文章目录
- 一、ON DUPLICATE KEY UPDATE的介绍
- 二、ON DUPLICATE KEY UPDATE的使用
- 2.1、案例一:根据主键id进行更新
- 2.2、案例二:根据唯一索引进行更新(常用)
- 2.3、案例三:没有主键或唯一键字段值相同就插入
- 2.4、案例四:主键与唯一键字段同时存在
- 三、ON DUPLICATE KEY UPDATE的注意事项
- 3.1、on dupdate key update之后values的使用事项
- 3.2、对values使用判断
- 3.3、唯一索引大小写敏感问题
- 四、ON DUPLICATE KEY UPDATE与mybatis联合使用
- 4.1、写法一:与values()联合使用
- 4.2、写法二:使用#{}
- 五、ON DUPLICATE KEY UPDATE的缺点及坑
- 5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续
- 5.2、death lock死锁
有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。这个时候就可以用到ON DUPLICATE KEY UPDATE这个sql语句了。
以下内容基于本地windows环境mysql:8.0.34进行讲解。
一、ON DUPLICATE KEY UPDATE的介绍
基本用法:ON DUPLICATE KEY UPDATE是一种MySQL的语法,它在插入新数据时,如果遇到唯一键冲突(即已存在相同的唯一键值),则会执行更新操作,而不是抛出异常或忽略该条数据。这个语法可以大大简化我们的代码,减少不必要的判断和查询操作。
用法总结
1:on duplicate key update 语句根据主键id或唯一键来判断当前插入是否已存在。
2:记录已存在时,只会更新on duplicate key update之后指定的字段。
3:如果同时传递了主键和唯一键,以主键为判断存在依据,唯一键字段内容可以被修改。
4:唯一键大小写敏感时,大小写不同的值被认为是两个值,执行插入。参见下文中的大小写敏感问题
二、ON DUPLICATE KEY UPDATE的使用
