开篇
菩提修妙树,接引证法源,屠龙万仙阵,玉虚祭封神。
混战是国内技术圈的常态,在众仙跟风与追捧的大潮中,如何看清方向至关重要,决定谁最终将封神。
语言大模型(LLM),多模态(MM),RAG是当下的热词,LLM将NLP带入到了2.0时代,LLM+MM将媒体带入到了2.0时代,必然,LLM+MM+RAG会将检索带入到2.0时代。
混迹于检索领域也有多年,从2011年开始,先后经历过大小的检索相关项目:非线性编辑媒资库检索(图片检索+文本检索),字幕自动生成(语音识别+文本匹配检索),节目检索(图片检索+音频检索),搜剧(图片检索+视频处理),相册管理(图片识别检索+文本检索+视频分析)等项目,对end to end的流程及优化技术还算了解,对AI模型的ensemble使用及performence炼丹接触较多,后面针对RAG做一些粗浅的分析,欢迎指正和讨论,勿喷~。
RAG的本质及作用
RAG = Retrieval Augmented Generation,本质呢,其实是Generation,这也定了个下文的基调,也是下文分析的基础,如何generate,如何generate的更好,谁有generate的能力。
提到RAG,凭借着谷哥度娘的强大能力,可能大多数人都能娓娓道来,么么哒,基于检索增强的内容生成,对大模型有好处,云云。深究一下,在我看来,RAG在generate有四方面的作用:
- 协助不正经的LLM产生正经的结果,采用多方证据或事实,监督LLM,防止它胡说八道(LLM幻觉)
- 和LLM或推荐系统合作,五五开,共同构建历史性结果,防止前后时间上的信息脱节(因为LLM训练成本大,不大可能频频用最新的样本训练)
- 和多模态合作,补充优质信息到text2video,text2image等模型,生成更符合物理世界的效果,生成更丰富的内容
- long sequence(context)其实对LLM无益处(越长,attention消失越多,占资源越多),短+紧凑的prompt更能产生优质回答或结果。Is Long Sequence All LLM's Need?-Oh, No, 只是有时候迫不得已(物理表示就是这样的,叫我怎么办?但我并不关心冗余的token,要么你玩转高难度的attention pattern,要么你用RAG给我精简,要么你手工给我摘干净,My God!),所以出现了各种利用window+local+trunk+sparse+rnn优化attention的方法,本质都是不想用那么多attention,不想和更多的token关联。