使用简单的编程模型来处理大规模数据集。
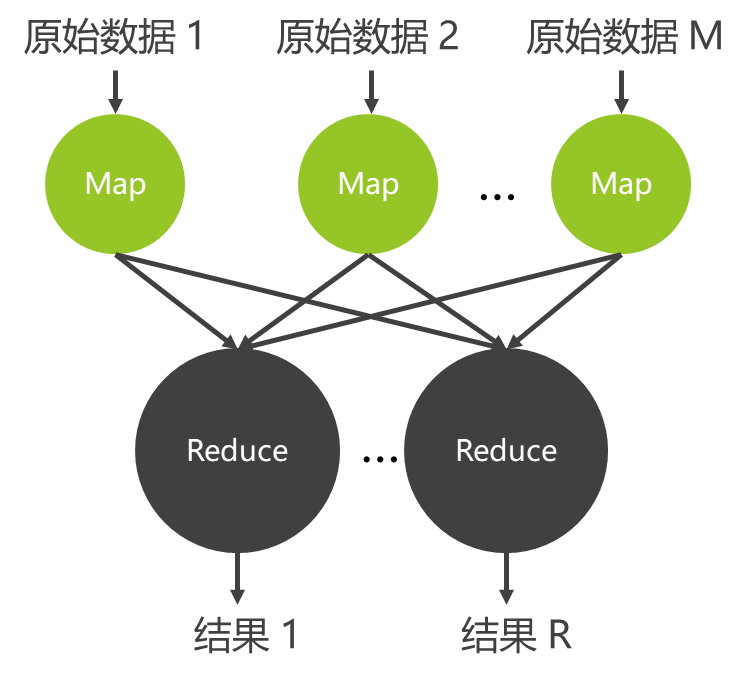
- Map函数——对一部分原始数据进行指定的操作。每个Map操作都针对不同的原始数据,因此Map与Map之间是互相独立的,这使得它们可以充分并行化
- Reduce操作——对每个Map所产生的一部分中间结果进行合并操作,每个Reduce所处理的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的结果集。
Map: (in_key, in_value) -> {(keyj, valuej) | j = 1…k}
Reduce: (key, [value1,…,valuem]) -> (key, final_value)
- Map输入参数:in_key和in_value,它指明了Map需要处理的原始数据