准备表结构及测试数据, 注意:name是唯一键
drop table if exists tbl_test;
create table tbl_test(id int primary key auto_increment,name varchar(30) unique not null,age int comment '年龄',address varchar(50) comment '住址',update_time datetime default null
) comment '测试表';insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('lisi',21,'武汉',now());
测试数据如下:
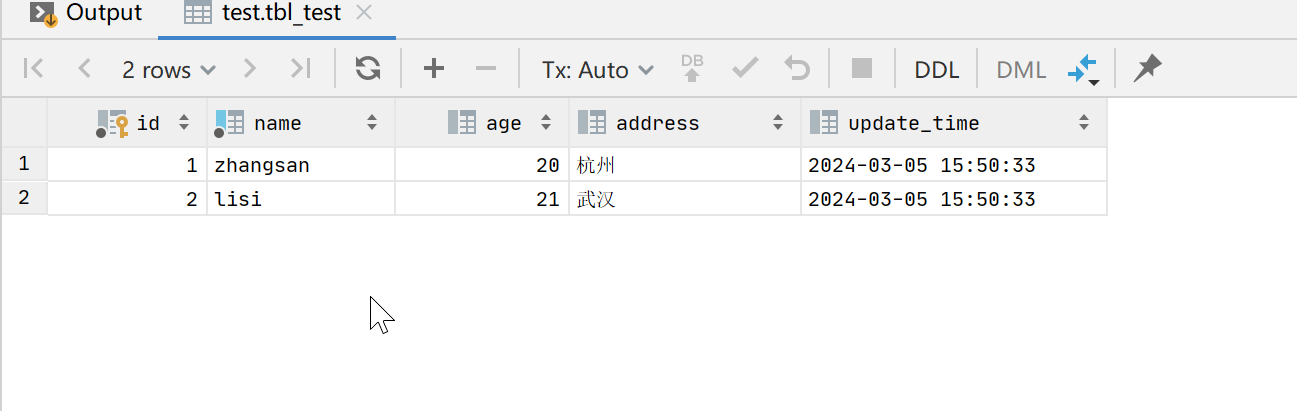
2.1、案例一:根据主键id进行更新
on dupdate key update 语句基本功能是:当表中没有原来记录时,就插入,有的话就更新。
如下sql:
insert into tbl_test(id,name,age,address,update_time) values(1,'zhangsan1',201,'杭州1','2024-03-05 15:59:35')
on duplicate key update
age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name
address = values(address),
update_time=now();
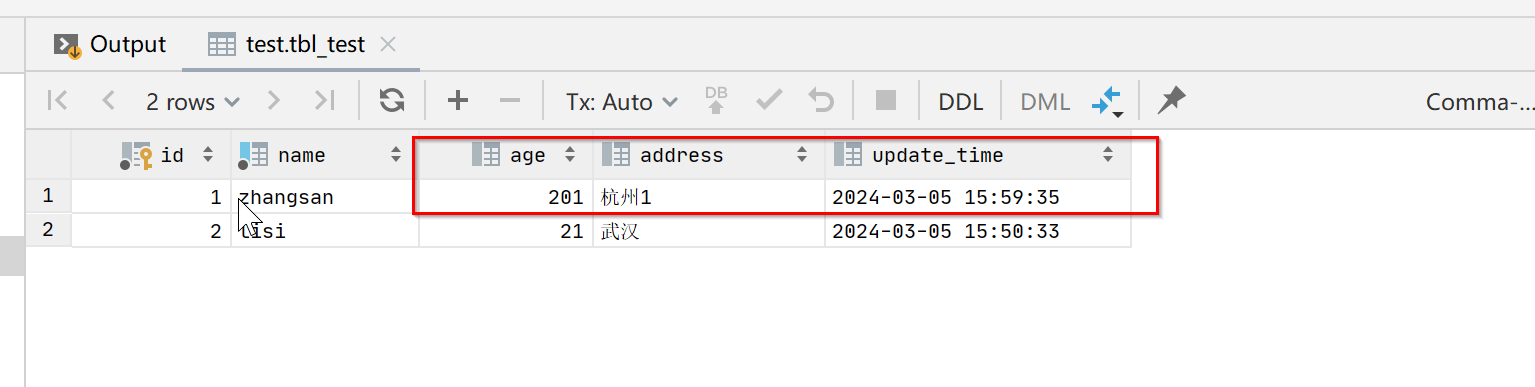
从执行结果可以看出,更新了id为1的age,address两个字段,而name字段没有修改生效。由此我们可以得出两个重要结论:
1:on duplicate key update 语句根据主键id来判断当前插入是否已存在。
2:已存在时,只会更新on duplicate key update之后限定的字段。
2.2、案例二:根据唯一索引进行更新(常用)
根据唯一索引进行更新是生产中比较常用的方式,因为id一般使用的是自增,很少会先把id查询出来,然后根据id进行更新。
如下sql:
insert into tbl_test(name,age,address) values('zhangsan',202,'杭州2')
on duplicate key update
age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name
address = values(address),
update_time=now();
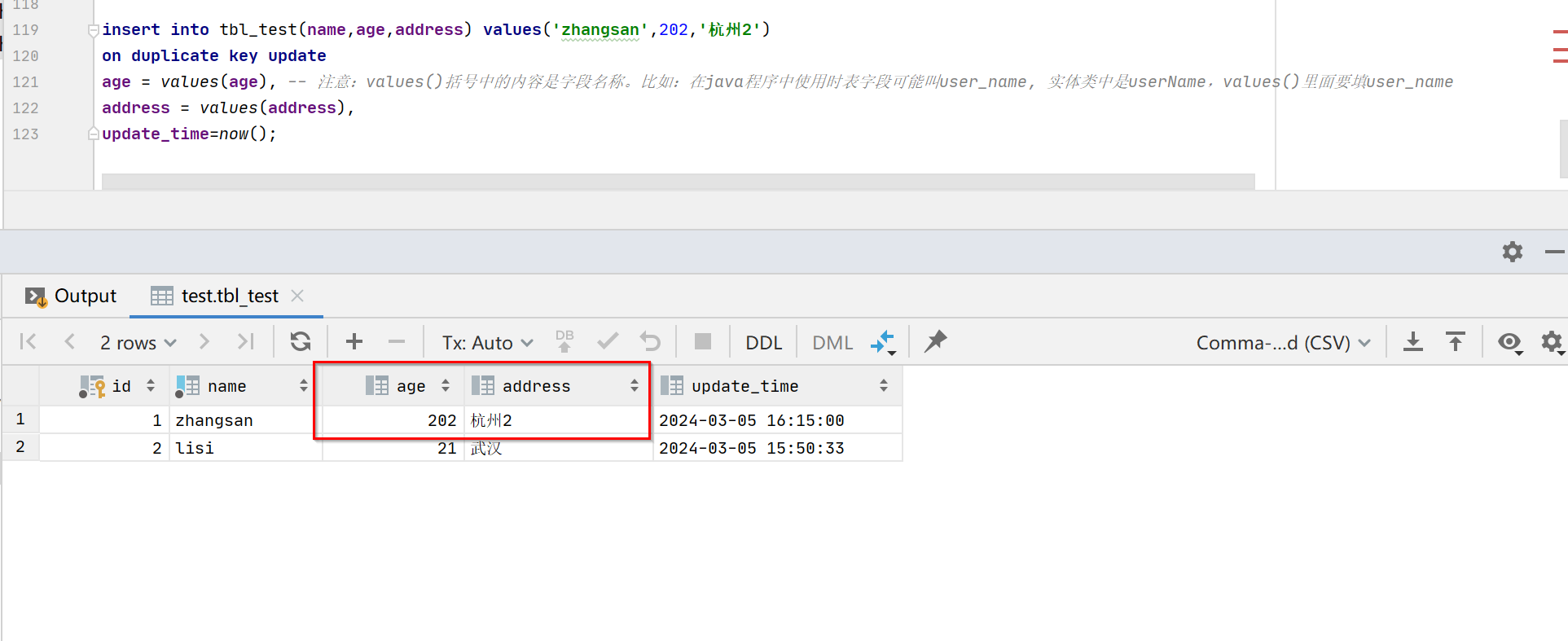
从执行结果看,这次没有传id,但是age,address字段仍然更新了。
由此可以得出另一个结论:
3:on duplicate key update 语句也可以根据唯一键来判断当前插入的记录是否已存在。
2.3、案例三:没有主键或唯一键字段值相同就插入
如下sql:
insert into tbl_test(name,age,address) values('zhangsan3',203,'杭州3')
on duplicate key update
age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name
address = values(address),
update_time=now();
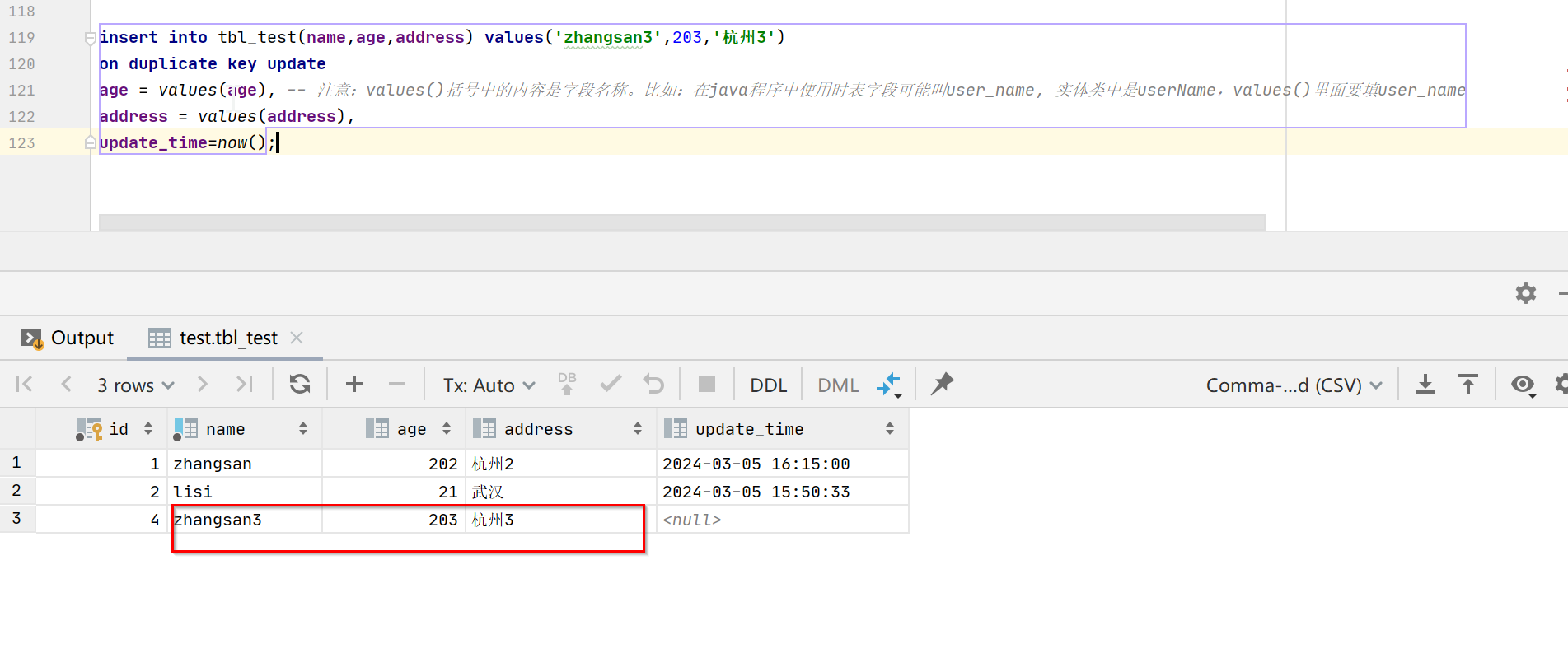
这条执行就比较简单了,没有主键或唯一键字段值相同,即判断当前记录不存在,新插入一条。
注意: 这里我们发现主键id并没有连续,直接从2变成了4,具体原理可见《MySQL数据库设置主键自增、自增主键为什么不能保证连续递增》
2.4、案例四:主键与唯一键字段同时存在
如下sql:
insert into tbl_test(id,name,age,address) values(1,'zhangsan4',204,'杭州4')
on duplicate key update
name = values(name),
age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name
address = values(address),