起初,我以为RAG通过查询向量数据库会增大sequence length,但仔细想一下,这只是表象,RAG需要进一步压缩结果的表示空间(这是兵家必争之地,也是创造门槛的地方,如果只玩vector distance+vector similarity,想必大家都会玩),使得sequence length变短才算无上妙法。
RAG的技术依赖
首先,说明一下,向量数据库(检索)不是一个新鲜事物,如果track了检索技术发展的整个历史脉络,那么,肯定不会因为它在LLM时代蹦出来而感到兴奋。
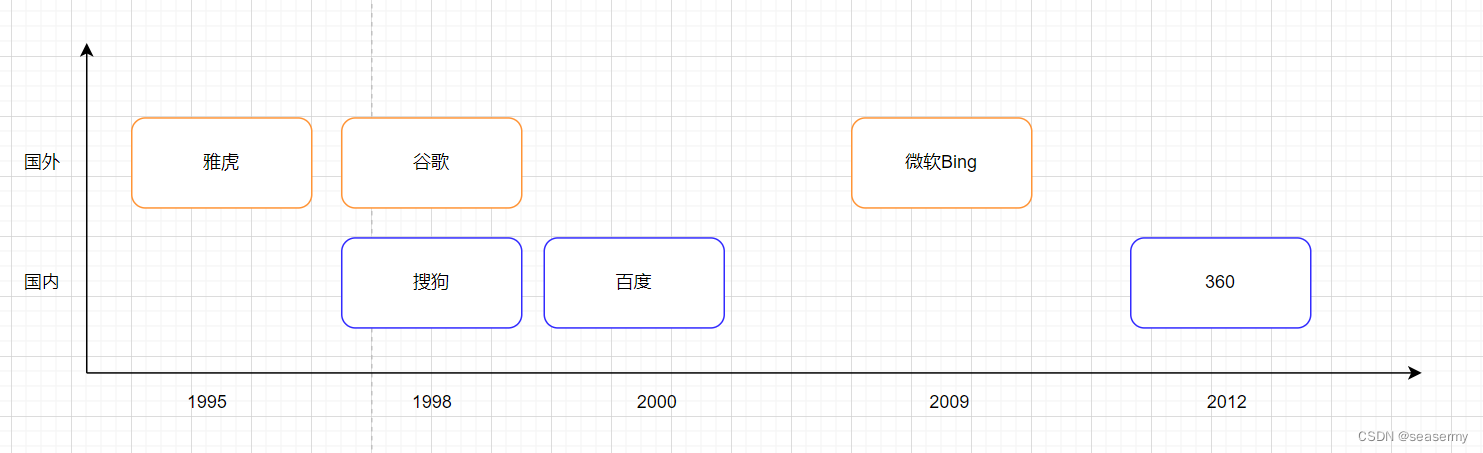
早在2000年,百度就follow了谷歌的文本搜索技术,构建大规模中文搜索引擎,后来构建了大规模图片搜索引擎,底层依赖的技术都是向量库索引与检索(曾经研究热度很高),经过20多年的发展,向量embedding生成技术->向量检索与索引技术->大规模检索集群部署其实已经发展相当完善(研究热度下降,都在搞竞价排名~)。
如果非要给retrieval一个蹭LLM热点的理由,那么,我希望它是“反哺”,而不是“投怀”(下文再续)。
软件依赖
RAG的本质是generation,但引起generation质变的是retrieval,可能到了这里,又可以娓娓道来一次,又可以侃侃而谈一次,又可以和谷哥度娘有一次亲密接触,向量数据库嘛,云云。概括起来,最关键的软件依赖是向量数据库底层的东西:
- 用于构建索引或进行检索的embedding是否具有简约性(shorter dimension,越短越好)和鉴别性(descrimitive)
- 构建索引的算法是否具有鉴别性,是否能将多维空间可分做到最优
- 构建索引(可以理解成train)和索引检索(可以理解成inference)的效率。构建索引一般是离线的,数据量很大。构建索引也可能是增量online的,数据量不大,满足实时完善索引库的需求。索引检索需要照顾到multi request(可以理解为batchsize),不同batchsize的性能是不同的,检索是典型的IO bound的场景。
硬件依赖
(1)通用计算支持能力
Is Vector Processing all RAG's Need? - Oh, No。
RAG中的R就是传统的R技术,除了vector similarity计算(1D计算)外,对如下技术的性能依赖性很强:
- graph/tree数据结构遍历与检索
- 排序
- 递归
- 高并发度
- 细粒度scalar/task操作
