学习参考:
- 动手学深度学习2.0
- Deep-Learning-with-TensorFlow-book
- pytorchlightning
①如有冒犯、请联系侵删。
②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。
③非常推荐上面(学习参考)的前两个教程,在网上是开源免费的,写的很棒,不管是开始学还是复习巩固都很不错的。
深度学习回顾,专栏内容来源多个书籍笔记、在线笔记、以及自己的感想、想法,佛系更新。争取内容全面而不失重点。完结时间到了也会一直更新下去,已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。所有文章涉及的教程都会写在开头、一起学习一起进步。
1.神经网络的层和块
神经网络块,“比单个层大”但“比整个模型小”的组件。块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的:
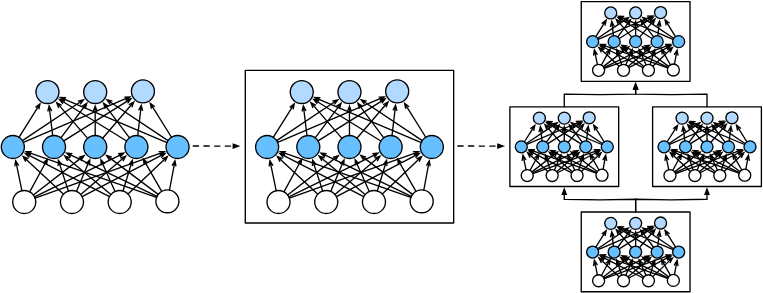
从编程的角度来看,块由类(class)表示。 它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。
如下代码,进行解读:
通过实例化keras.models.Sequential来构建模型, 层的执行顺序是作为参数传递的。 简而言之,Sequential定义了一种特殊的keras.Model, 即在Keras中表示一个块的类。 它维护了一个由Model组成的有序列表, 注意两个全连接层都是Model类的实例, 这个类本身就是Model的子类。 前向传播(call)函数也非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。 注意,到目前为止,一直在通过net(X)调用模型来获得模型的输出。 这实际上是net.call(X)的简写, 这是通过Block类的__call__函数实现的一个Python技巧。
import tensorflow as tfnet = tf.keras.models.Sequential([tf.keras.layers.Dense(256, activation=tf.nn.relu),tf.keras.layers.Dense(10),
])X = tf.random.uniform((2, 20))
net(X)#相当于net.__call__(X)
Sequential的设计是为了把其他模块串起来。
2.自定义 块
从零开始编写一个块。 它包含一个多层感知机,其具有256个隐藏单元的隐藏层和一个10维输出层。 注意,下面的MLP类继承了表示块的类。 实现只需要提供自己的构造函数(Python中的__init__函数)和前向传播函数。
- 将输入数据作为其前向传播函数的参数。
- 通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收任意维的输入,但是返回一个维度256的输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
class MLP(tf.keras.Model):# 用模型参数声明层。这里,我们声明两个全连接的层def __init__(self):# 调用MLP的父类Model的构造函数来执行必要的初始化。# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)super().__init__()# Hiddenlayerself.hidden = tf.keras.layers.Dense(units=256, activation=tf.nn.relu)self.out = tf.keras.layers.Dense(units=10) # Outputlayer# 定义模型的前向传播,即如何根据输入X返回所需的模型输出def call(self, X):return self.out(self.hidden((X)))net = MLP()
net(X)
代码解读:
- 前向传播函数以X作为输入, 计算带有激活函数的隐藏表示,并输出其未规范化的输出值。
- 实例化多层感知机的层,然后在每次调用前向传播函数时调用这些层;定制的
__init__函数通过super().__init__()调用父类的__init__函数, 省去了重复编写模版代码的痛苦。 - 实例化两个全连接层, 分别为self.hidden和self.out。 注意,除非要实现一个新的运算符, 否则不必担心反向传播函数或参数初始化, 系统将自动生成这些。
(1)顺序块
Sequential的设计基本上总结为:
- 一种将块逐个追加到列表中的函数;
- 一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
如下,MySequential的用法与之前为Sequential类编写的代码相同。
class MySequential(tf.keras.Model):def __init__(self, *args):super().__init__()self.modules = []for block in args:# 这里,block是tf.keras.layers.Layer子类的一个实例self.modules.append(block)def call(self, X):for module in self.modules:X = module(X)return Xnet = MySequential(tf.keras.layers.Dense(units=256, activation=tf.nn.relu),tf.keras.layers.Dense(10))