- Map输出结果:一组
<key,value>对,这是经过Map操作后所产生的中间结果 - Reduce输入参数:(key,[value1,…,valuem])
- Reduce工作:对这些对应相同key的value值进行归并处理
- Reduce输出结果:(key, final_value),所有Reduce的结果并在一起就是最终结果
统计词频案例
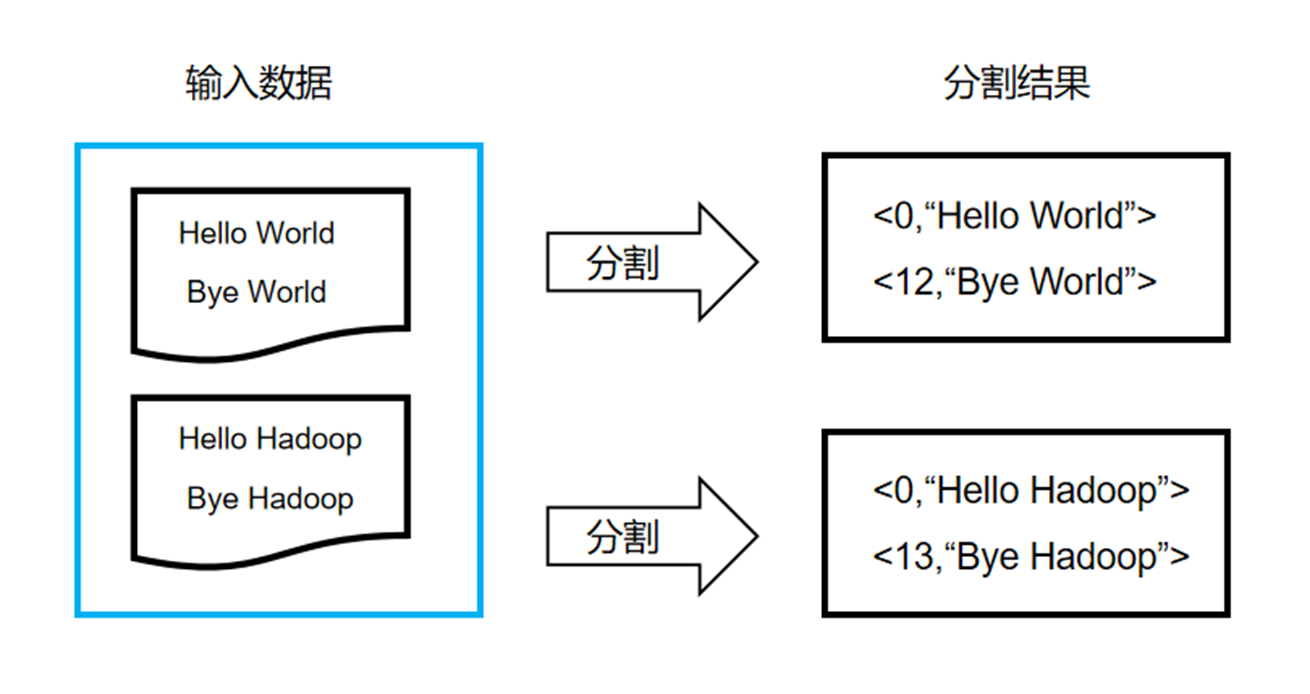
- Mapreduce首先把数据切片,切成若干块,然后每一块启动一个map函数进行处理;
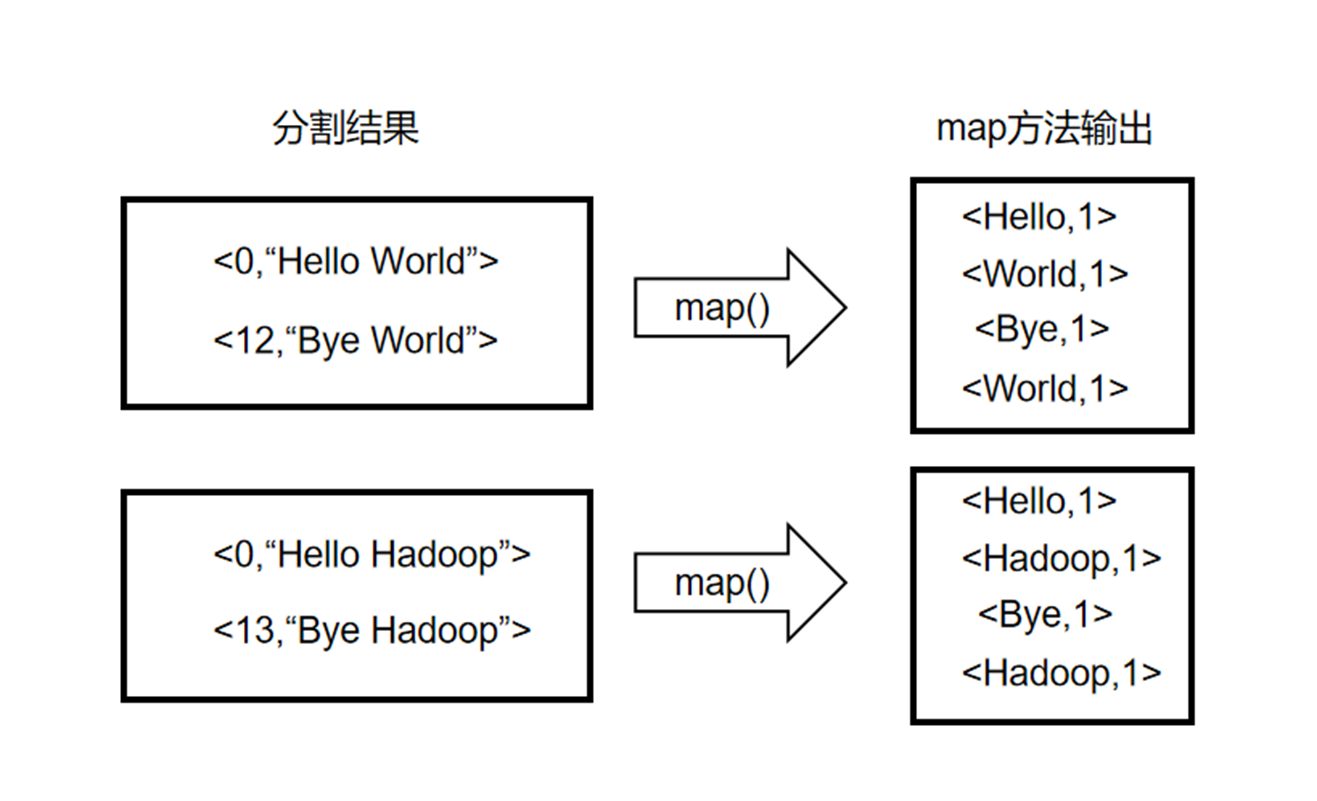
- map函数接受的 键是文件名,值是文件的内容 键是文件名,值是文件的内容 键是文件名,值是文件的内容,键值对