- 随机存储与访问等
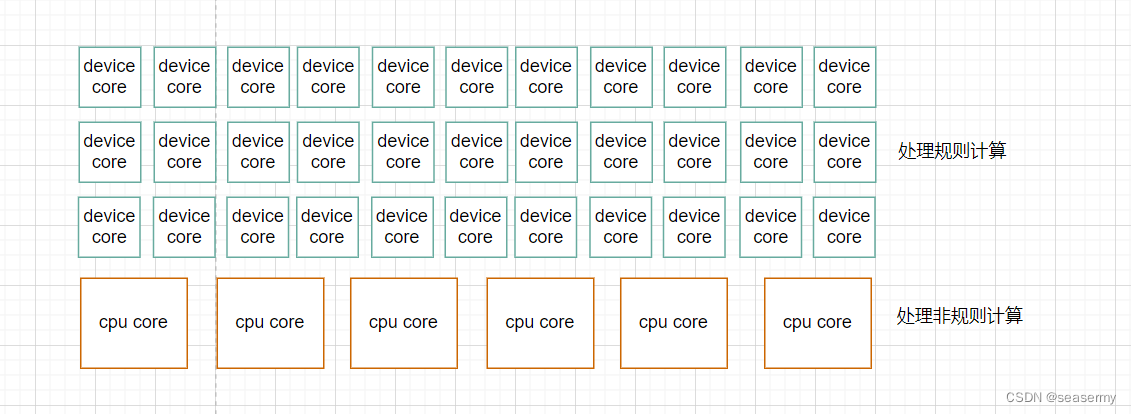
(2)memory hierachy
向量检索在memory的访问上可能受如下特性影响,多级存储和cache(同时保证hot<->device间的访问或传输延时)+异构计算可能会比较适合:
- task粒度小,指令散,控制逻辑可能比较复杂,code size可能更大
- 数据操作粒度小,非vector操作较多,随机访存场景多
- 并发度高
- 索引巨大,不能完全存于device memory(和推荐系统的embedding table比较类似)

(3)communication
- 不同于AI,多机多卡间的传输数据类型不同(size+granularity)
模型依赖
RAG与模型的关系需要特别强调一下,团结拼搏,共勉创优一直是一件好事情,对于G(eneration)来说,R(etrieval)“反哺”LLM生成更好的内容,对于R(etrieval)来说,G(eneration)"投怀" 向量检索,生成更好的embedding representation,未来的LLM+多模态+RAG的流程发展趋势大概就是如下:
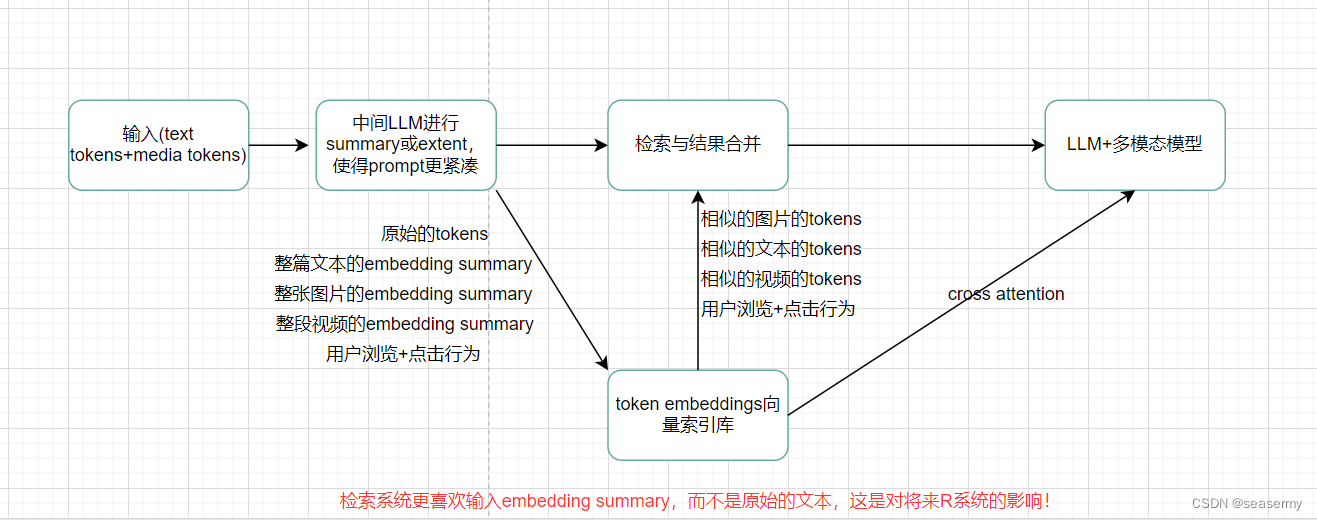
头部玩家的战场
如上所述,得出如下结论:
- 有媒体内容存货的容易进入战场
- 检索和索引技术能力强大的容易进入战场
- 性能突出的硬件芯片厂商容易进入战场
- 啥都不行,能给别人提供战场(部署R+G)的容易进入战场
- 大流量+大日活+大数据存储的厂商容易进入战场(垂直领域可能机会较少,或没必要借助RAG)
硬件芯片厂商
- 国外:nvidia gpu+amd gpu+intel cpu
- 国内:有前途,很期待
云服务厂商
- 腾讯云
- 阿里云
媒体运营商
- 爱奇艺
- 腾讯视频
- 视觉中国
- 全景中国
- 百度图片
- Get Image
老牌检索商
- 百度
- 搜狗
- 360
电商与推荐
- 京东
- 阿里
- 字节
更多的产品形态预测
- 媒体方(例如:get image的AI服务)开发RAG接口,向多模态生产方提供内容输出服务(抱歉,除了收正经版权费,我也要分AIGC一杯羹)
- 电商生成更真实的店家展示图片
- AI检索+Legacy检索增强检索效果
- 实时推荐系统
参考
推荐的其他阅读材料:Retrieval-Augmented Generation for Large Language Models: A Survey