update_time=now();
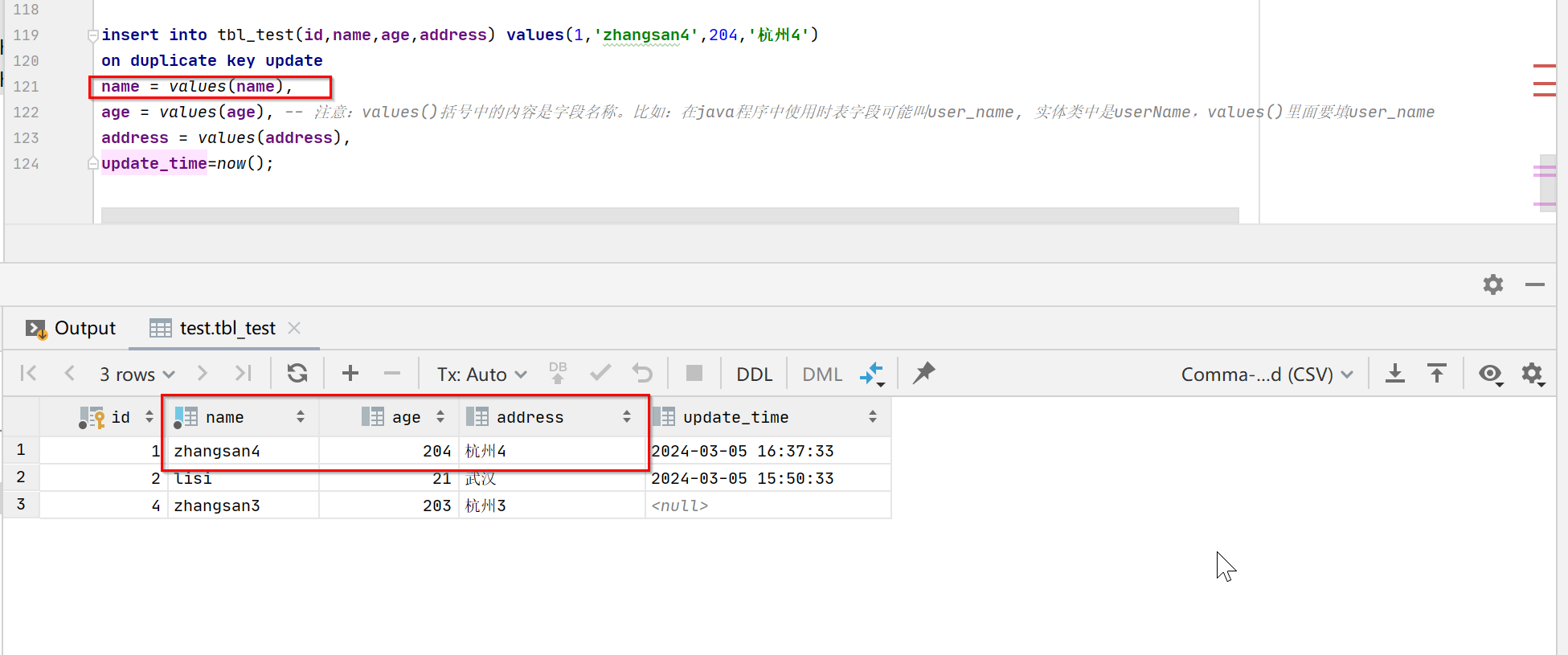
从上面可以看出,连唯一键name也被修改了。结论:
4:如果传递了主键,是可以修改唯一键字段内容的。
这里要注意,如果这里的name修改为 lisi,zhangsan3
会报唯一键冲突的。可以自行尝试。
三、ON DUPLICATE KEY UPDATE的注意事项
3.1、on dupdate key update之后values的使用事项
如下sql:
insert into tbl_test(name,age,address,update_time) values('zhangsan4',205,'杭州5','2024-03-05 00:00:00')
on duplicate key update
age = age,
address = '杭州',
update_time=values(update_time);

on dupdate key update之后没有用values的情况
分为两种情况:
1:如果为如上面的address= “杭州”,则会一直更新为"杭州".
2:如果为如上面的age = age,则age会保持数据库中的值,不会更新。
3:只有当使用了values后,才会更新为上下文中传入的值
3.2、对values使用判断
如下sql
insert into tbl_test(id,name,age,address) values(1,'zhangsan',202,'杭州2')
on duplicate key update
name = ifnull(values(name),name),
age = values(age)
达到的效果是,如果传入的name值为null,则不更新。不为null则更新。这里与mybatis配合使用比较好。
3.3、唯一索引大小写敏感问题
思考这么一个问题:如上面name作为唯一索引,当name大小写敏感时且数据库中存储了name=“zhangsan” ,那么再插入name="ZHANGSAN"是更新还是新增?
1):唯一索引大小写不敏感时
设置name字段为唯一索引且大小写不敏感
drop table if exists tbl_test;