net(X)
3. 在前向传播函数中执行代码
Sequential类使模型构造变得简单, 允许组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,需要定义自己的块。
网络中的所有操作都对网络的激活值及网络的参数起作用,然而,希望合并既不是上一层的结果也不是可更新参数的项, 称之为常数参数(constant parameter)。
class FixedHiddenMLP(tf.keras.Model):def __init__(self):super().__init__()self.flatten = tf.keras.layers.Flatten()# 使用tf.constant函数创建的随机权重参数在训练期间不会更新(即为常量参数)self.rand_weight = tf.constant(tf.random.uniform((20, 20)))self.dense = tf.keras.layers.Dense(20, activation=tf.nn.relu)def call(self, inputs):X = self.flatten(inputs)# 使用创建的常量参数以及relu和matmul函数X = tf.nn.relu(tf.matmul(X, self.rand_weight) + 1)# 复用全连接层。这相当于两个全连接层共享参数。X = self.dense(X)# 控制流while tf.reduce_sum(tf.math.abs(X)) > 1:X /= 2return tf.reduce_sum(X)net = FixedHiddenMLP()
net(X)
在这个FixedHiddenMLP模型中,实现了一个隐藏层, 其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。 这个权重不是一个模型参数,因此它永远不会被反向传播更新。
4.多个块混合组合
一个块混合搭配各种组合块,一个块可以由许多层组成;一个块可以由许多块组成。
class FixedHiddenMLP(tf.keras.Model):def __init__(self):super().__init__()self.flatten = tf.keras.layers.Flatten()# 使用tf.constant函数创建的随机权重参数在训练期间不会更新(即为常量参数)self.rand_weight = tf.constant(tf.random.uniform((20, 20)))self.dense = tf.keras.layers.Dense(20, activation=tf.nn.relu)def call(self, inputs):X = self.flatten(inputs)# 使用创建的常量参数以及relu和matmul函数X = tf.nn.relu(tf.matmul(X, self.rand_weight) + 1)# 复用全连接层。这相当于两个全连接层共享参数。X = self.dense(X)# 控制流while tf.reduce_sum(tf.math.abs(X)) > 1:X /= 2return tf.reduce_sum(X)class NestMLP(tf.keras.Model):def __init__(self):super().__init__()self.net = tf.keras.Sequential()self.net.add(tf.keras.layers.Dense(64, activation=tf.nn.relu))self.net.add(tf.keras.layers.Dense(32, activation=tf.nn.relu))self.dense = tf.keras.layers.Dense(16, activation=tf.nn.relu)def call(self, inputs):return self.dense(self.net(inputs))chimera = tf.keras.Sequential()
chimera.add(NestMLP())
chimera.add(tf.keras.layers.Dense(20))
chimera.add(FixedHiddenMLP())
chimera(X)
5.参数管理
在选择了架构并设置了超参数后,就进入了训练阶段。 此时,目标是找到使损失函数最小化的模型参数值。经过训练后,将需要使用这些参数来做出未来的预测。 此外,希望提取参数,以便在其他环境中复用它们, 将模型保存下来,以便它可以在其他软件中执行, 或者为了获得科学的理解而进行检查。
import tensorflow as tfnet = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4, activation=tf.nn.relu),tf.keras.layers.Dense(1),
])X = tf.random.uniform((2, 4))
net(X)
5.1参数访问
从已有模型中访问参数。 当通过Sequential类定义模型时, 可以通过索引来访问模型的任意层。 这就像模型是一个列表一样,每层的参数都在其属性中。
import tensorflow as tfnet = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4, activation=tf.nn.relu),tf.keras.layers.Dense(1),
