激活函数大汇总(一)(Sigmoid & Tanh & ReLU & Leaky ReLU & PReLU附代码和详细公式)
更多激活函数见激活函数大汇总列表
一、引言
欢迎来到我们深入探索神经网络核心组成部分——激活函数的系列博客。在人工智能的世界里,激活函数扮演着不可或缺的角色,它们决定着神经元的输出,并且影响着网络的学习能力与表现力。鉴于激活函数的重要性和多样性,我们将通过几篇文章的形式,每篇详细介绍五种激活函数,旨在帮助读者深入了解各种激活函数的特点、应用场景及其对模型性能的影响。
激活函数的作用与意义: 激活函数在神经网络中的主要作用是引入非线性因素,这使得网络能够学习和模拟复杂的数据关系,如图像、声音和文字等。没有激活函数,神经网络不过是一堆线性回归模型的堆砌,其能力将大大受限。因此,激活函数是实现复杂功能映射、提高网络深度和解决非线性问题的关键。
历史发展: 激活函数的历史可以追溯到神经网络的早期发展阶段。早期常用的激活函数如Sigmoid和Tanh,它们在模拟神经元激活过程时取得了重大进展。随着时间的推移,研究人员发现这些函数在深层网络中存在梯度消失和饱和的问题,这促使了ReLU及其变种的发展。近年来,随着深度学习的快速发展,更多具有创新设计的激活函数被提出,旨在进一步优化网络的性能和训练过程。
在接下来的文章中,我们将逐一探讨各种激活函数,从经典到最新的研究成果。
限于笔者水平,对于本博客存在的纰漏和错误,欢迎大家留言指正,我将不断更新。
二、Sigmoid
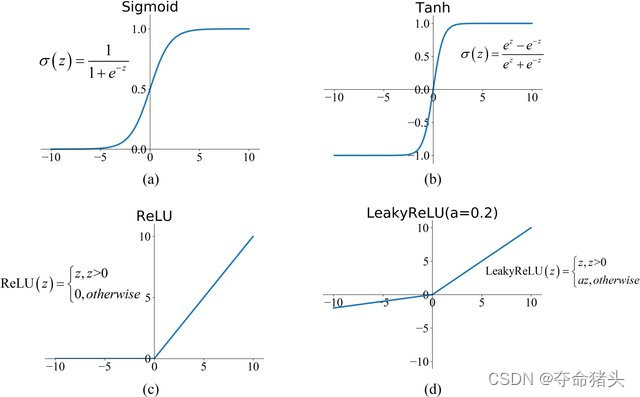
Sigmoid 激活函数是一个广泛应用于神经网络的非线性函数,特别是在二分类问题中。它的数学表达式定义如下:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
其中,(x) 是函数的输入,(e) 是自然对数的底,大约等于2.71828。Sigmoid函数的输出范围在(0, 1)之间,这使得它非常适合将输出解释为概率。
函数特性
- 输出范围:Sigmoid 函数将任何实数值的输入映射到(0, 1)区间内,这意味着其输出可以被解释为概率,非常适用于需要输出概率的场景。
- 非线性:虽然Sigmoid函数在输入接近0时近似线性,但整体上是非线性的。这一特性允许神经网络通过层叠多个激活单元来学习复杂的非线性关系。
- 平滑梯度:Sigmoid函数的导数是关于输出的平滑函数,这使得它在梯度下降和反向传播算法中特别有用。
导数
Sigmoid函数的导数(或梯度)对于神经网络的训练至关重要,因为它影响着权重的调整幅度。Sigmoid函数的导数可以用其输出表示:
σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) ) \sigma'(x) = \sigma(x) \cdot (1 - \sigma(x)) σ′(x)=σ(x)⋅(1−σ(x))
这表明Sigmoid函数的导数可以通过其函数值计算得到,这一性质在实现反向传播算法时非常方便。
使用场景与局限性
尽管Sigmoid函数在早期的神经网络中非常流行,但它也有局限性,特别是梯度消失问题。当输入值很大或很小时,Sigmoid函数的梯度接近于0,这会导致在深度网络中梯度更新非常缓慢,从而影响学习效率。因此,尽管Sigmoid函数在某些场合下仍然有用,但在深度学习中,人们越来越倾向于使用ReLU及其变体作为激活函数。
代码实现
在Python中实现Sigmoid激活函数很直接,可以使用NumPy库来处理数学运算,因为NumPy提供了广泛的数学函数支持,包括指数函数。下面是Sigmoid函数的Python实现及其导数的计算:
import numpy as npdef sigmoid(x):"""计算Sigmoid激活函数的值"""return 1 / (1 + np.exp(-x))def sigmoid_derivative(x):"""计算Sigmoid函数的导数"""sx = sigmoid(x)return sx * (1 - sx)解读
sigmoid(x)函数:这个函数接受一个输入x,可以是一个数值、一个NumPy数组或者一个多维数组。对于输入的每个元素,函数计算1 / (1 + exp(-x)),其中exp是指数函数,计算e的x次幂,e是自然对数的底。这样,无论输入值的大小如何,Sigmoid函数都会将其映射到(0, 1)区间内。sigmoid_derivative(x)函数:这个函数计算Sigmoid函数的导数。首先,它使用sigmoid(x)计算x的Sigmoid值,然后根据导数的公式σ'(x) = σ(x) * (1 - σ(x))进行计算。这里σ(x)就是sigmoid(x)的输出。这个导数反映了Sigmoid函数在x处的变化率,对于神经网络的训练过程(特别是在反向传播算法中更新权重时)来说非常重要。
使用示例
假设你想计算x = 0.5时的Sigmoid函数值及其导数:
x = 0.5
sigmoid_value = sigmoid(x)
sigmoid_derivative_value = sigmoid_derivative(x)print(f"Sigmoid({x}) = {sigmoid_value}")
print(f"Sigmoid Derivative({x}) = {sigmoid_derivative_value}")上面这段代码首先计算x = 0.5时的Sigmoid函数值,然后计算在这一点上的导数。
三、Tanh
Tanh(双曲正切)激活函数是神经网络中常用的另一种非线性激活函数。与Sigmoid函数类似,Tanh函数也能将输入值压缩到一个特定的范围内,但与Sigmoid不同的是,Tanh将输入值压缩到了(-1, 1)的区间。这使得Tanh在某些情况下比Sigmoid更受欢迎,特别是当需要处理正负输入值时,因为它的输出均值接近于0,有助于数据的中心化,进而提高学习效率。
数学定义
Tanh函数的数学表达式定义为:
T a n h ( x ) = ( e x − e − x ) / ( e x + e − x ) Tanh(x) = (e^x - e^{-x}) / (e^x + e^{-x}) Tanh(x)=(ex−e−x)/(ex+e−x)
其中,x是函数的输入,e是自然对数的底。
函数特性
- 输出范围:Tanh函数的输出值介于-1和1之间,这意味着其输出平均值为0,有利于数据的中心化处理。
- 非线性:Tanh函数是非线性的,使其可以作为神经网络中的激活函数,帮助网络捕捉输入数据中的复杂关系和模式。
- 梯度:与Sigmoid函数相比,Tanh函数在其输入值远离0点时梯度消失的问题较小,因为即便输入值较大或较小,其导数值也不会接近于0。
导数
Tanh函数的导数(或梯度)反映了函数输出对输入变化的敏感度,对于神经网络的反向传播算法来说至关重要。Tanh函数的导数可以用其函数值表示:
d ( t a n h ( x ) ) / d x = 1 − t a n h 2 ( x ) d(tanh(x))/dx = 1 - tanh^2(x) d(tanh(x))/dx=1−tanh2(x)
这表明Tanh函数的导数只依赖于函数自身的输出值,这一性质在实现神经网络的反向传播算法时非常有用。
使用场景与局限性
Tanh函数因为其输出均值接近0的特性而被广泛用于隐藏层的激活函数,特别是在需要处理负数输入时。然而,尽管Tanh函数在梯度消失问题上表现得比Sigmoid函数好,但在训练非常深的网络时,仍可能面临梯度消失的问题。因此,在这些情况下,人们可能会选择ReLU及其变体作为激活函数,因为它们能够在一定程度上缓解梯度消失问题,加速网络的训练。