create table tbl_test(id int primary key auto_increment,name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null,age int comment '年龄',address varchar(50) comment '住址',update_time datetime default null
) comment '测试表';insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now());
insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now());
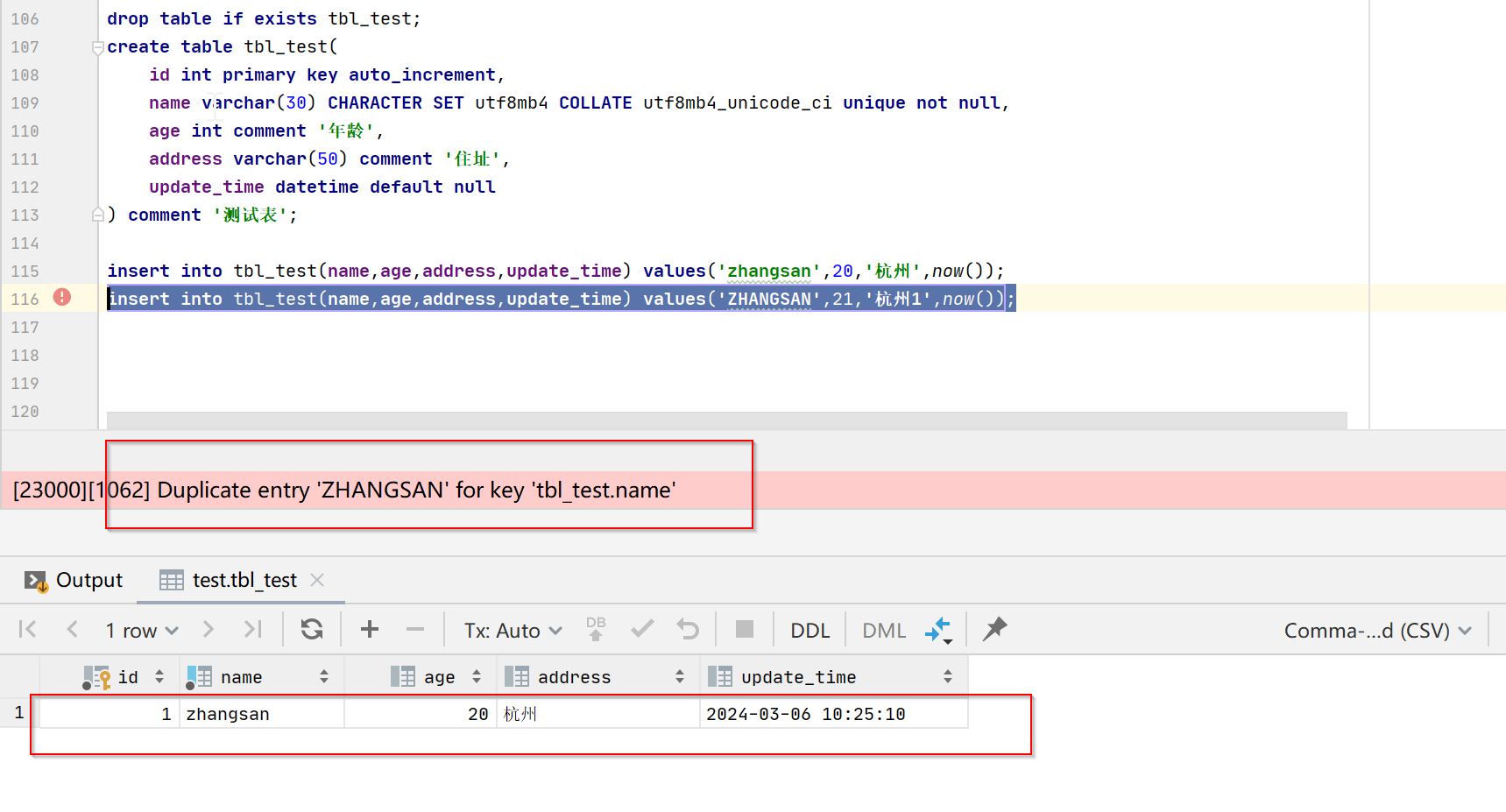
可以看到当字段为大小写不敏感时zhangsan跟ZHANGSAN被认为是同一个值,不能重复插入。
当数据库中name=zhangsan时且name字段大小写不敏感时,我们看一下name="ZHANGSAN"能否更新成功?
insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',22,'杭州2','2024-03-05 00:00:00')
on duplicate key update
age = values(age),
address = values(address),
update_time=values(update_time);
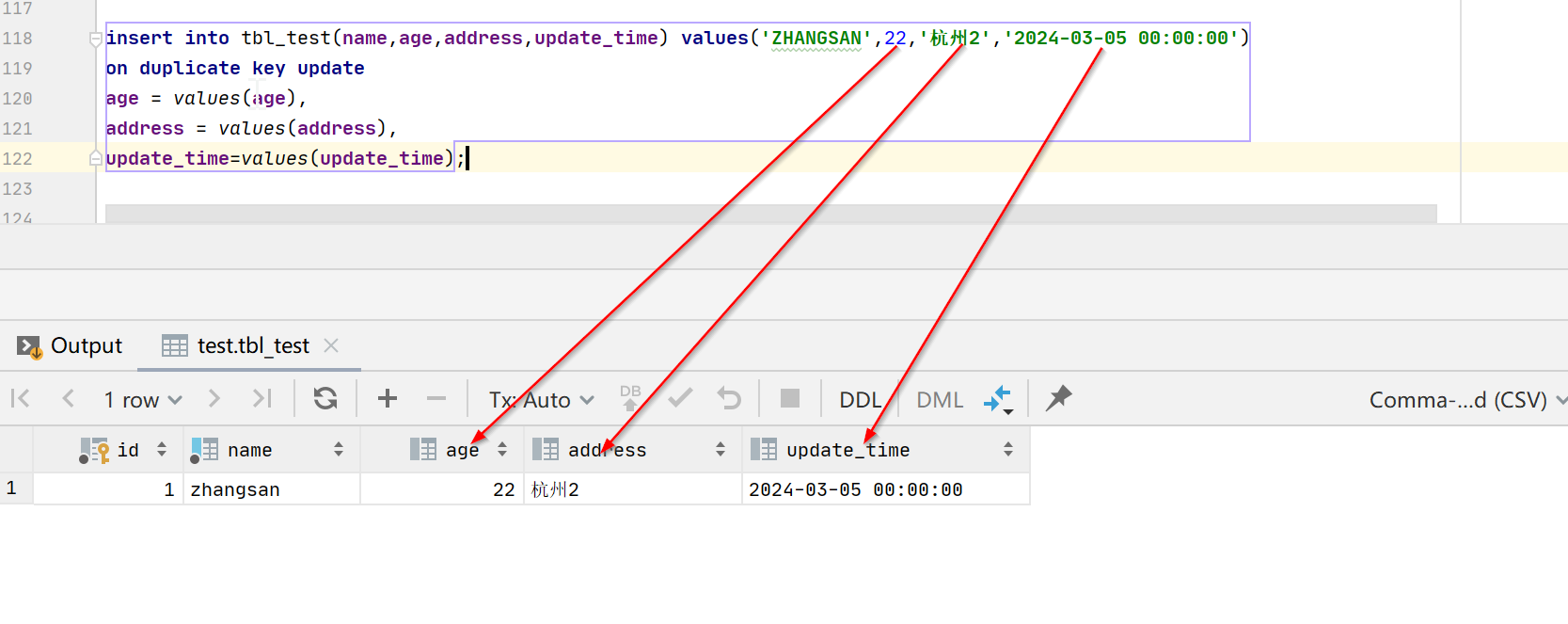
以上结果可以看出,当大小写不敏感时on duplicate key update是可以更新成功的,即认为是同一个值。
2):唯一索引大小写敏感时
设置name字段为唯一索引且大小写敏感
drop table if exists tbl_test;
create table tbl_test(id int primary key auto_increment,name varchar(30) CHARACTER SET utf8 COLLATE utf8_bin unique not null,age int comment '年龄',address varchar(50) comment '住址',update_time datetime default null