])X = tf.random.uniform((2, 4))
net(X)
print(net.layers[2].weights)
[<tf.Variable 'dense_1/kernel:0' shape=(4, 1) dtype=float32, numpy=
array([[ 0.06311333],[-0.17863423],[-0.38862765],[ 0.9374387 ]], dtype=float32)>, <tf.Variable 'dense_1/bias:0' shape=(1,) dtype=float32, numpy=array([0.], dtype=float32)>]
代码解释:
首先,这个全连接层包含两个参数,分别是该层的权重和偏置。 两者都存储为单精度浮点数(float32)。 注意,参数名称允许唯一标识每个参数,即使在包含数百个层的网络中也是如此。
(1)访问目标参数
注意,每个参数都表示为参数类的一个实例。 要对参数执行任何操作,首先需要访问底层的数值。
第二个全连接层(即第三个神经网络层)提取偏置, 提取后返回的是一个参数类实例,并进一步访问该参数的值:
print(type(net.layers[2].weights[1]))
print(net.layers[2].weights[1])
print(tf.convert_to_tensor(net.layers[2].weights[1]))
<class 'tensorflow.python.ops.resource_variable_ops.ResourceVariable'>
<tf.Variable 'dense_1/bias:0' shape=(1,) dtype=float32, numpy=array([0.], dtype=float32)>
tf.Tensor([0.], shape=(1,), dtype=float32)
(2) 一次性访问所有参数
当需要对所有参数执行操作时,逐个访问它们可能会很麻烦。 当处理更复杂的块(例如,嵌套块)时,情况可能会变得特别复杂, 因为需要递归整个树来提取每个子块的参数。
print(net.layers[1].weights)
print(net.get_weights())
[<tf.Variable 'dense/kernel:0' shape=(4, 4) dtype=float32, numpy=
array([[ 0.34964794, -0.01246995, -0.66718704, 0.8423942 ],[ 0.40420133, 0.48373526, -0.16817617, 0.58779615],[-0.33410978, 0.44151586, -0.14673978, -0.4114933 ],[-0.18501085, -0.1278897 , 0.5296257 , 0.21039444]],dtype=float32)>, <tf.Variable 'dense/bias:0' shape=(4,) dtype=float32, numpy=array([0., 0., 0., 0.], dtype=float32)>]
[array([[ 0.34964794, -0.01246995, -0.66718704, 0.8423942 ],[ 0.40420133, 0.48373526, -0.16817617, 0.58779615],[-0.33410978, 0.44151586, -0.14673978, -0.4114933 ],[-0.18501085, -0.1278897 , 0.5296257 , 0.21039444]],dtype=float32), array([0., 0., 0., 0.], dtype=float32), array([[-0.58489895],[-0.6303506 ],[-1.0014054 ],[-0.02034676]], dtype=float32), array([0.], dtype=float32)]
net.get_weights()[1]
array([0., 0., 0., 0.], dtype=float32)
(3)从嵌套块收集参数
如果将多个块相互嵌套,参数命名约定是如何工作的。 首先定义一个生成块的函数(可以说是“块工厂”),然后将这些块组合到更大的块中。
def block1(name):return tf.keras.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4, activation=tf.nn.relu)],name=name)def block2():net = tf.keras.Sequential()for i in range(4):# 在这里嵌套net.add(block1(name=f'block-{i}'))return netrgnet = tf.keras.Sequential()
rgnet.add(block2())
rgnet.add(tf.keras.layers.Dense(1))
rgnet(X)
<tf.Tensor: shape=(2, 1), dtype=float32, numpy=
array([[0.03218262],[0.04669464]], dtype=float32)>
print(rgnet.summary())
Model: "sequential_1"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================sequential_2 (Sequential) (2, 4) 80 dense_6 (Dense) (2, 1) 5 =================================================================