代码实现
在Python中实现Tanh(双曲正切)激活函数同样可以使用NumPy库,NumPy提供了一个直接的函数np.tanh来计算Tanh值。下面是如何在Python中实现Tanh函数及其导数的计算:
import numpy as npdef tanh(x):"""计算Tanh激活函数的值"""return np.tanh(x)def tanh_derivative(x):"""计算Tanh函数的导数"""return 1 - np.tanh(x)**2
解读
-
tanh(x)函数:这个函数利用了NumPy的np.tanh方法来计算给定输入x的Tanh值。输入可以是单个数字、一个NumPy数组或者一个多维数组。对于输入的每个元素,np.tanh方法都会计算其双曲正切值,该值的范围在-1到1之间。 -
tanh_derivative(x)函数:这个函数计算Tanh函数的导数。根据Tanh导数的公式 d / d x ∗ t a n h ( x ) = 1 − t a n h 2 ( x ) d/dx*tanh(x) = 1 - tanh^2(x) d/dx∗tanh(x)=1−tanh2(x),它先计算输入x的Tanh值的平方,然后从1中减去这个值。这样计算出的导数反映了在输入x处,Tanh函数输出对输入的微小变化有多敏感,这对于通过反向传播算法训练神经网络来说非常重要。
使用示例
如果你想要计算某个特定输入值,比如x = 0.5时的Tanh函数值及其导数,你可以这样做:
x = 0.5
tanh_value = tanh(x)
tanh_derivative_value = tanh_derivative(x)print(f"Tanh({x}) = {tanh_value}")
print(f"Tanh Derivative({x}) = {tanh_derivative_value}")
这段代码首先计算给定输入x = 0.5的Tanh值,然后计算该点上的导数。这有助于理解Tanh函数在不同输入值下的行为,以及它是如何影响神经网络中的信息传递和学习过程的。
四、ReLU
ReLU(Rectified Linear Unit)激活函数是深度学习中最为广泛使用的激活函数之一,尤其在卷积神经网络(CNN)和深度前馈神经网络中。其受欢迎的原因主要在于其简单性和在训练深层网络时表现出的效率。
数学定义
ReLU函数定义为:
ReLU ( x ) = max ( 0 , x ) \operatorname{ReLU}(x)=\max (0, x) ReLU(x)=max(0,x)
其中, x x x是函数的输入。
函数特性
- 非线性:尽管ReLU在正数部分看起来是线性的,但它是一个非线性函数,因为对于所有负数输入,输出都是0。这种非线性允许神经网络学习复杂的数据表示。
- 稀疏激活性:由于ReLU在输入小于0时输出为0,它在实践中导致了网络的稀疏激活性。这意味着在任何时刻,网络中的所有神经元都只有一部分是激活的,这有助于减少计算资源的消耗并提高网络的计算效率。
- 解决梯度消失问题:在正数部分,ReLU的梯度恒定不变,这有助于缓解深层网络训练中遇到的梯度消失问题。梯度消失问题是指在训练深层神经网络时,梯度通过多个层反向传播时逐渐变小,导致训练早期层时几乎不更新权重的问题。
导数
ReLU函数的导数如下:
- 当(x > 0)时,导数为1。
- 当(x < 0)时,导数为0。
- 当(x = 0)时,导数未定义(在实践中,这个点可以被认为是0,或者使用一个小的正斜率值)。
数学表示为:
ReLU ′ ( x ) = { 1 if x > 0 0 if x ≤ 0 \operatorname{ReLU}^{\prime}(x)= \begin{cases}1 & \text { if } x>0 \\ 0 & \text { if } x \leq 0\end{cases} ReLU′(x)={10 if x>0 if x≤0
使用场景与局限性
ReLU由于其简单性和效率,在深度学习模型中非常受欢迎。它特别适用于卷积神经网络和深度前馈网络。然而,ReLU也有一些局限性,如死亡ReLU问题(当神经元输出为0时不能进行有效的梯度下降更新),导致一部分神经元可能永远不会被激活。为了解决这些问题,研究人员提出了几种ReLU的变体,如Leaky ReLU、Parametric ReLU (PReLU)和Exponential Linear Unit (ELU)等。
代码实现
实现ReLU函数及其导数的Python代码相对简单,这主要得益于ReLU函数的定义本身就很简单。下面是ReLU函数及其导数的Python实现:
import numpy as npdef relu(x):"""计算ReLU激活函数的值"""return np.maximum(0, x)def relu_derivative(x):"""计算ReLU函数的导数"""return np.where(x > 0, 1, 0)
解读
-
relu(x)函数:这个函数使用了NumPy的np.maximum函数来计算ReLU的输出。np.maximum(0, x)简单地将所有输入x中小于0的值置为0,而保持所有正值不变。这正是ReLU激活函数的定义。 -
relu_derivative(x)函数:该函数使用NumPy的np.where函数来计算ReLU函数的导数。对于输入x中的每个元素,当元素大于0时,其导数为1;否则,导数为0。请注意,对于x = 0的情况,导数在理论上是未定义的,但在实际应用中,通常可以将其视为0或1。这里,我们选择将导数在x <= 0时视为0,与大多数实现保持一致。
使用示例
假设你想对一个数组应用ReLU函数及其导数:
x = np.array([-2, -1, 0, 1, 2])
relu_values = relu(x)
relu_derivatives = relu_derivative(x)print("ReLU values:", relu_values)
print("ReLU derivatives:", relu_derivatives)
这段代码首先定义了一个包含正数和负数的数组x,然后使用relu(x)计算了ReLU激活后的值,接着使用relu_derivative(x)计算了这些值的导数。输出将展示ReLU激活函数将负数转换为0的效果,以及正数保持不变的特性;同时,它也展示了导数在正数处为1,在非正数处为0的特性。
五、Leaky ReLU
Leaky ReLU(Leaky Rectified Linear Unit)是ReLU(Rectified Linear Unit)激活函数的一个变体,旨在解决ReLU激活函数在负值输入时导致的神经元“死亡”问题。与ReLU在负值时直接输出0不同,Leaky ReLU允许负值输入有一个非零的微小斜率,这意味着即使在负值区域,梯度也不会完全消失,从而保持了网络的梯度流。
数学定义
Leaky ReLU的数学表达式定义为:
LeakyReLU ( x ) = { x if x > 0 α x if x ≤ 0 \text { LeakyReLU }(x)= \begin{cases}x & \text { if } x>0 \\ \alpha x & \text { if } x \leq 0\end{cases} LeakyReLU (x)={xαx if x>0 if x≤0