) comment '测试表';insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now());
insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now());
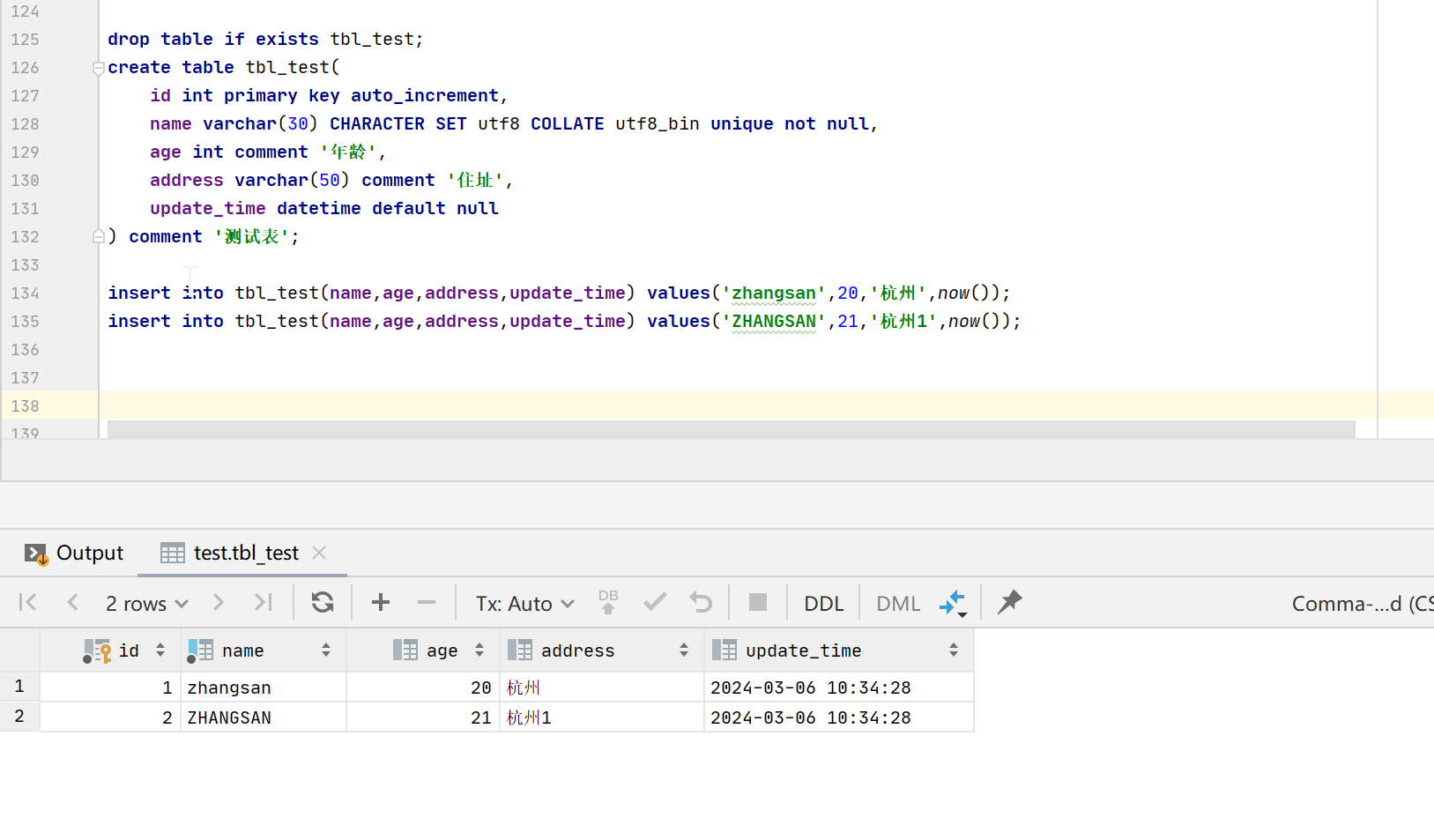
可以看到当字段为大小写敏感时zhangsan跟ZHANGSAN被认为是两个值,插入了两条记录。所以此时用on duplicate key update会执行新增操作
四、ON DUPLICATE KEY UPDATE与mybatis联合使用
4.1、写法一:与values()联合使用
注意:values后面的内容是表字段名称即带下划线,而不是实体类驼峰名称
如下sql: dept_id为主键或唯一索引
<insert id="replaceInto">INSERT INTO sys_dept(dept_id,parent_id,status,update_time) VALUES<foreach collection="deptList" item="item" separator=",">(#{item.deptId},#{item.parentId},#{item.status},#{item.updateTime})</foreach>ON DUPLICATE KEY UPDATEparent_id=VALUES(parent_id),status=VALUES(status),update_time=VALUES(update_time)
</insert>
4.2、写法二:使用#{}
如下sql: dept_id为主键或唯一索引