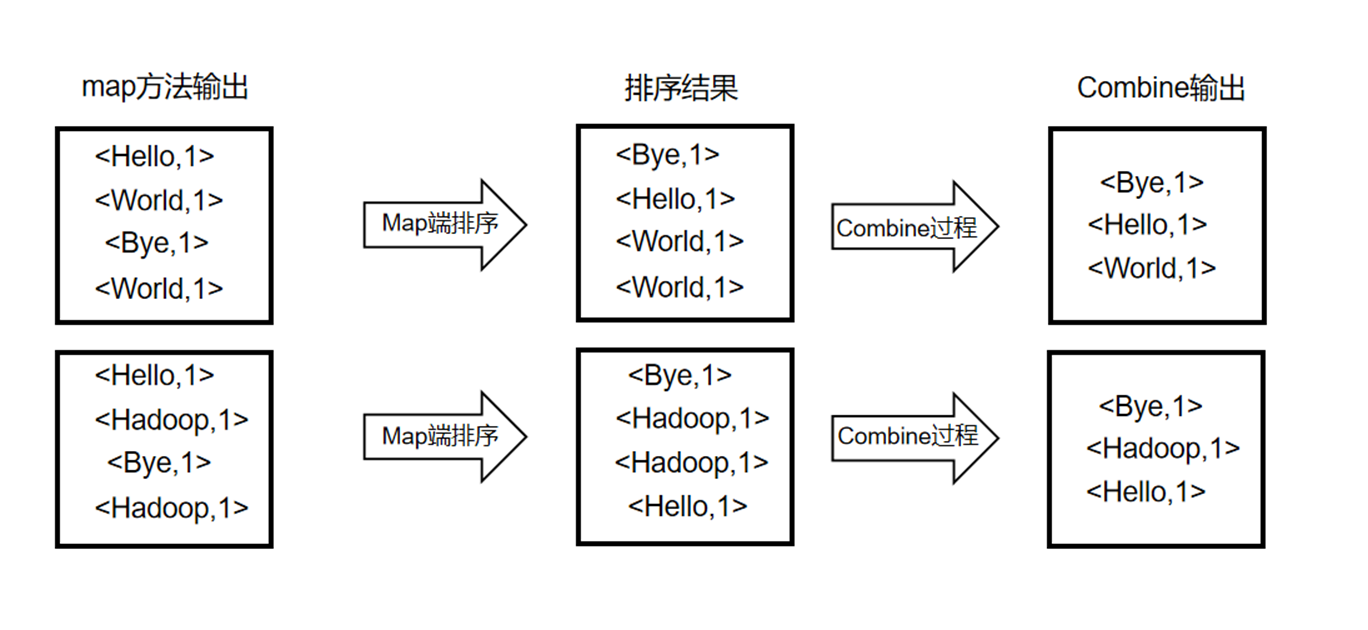
<文件名, 文件内容>;map逐个遍历单词,每遇到一个单词w,就产生一个中间键值对<w, "1">,这表示又找到了一个单词w; - 每一个map所产生的中间键值对,要再进行分区,即将这些中间键值对再切成若干块,每一块交给一个reduce函数进行处理;
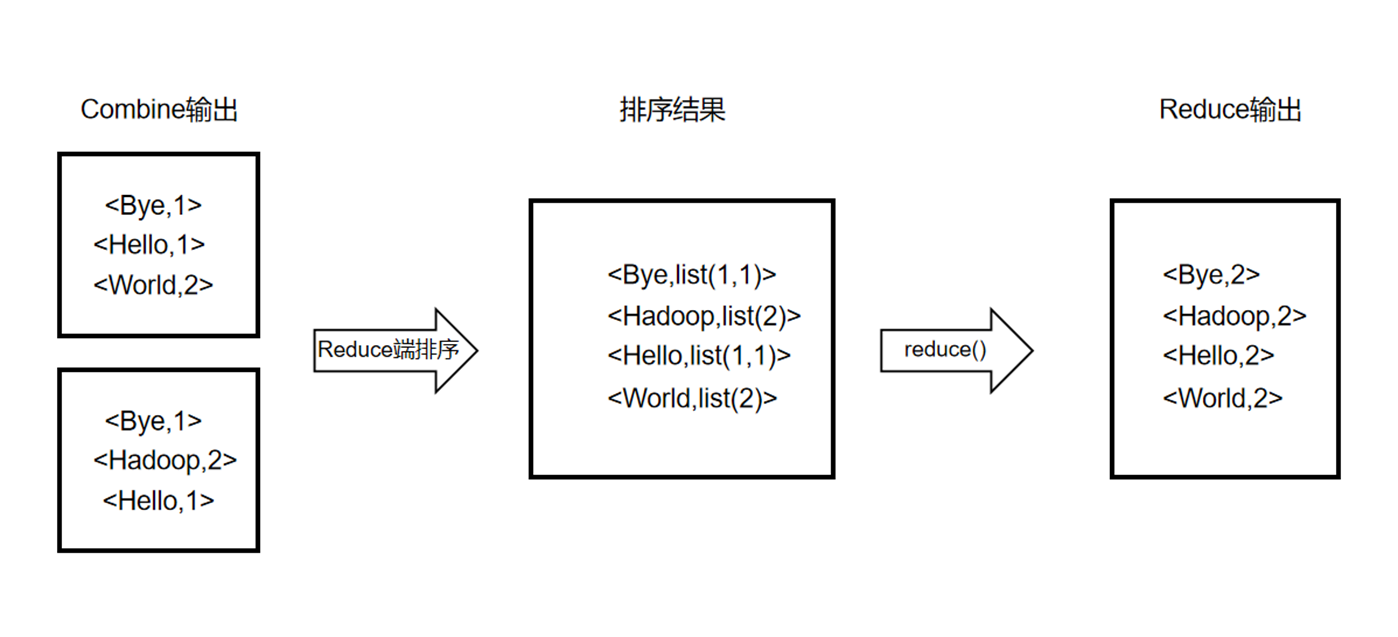
- MapReduce将键相同(都是单词w)的键值对传给reduce函数,这样reduce函数接受的键就是单词w,值是一串"1",个数等于键为w的键值对的个数,然后将这些“1”累加就得到单词w的出现次数。
实现机制
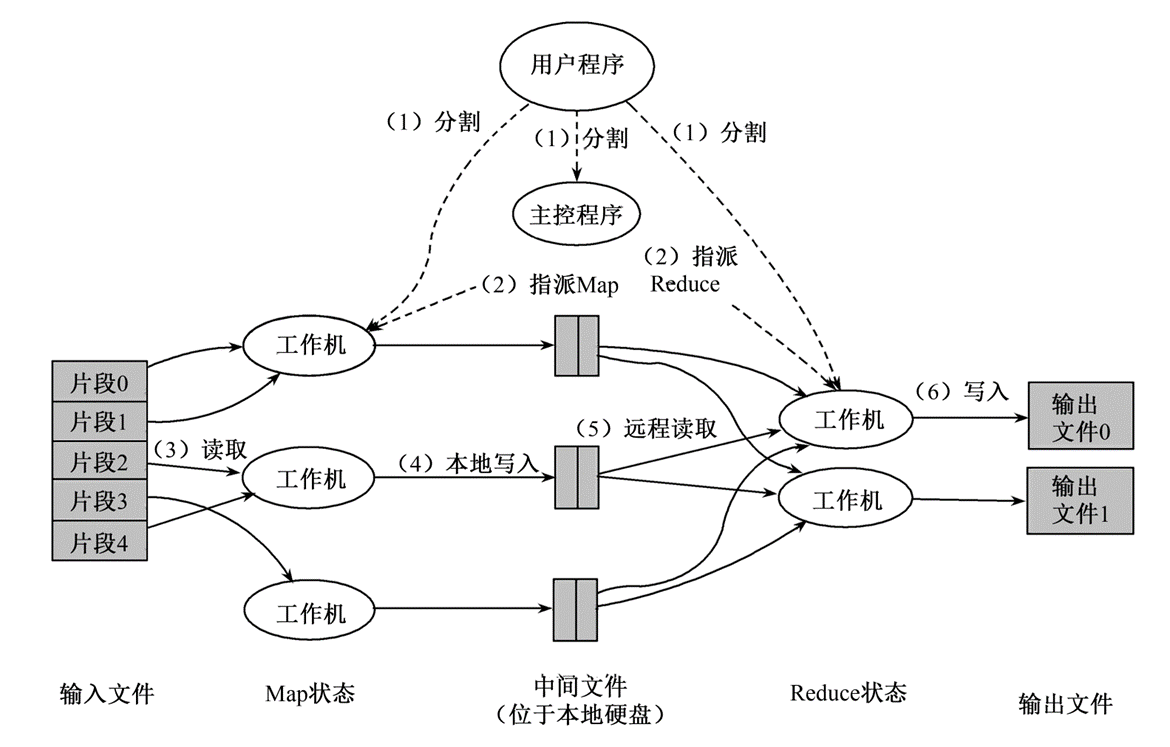