其中, x x x是函数的输入,而 a a a是一个很小的正常数(例如0.01),用于给负值输入一个非零斜率。
函数特性
- 非线性:Leaky ReLU是非线性的,可以帮助神经网络学习复杂的数据表示。
- 改善梯度消失问题:通过为负值输入提供一个小的正斜率,Leaky ReLU有助于减轻梯度消失问题,尤其是在深层网络中。
- 稀疏激活性:虽然Leaky ReLU减轻了死亡ReLU问题,但它仍然保持了部分ReLU的稀疏激活性,这有助于保持网络的计算效率。
导数
Leaky ReLU函数的导数如下:
LeakyReLU ′ ( x ) = { 1 if x > 0 α if x ≤ 0 \operatorname{LeakyReLU}^{\prime}(x)= \begin{cases}1 & \text { if } x>0 \\ \alpha & \text { if } x \leq 0\end{cases} LeakyReLU′(x)={1α if x>0 if x≤0
这意味着在正数区域,梯度为1,保持了ReLU的特性;而在负数区域,梯度为一个小的正值 a a a,而不是0,这有助于在训练过程中保持梯度流。
使用场景与局限性
Leaky ReLU通常用于试图解决由于ReLU导致的神经元死亡问题的场景。虽然它在某些情况下比标准的ReLU表现得更好,但最佳的激活函数选择还是依赖于具体的应用场景和任务。实践中,Leaky ReLU和其他ReLU变体(如Parametric ReLU和Exponential Linear Unit)的效果可能会有所不同,因此通常建议在具体的应用中进行实验,以确定哪种激活函数最适合特定的神经网络架构和数据集。
代码实现
实现Leaky ReLU激活函数及其导数的Python代码非常直接,以下是如何用Python进行实现:
import numpy as npdef leaky_relu(x, alpha=0.01):"""计算Leaky ReLU激活函数的值。参数:x -- 输入值,可以是一个数值、NumPy数组或者多维数组。alpha -- 负值斜率系数,默认为0.01。返回:Leaky ReLU激活后的结果。"""return np.where(x > 0, x, alpha * x)def leaky_relu_derivative(x, alpha=0.01):"""计算Leaky ReLU函数的导数。参数:x -- 输入值,可以是一个数值、NumPy数组或者多维数组。alpha -- 负值斜率系数,默认为0.01。返回:Leaky ReLU导数的结果。"""return np.where(x > 0, 1, alpha)
解读
-
leaky_relu(x, alpha=0.01)函数:此函数接受一个输入x,该输入可以是一个单独的数值、一个NumPy数组或者一个多维数组。它还接受一个可选参数alpha,表示当x为负时的斜率,默认值为0.01。函数使用np.where操作,对于x中的每个元素,当条件(x > 0)为真时,输出x本身;否则输出alpha * x。 -
leaky_relu_derivative(x, alpha=0.01)函数:此函数计算Leaky ReLU函数的导数。与激活函数实现类似,它采用相同的输入x和alpha参数。导数计算同样使用np.where操作,当x大于0时,导数为1;否则为alpha。
示例使用
假设你有一组输入数据x,你想要计算它们的Leaky ReLU激活值及其导数:
x = np.array([-1.5, -0.5, 0, 0.5, 1.5])
leaky_relu_values = leaky_relu(x)
leaky_relu_derivatives = leaky_relu_derivative(x)print("Leaky ReLU Values:", leaky_relu_values)