Total params: 85
Trainable params: 85
Non-trainable params: 0
_________________________________________________________________
None
因为层是分层嵌套的,所以也可以像通过嵌套列表索引一样访问它们。 下面,访问第一个主要的块中、第二个子块的第一层的偏置项。
rgnet.layers[0].layers[1].layers[1].weights[1]
<tf.Variable 'dense_3/bias:0' shape=(4,) dtype=float32, numpy=array([0., 0., 0., 0.], dtype=float32)>
5.2参数初始化
深度学习框架提供默认随机初始化, 也允许创建自定义初始化方法, 满足通过其他规则实现初始化权重。默认情况下,Keras会根据一个范围均匀地初始化权重矩阵, 这个范围是根据输入和输出维度计算出的。 偏置参数设置为0。 TensorFlow在根模块和keras.initializers模块中提供了各种初始化方法。
(1)内置默认初始化
首先调用内置的初始化器。 下面将所有权重参数初始化为标准差为0.01的高斯随机变量, 且将偏置(均重)参数设置为0。
net = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4, activation=tf.nn.relu,kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.01),bias_initializer=tf.zeros_initializer()),tf.keras.layers.Dense(1)])net(X)
net.weights[0], net.weights[1]
(<tf.Variable 'dense_7/kernel:0' shape=(4, 4) dtype=float32, numpy=array([[-0.0084911 , 0.01987272, 0.0047598 , 0.00767572],[ 0.00302977, 0.00571064, 0.01353499, -0.00716146],[ 0.01516861, -0.0042888 , -0.01337093, 0.01640075],[-0.00443652, 0.00357472, 0.003672 , 0.00791739]],dtype=float32)>,<tf.Variable 'dense_7/bias:0' shape=(4,) dtype=float32, numpy=array([0., 0., 0., 0.], dtype=float32)>)
还可以将所有参数初始化为给定的常数,比如初始化为1。
net = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4, activation=tf.nn.relu,kernel_initializer=tf.keras.initializers.Constant(1),bias_initializer=tf.zeros_initializer()),tf.keras.layers.Dense(1),
])net(X)
net.weights[0], net.weights[1]
(<tf.Variable 'dense_9/kernel:0' shape=(4, 4) dtype=float32, numpy=array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]], dtype=float32)>,<tf.Variable 'dense_9/bias:0' shape=(4,) dtype=float32, numpy=array([0., 0., 0., 0.], dtype=float32)>)
还可以对某些块应用不同的初始化方法。 例如,下面使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42。
net = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4,activation=tf.nn.relu,kernel_initializer=tf.keras.initializers.GlorotUniform()),tf.keras.layers.Dense(1, kernel_initializer=tf.keras.initializers.Constant(1)),
])net(X)
print(net.layers[1].weights[0])
print(net.layers[2].weights[0])
<tf.Variable 'dense_11/kernel:0' shape=(4, 4) dtype=float32, numpy=
array([[ 0.05044675, -0.75048006, -0.27696246, 0.3049981 ],[-0.8364825 , 0.71040255, 0.05052626, 0.6309851 ],[ 0.7461434 , 0.43411523, 0.25171906, -0.76259345],[ 0.5316939 , 0.4294545 , -0.22395748, 0.08069021]],dtype=float32)>