MapReduce的实现机制过程:
- 首先,MapReduce将输入文件切分成多个块,并分配给不同的Map任务进行处理。
- 每个Map任务读取并处理与其相关的输入块,生成中间结果,并将这些结果缓存到内存中。
- 定期将缓存的中间结果写入本地硬盘,并根据分区函数将数据分成多个区。
- 当Master通知执行Reduce的Worker时,它调用远程过程,从Map Worker的本地硬盘上读取缓存的中间数据。
- Reduce Worker根据每个唯一的中间键遍历排序后的中间数据,并将键和相关的中间结果值集合传递给用户定义的Reduce函数。
- 当所有的Map任务和Reduce任务都完成时,Master激活用户程序,最终将所有Reduce任务的结果连接起来形成完整的结果集。
容错机制
- 由于MapReduce在成百上千台机器上处理海量数据,所以容错机制是不可或缺的。
- MapReduce中的容错机制是确保系统在处理海量数据时能够处理故障和失效情况的重要组成部分。
Master的容错机制
- Master会周期性地设置检查点并导出数据,以便在任务失效时进行恢复和重新执行。
- 如果Master失效,整个MapReduce程序将终止并重新开始。
- Master会定期发送ping命令给Worker,如果没有Worker的应答,则认为Worker失效,并将任务调度到其他Worker上重新执行。
Worker的容错机制
- 如果Worker失效,Master会终止对该Worker的任务调度,并将任务调度到其他Worker上重新执行。
- 总的来说,MapReduce通过重新执行失效的地方来实现容错。Master和Worker之间的通信和检查机制确保系统在面对故障和失效时的可靠性和稳定性。