<insert id="replaceInto">INSERT INTO sys_dept(dept_id,parent_id,status,update_time) VALUES<foreach collection="deptList" item="item" separator=",">(#{item.deptId},#{item.parentId},#{item.status},#{item.updateTime})</foreach>ON DUPLICATE KEY UPDATE<foreach collection="deptList" item="item" separator=",">parent_id = #{item.parentId},status = #{item.status},update_time = #{item.updateTime}</foreach>
</insert>
五、ON DUPLICATE KEY UPDATE的缺点及坑
5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续
如下sql:
drop table if exists tbl_test;
create table tbl_test(id int primary key auto_increment,name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null,age int comment '年龄',address varchar(50) comment '住址',update_time datetime default null
) comment '测试表';insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('李四',21,'武汉',now());
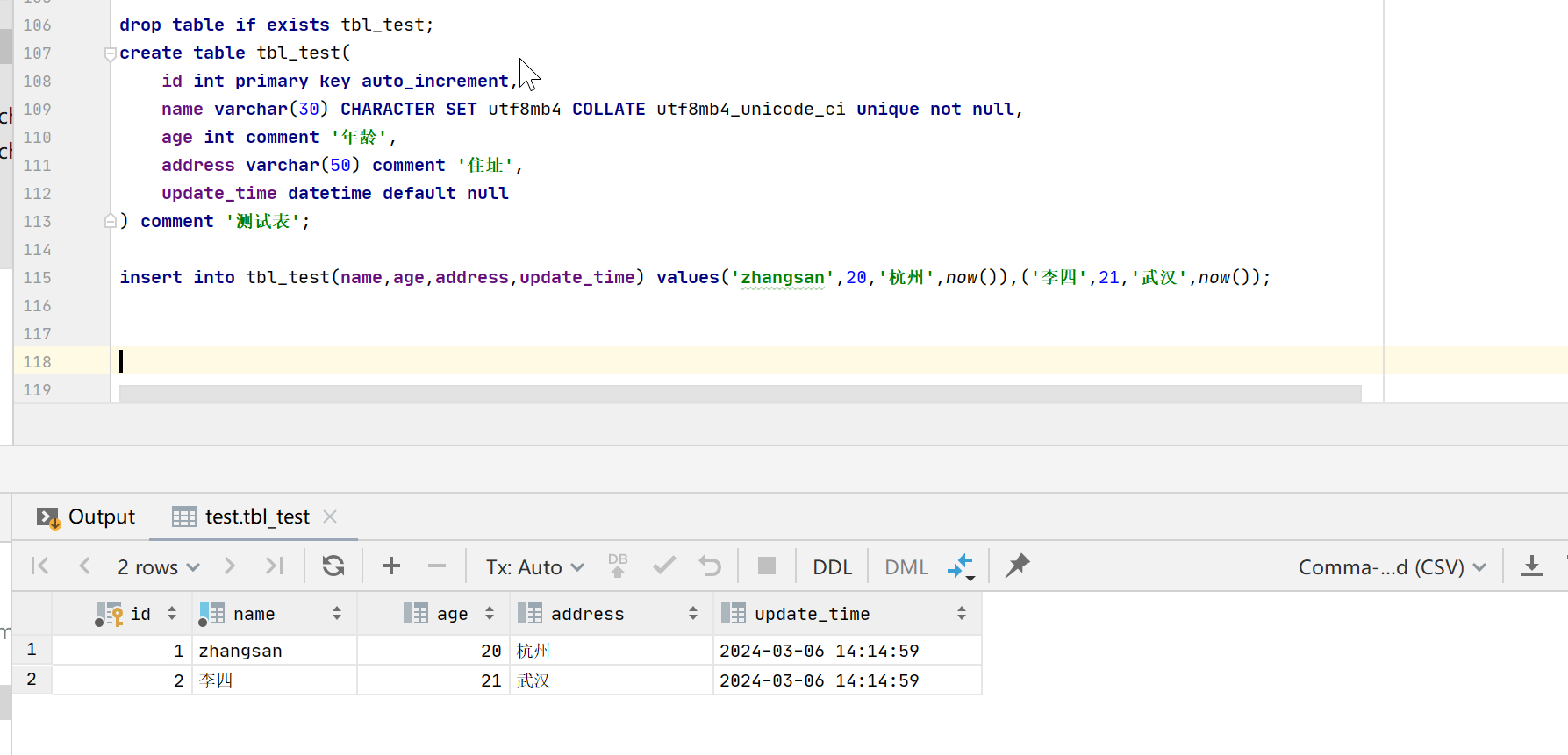
执行on duplicate key update进行更新,然后再插入一条新的数据
insert into tbl_test(name,age,address,update_time) values('zhangsan',22,'杭州2','2024-03-05 00:00:00')
on duplicate key update
age = values(age),
address = values(address),