<tf.Variable 'dense_12/kernel:0' shape=(4, 1) dtype=float32, numpy=
array([[1.],[1.],[1.],[1.]], dtype=float32)>
(2)自定义初始化
深度学习框架没有提供所需要的初始化方法。例如使用以下的分布为任意权重参数 𝑤 定义初始化方法:

下面定义了一个Initializer的子类, 并实现了__call__函数。 该函数返回给定形状和数据类型的所需张量。
class MyInit(tf.keras.initializers.Initializer):def __call__(self, shape, dtype=None):data=tf.random.uniform(shape, -10, 10, dtype=dtype)factor=(tf.abs(data) >= 5)factor=tf.cast(factor, tf.float32)return data * factornet = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(4,activation=tf.nn.relu,kernel_initializer=MyInit()),tf.keras.layers.Dense(1),
])net(X)
print(net.layers[1].weights[0])
<tf.Variable 'dense_13/kernel:0' shape=(4, 4) dtype=float32, numpy=
array([[-5.0103664, 6.178299 , 0. , 6.052822 ],[-6.3095307, 6.418064 , -8.592429 , 0. ],[ 8.59478 , -8.356173 , -0. , -0. ],[-0. , 8.881723 , -8.509399 , -0. ]], dtype=float32)>
也可以直接设置参数:
# assign(42)意味着将这个特定位置的权重值设置为42。
net.layers[1].weights[0][:].assign(net.layers[1].weights[0] + 1)
# assign(42)意味着将这个特定位置的权重值设置为42。
net.layers[1].weights[0][0, 0].assign(42)
net.layers[1].weights[0]
(3)参数绑定
在多个层间共享参数: 可以定义一个稠密层,然后使用它的参数来设置另一个层的参数。
# tf.keras的表现有点不同。它会自动删除重复层
shared = tf.keras.layers.Dense(4, activation=tf.nn.relu)
net = tf.keras.models.Sequential([tf.keras.layers.Flatten(),shared,shared,tf.keras.layers.Dense(1),
])net(X)
# 检查参数是否不同,查看网络层数。
print(len(net.layers) == 3)
6.延后初始化
延后初始化就是提前不指定输入维度,喂入数据时会自动指定。
到目前为止,忽略了建立网络时需要做的以下这些事情:
- 定义了网络架构,但没有指定输入维度。
- 添加层时没有指定前一层的输出维度。
- 在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。
如果不指定输入维度,深度学习框架无法判断网络的输入维度是什么。 这里的诀窍是框架的延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
在以后,当使用卷积神经网络时, 由于输入维度(即图像的分辨率)将影响每个后续层的维数, 有了该技术将更加方便。 现在在编写代码时无须知道维度是什么就可以设置参数, 这种能力可以大大简化定义和修改模型的任务。
import tensorflow as tfnet = tf.keras.models.Sequential([tf.keras.layers.Dense(256, activation=tf.nn.relu),tf.keras.layers.Dense(10),
])
因为输入维数是未知的,所以网络不可能知道输入层权重的维数。 因此,框架尚未初始化任何参数,通过尝试访问以下参数进行确认。请注意,每个层对象都存在,但权重为空。 使用net.get_weights()将抛出一个错误,因为权重尚未初始化。
[net.layers[i].get_weights() for i in range(len(net.layers))]
[[], []]
将数据通过网络,最终使框架初始化参数。
X = tf.random.uniform((2, 20))
net(X)
[w.shape for w in net.get_weights()]
一旦知道输入维数是20,框架可以通过代入值20来识别第一层权重矩阵的形状。 识别出第一层的形状后,框架处理第二层,依此类推,直到所有形状都已知为止。 注意,在这种情况下,只有第一层需要延迟初始化,但是框架仍是按顺序初始化的。
7.自定义层
可以用创造性的方式组合不同的层,从而设计出适用于各种任务的架构。例如,研究人员发明了专门用于处理图像、文本、序列数据和执行动态规划的层。 有时会遇到或要自己发明一个现在在深度学习框架中还不存在的层,在这些情况下,必须构建自定义层。
7.1不带参数的层
构造一个没有任何参数的自定义层。下面的CenteredLayer类要从其输入中减去均值。 要构建它,只需继承基础层类并实现前向传播功能。
import tensorflow as tfclass CenteredLayer(tf.keras.Model):def __init__(self):super().__init__()def call(self, inputs):return inputs - tf.reduce_mean(inputs)#向该层提供一些数据,验证它是否能按预期工作。
layer = CenteredLayer()
layer(tf.constant([1, 2, 3, 4, 5]))
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([-2, -1, 0, 1, 2])>
将层作为组件合并到更复杂的模型中:
net = tf.keras.Sequential([tf.keras.layers.Dense(128), CenteredLayer()])
作为额外的健全性检查,可以在向该网络发送随机数据后,检查均值是否为0。 由于处理的是浮点数,因为存储精度的原因,仍然可能会看到一个非常小的非零数。
Y = net(tf.random.uniform((4, 8)))
tf.reduce_mean(Y)
<tf.Tensor: shape=(), dtype=float32, numpy=2.561137e-09>
7.2带参数的层
定义具有参数的层, 这些参数可以通过训练进行调整。可以使用内置函数来创建参数,这些函数提供一些基本的管理功能。 比如管理访问、初始化、共享、保存和加载模型参数。 这样做的好处之一是:不需要为每个自定义层编写自定义的序列化程序。
现在,实现自定义版本的全连接层。 回想一下,该层需要两个参数,一个用于表示权重,另一个用于表示偏置项。 在此实现中,使用修正线性单元作为激活函数。 该层需要输入参数:in_units和units,分别表示输入数和输出数。
class MyDense(tf.keras.Model):def __init__(self, units):super().__init__()self.units = unitsdef build(self, X_shape):self.weight = self.add_weight(name='weight',shape=[X_shape[-1], self.units],initializer=tf.random_normal_initializer())self.bias = self.add_weight(name='bias', shape=[self.units],initializer=tf.zeros_initializer())def call(self, X):linear = tf.matmul(X, self.weight) + self.biasreturn tf.nn.relu(linear)# 实例化MyDense类并访问其模型参数
dense = MyDense(3)
dense(tf.random.uniform((2, 5)))
dense.get_weights()
[array([[-0.00381189, -0.03383113, 0.00593808],[ 0.05353226, -0.00501231, 0.0306538 ],[-0.01644411, 0.01026293, 0.02238739],[ 0.01618866, 0.03604672, 0.01572673],[ 0.01472138, 0.01281747, 0.01037676]], dtype=float32),array([0., 0., 0.], dtype=float32)]
使用自定义层直接执行前向传播计算:
dense(tf.random.uniform((2, 5)))
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.02705063, 0.01465103, 0.03184884],[0.05492032, 0.01797221, 0.04979869]], dtype=float32)>
使用自定义层构建模型,就像使用内置的全连接层一样使用自定义层。
net = tf.keras.models.Sequential([MyDense(8), MyDense(1)])
net(tf.random.uniform((2, 64)))
<tf.Tensor: shape=(2, 1), dtype=float32, numpy=
array([[0.],[0.]], dtype=float32)>
8.读写文件
8.1加载和保存张量
对于单个张量,可以直接调用load和save函数分别读写它们。 这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。
import numpy as np
import tensorflow as tfx = tf.range(4)
np.save('x-file.npy', x)
现在可以将存储在文件中的数据读回内存。
x2 = np.load('x-file.npy', allow_pickle=True)
x2
array([0, 1, 2, 3])
可以存储一个张量列表,然后把它们读回内存。
y = tf.zeros(4)
np.save('xy-files.npy', [x, y])
x2, y2 = np.load('xy-files.npy', allow_pickle=True)
(x2, y2)
(array([0., 1., 2., 3.]), array([0., 0., 0., 0.]))