update_time=values(update_time);insert into tbl_test(name,age,address,update_time) values('王五',23,'深圳',now());
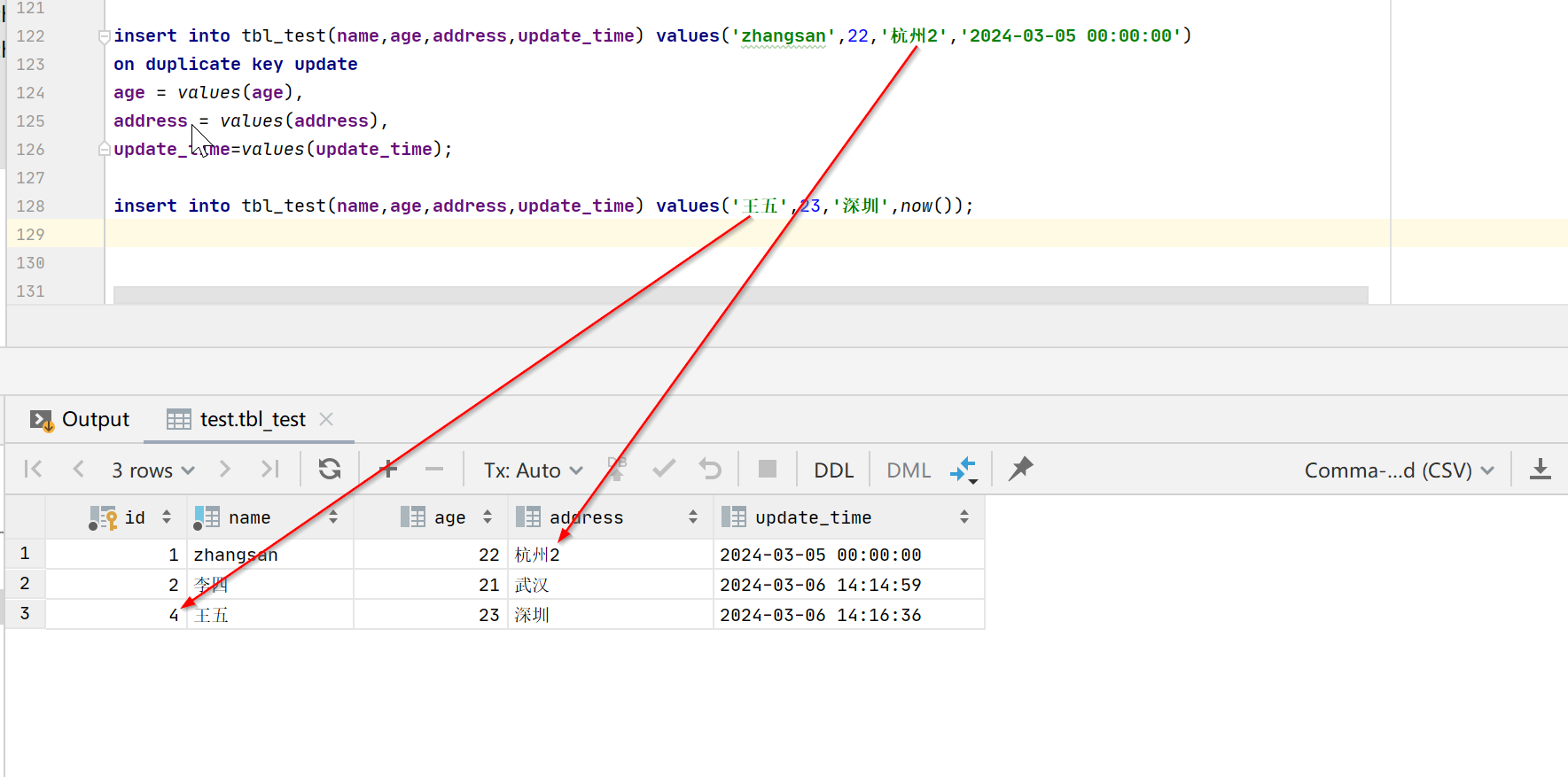
可以看到id自增值从2直接变成了4,造成了id的不连续。
1.ON DUPLICATE KEY UPDATE每次更新导致id不连续原理:
mysql中有个配置值是innodb_autoinc_lock_mode。
innodb_autoinc_lock_mode中有3中模式,0,1和2,mysql5的默认配置是1,
- 0是每次分配自增id的时候都会锁表.
- 1只有在bulk insert的时候才会锁表,简单insert的时候只会使用一个light-weight mutex,比0的并发性能高
- 2.没有仔细看,好像是很多的不保证…不太安全.
数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into … on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update
5.2、death lock死锁
经常看到网上说ON DUPLICATE KEY UPDATE会导致死锁,确实是存在这个可能的,不过由于目前没有特别好的方案,所以也只能使用这个sql语法了。在执行insert ... on duplicate key语句时,如果不对同一个表同时进行并发的insert或者update,基本不会造成死锁。即insert ... on duplicate key时尽量单线程串行进行新增或更新
insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。
如果有两个事务并发的执行同样的语句,那么就会产生death lock,如:


![[云原生] Prometheus之部署 Alertmanager 发送告警](https://img-blog.csdnimg.cn/direct/c8ef487e85594da28d84761880900a09.png)