写入或读取从字符串映射到张量的字典。 当要读取或写入模型中的所有权重时,这很方便。
mydict = {'x': x, 'y': y}
np.save('mydict.npy', mydict)
mydict2 = np.load('mydict.npy', allow_pickle=True)
mydict2
8.2加载和保存模型参数
保存单个权重向量(或其他张量)确实有用, 但是如果想保存整个模型,并在以后加载它们, 单独保存每个向量则会变得很麻烦。因此,深度学习框架提供了内置函数来保存和加载整个网络。 需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。当然也是可以保存模型的。
class MLP(tf.keras.Model):def __init__(self):super().__init__()self.flatten = tf.keras.layers.Flatten()self.hidden = tf.keras.layers.Dense(units=256, activation=tf.nn.relu)self.out = tf.keras.layers.Dense(units=10)def call(self, inputs):x = self.flatten(inputs)x = self.hidden(x)return self.out(x)net = MLP()
X = tf.random.uniform((2, 20))
Y = net(X)
将模型的参数存储在一个叫做“mlp.params”的文件中。
net.save_weights('mlp.params')
实例化了原始多层感知机模型的一个备份。这里不需要随机初始化模型参数,而是直接读取文件中存储的参数。
clone = MLP()
clone.load_weights('mlp.params')
由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。 验证一下:
Y_clone = clone(X)
Y_clone == Y
<tf.Tensor: shape=(2, 10), dtype=bool, numpy=
array([[False, False, False, False, False, False, False, False, False,False],[False, False, False, False, False, False, False, False, False,False]])>
9.GPU使用
9.1 指定计算设备
可以指定用于存储和计算的设备,如CPU和GPU。 默认情况下,张量是在内存中创建的,然后使用CPU计算它。
import tensorflow as tf
#查询可用gpu的数量。
print(len(tf.config.experimental.list_physical_devices('GPU')))
tf.device('/CPU:0'), tf.device('/GPU:0'), tf.device('/GPU:1')
定义了两个方便的函数, 这两个函数允许在不存在所需所有GPU的情况下运行代码。
def try_gpu(i=0): #@save"""如果存在,则返回gpu(i),否则返回cpu()"""if len(tf.config.experimental.list_physical_devices('GPU')) >= i + 1:return tf.device(f'/GPU:{i}')return tf.device('/CPU:0')def try_all_gpus(): #@save"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""num_gpus = len(tf.config.experimental.list_physical_devices('GPU'))devices = [tf.device(f'/GPU:{i}') for i in range(num_gpus)]return devices if devices else [tf.device('/CPU:0')]try_gpu(), try_gpu(10), try_all_gpus()
9.2张量与GPU
查询张量所在的设备。]默认情况下,张量是在CPU上创建的。需要注意的是,无论何时要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果对两个张量求和, 需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。
x = tf.constant([1, 2, 3])
x.device
(1) 如何存储在GPU上
有几种方法可以在GPU上存储张量。 例如,可以在创建张量时指定存储设备。接 下来,在第一个gpu上创建张量变量X。 在GPU上创建的张量只消耗这个GPU的显存。
with try_gpu():X = tf.ones((2, 3))
X
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[1., 1., 1.],[1., 1., 1.]], dtype=float32)>
假设至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量。
with try_gpu(1):Y = tf.random.uniform((2, 3))
Y
(2) 复制
如果要计算X + Y,需要决定在哪里执行这个操作。可以将X传输到第二个GPU并在那里执行操作。 不要简单地X加上Y,因为这会导致异常, 运行时引擎不知道该怎么做:它在同一设备上找不到数据会导致失败。 由于Y位于第二个GPU上,所以需要将X移到那里, 然后才能执行相加运算。
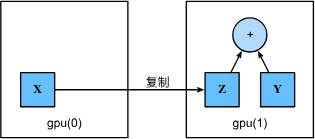
with try_gpu(1):Y = tf.random.uniform((2, 3))
print(Y)with try_gpu(1):Z = X
print(X)
print(Z)#现在数据在同一个GPU上(Z和Y都在),可以将它们相加。
print(Y + Z)
假设变量Z已经存在于第二个GPU上。 如果仍然在同一个设备作用域下调用Z2 = Z会发生什么? 它将返回Z,而不会复制并分配新内存。
with try_gpu(1):Z2 = Z
Z2 is Z
9.3神经网络与GPU
类似地,不仅变量可以指定GPU设备,神经网络模型可以指定GPU设备。
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():net = tf.keras.models.Sequential([tf.keras.layers.Dense(1)])
当输入为GPU上的张量时,模型将在同一GPU上计算结果。
net(X)
确认模型参数存储在同一个GPU上。
net.layers[0].weights[0].device, net.layers[0].weights[1].device
('/job:localhost/replica:0/task:0/device:GPU:0','/job:localhost/replica:0/task:0/device:GPU:0')