print("Leaky ReLU Derivatives:", leaky_relu_derivatives)
这段代码首先定义了一个包含负数、零和正数的输入数组x,然后使用定义的leaky_relu和leaky_relu_derivative函数计算每个元素的Leaky ReLU值和导数。这个例子展示了如何在实际应用中使用Leaky ReLU激活函数及其导数来处理数据。
六、PReLU
PReLU(Parametric Rectified Linear Unit)激活函数是Leaky ReLU激活函数的一个变种,它引入了一个可学习的参数,使得在训练过程中可以自适应地调整负值部分的斜率。这种设计旨在结合ReLU的优点,同时减轻其潜在的缺点,如神经元的“死亡”。
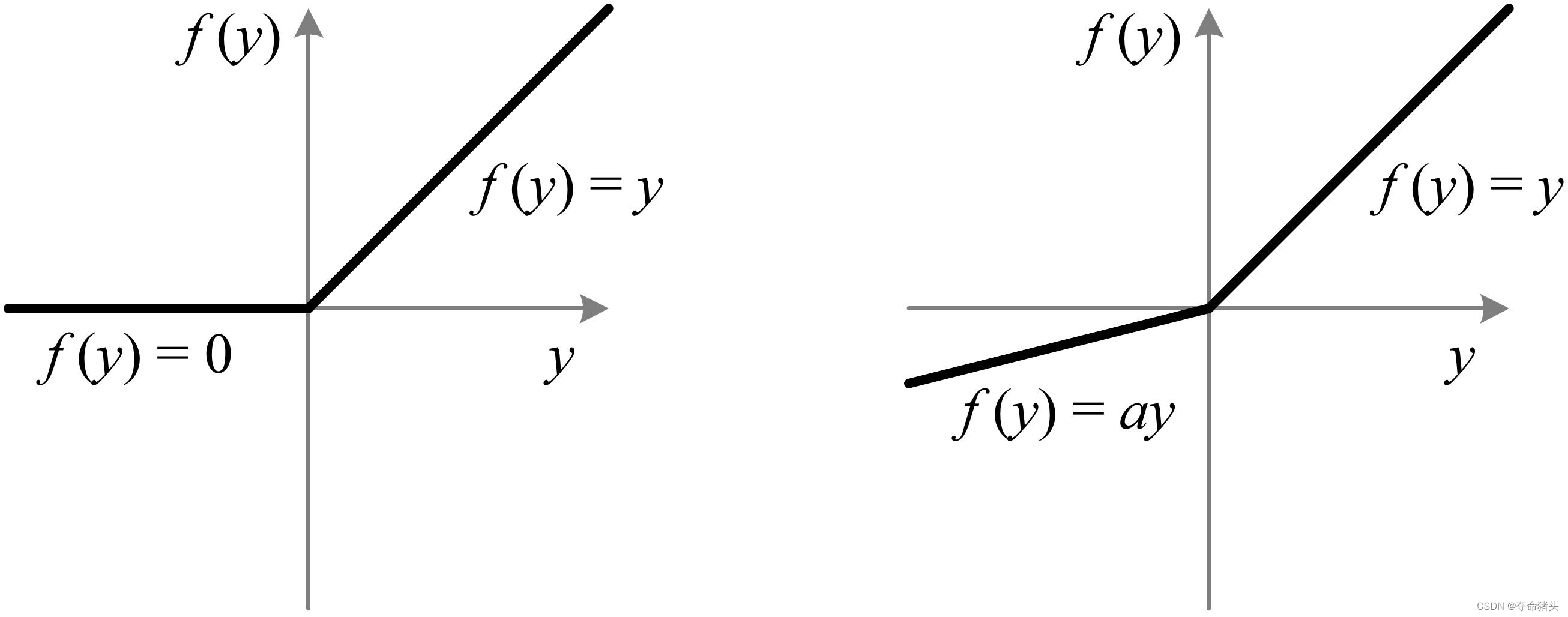
数学定义
PReLU函数的数学表达式定义为:
PReLU ( x ) = { x if x > 0 α x if x ≤ 0 \operatorname{PReLU}(x)= \begin{cases}x & \text { if } x>0 \\ \alpha x & \text { if } x \leq 0\end{cases} PReLU(x)={xαx if x>0 if x≤0
与Leaky ReLU类似, x x x是函数的输入。不同之处在于, a a a不再是一个预设的常数,而是一个可学习的参数,其值通过网络训练过程自动调整。
函数特性
- 非线性:PReLU保持了ReLU的非线性特性,使其能够帮助神经网络学习复杂的数据表示。
- 自适应学习负值斜率:通过使 a a a成为可学习的参数,PReLU允许网络根据训练数据自动调整负值部分的斜率,这可能导致更好的模型性能和学习效率。
- 改善梯度消失问题:和Leaky ReLU一样,PReLU在处理负值输入时提供了非零梯度,有助于减轻梯度消失问题,尤其是在深层网络中。
导数
PReLU函数的导数如下:
PReLU ′ ( x ) = { 1 if x > 0 α if x ≤ 0 \operatorname{PReLU}^{\prime}(x)= \begin{cases}1 & \text { if } x>0 \\ \alpha & \text { if } x \leq 0\end{cases} PReLU′(x)={1α if x>0 if x≤0
这里的 a a a是与输入相同维度的参数,意味着对于网络中的每个神经元或每个通道, a a a可以独立学习。
使用场景与局限性
PReLU通常用于希望网络能够从数据中自动学习负值斜率的场景,这在实践中有可能提供比固定斜率(如ReLU或Leaky ReLU)更优的性能。然而,由于 a a a是可学习的,PReLU增加了模型的参数数量,这可能导致过拟合,特别是在数据量较少的情况下。因此,使用PReLU时需要仔细调节正则化和其他避免过拟合的技术。
代码实现
实现PReLU激活函数需要考虑到 a a a参数是可学习的,这意味着它应当作为模型训练的一部分进行优化。在一个简单的Python实现中,我们可以使用NumPy来模拟这一行为,尽管在实践中, a a a通常由深度学习框架(如TensorFlow或PyTorch)在训练过程中自动更新。
以下是一个简化的PReLU函数实现,它接受输入 x x x和参数 a a a,返回PReLU的激活值。请注意,这里的被 a a a视为一个已知的参数,而非训练过程中学习得到的:
import numpy as npdef prelu(x, alpha=0.01):"""计算PReLU激活函数的值。参数:x -- 输入值,可以是一个数值、NumPy数组或者多维数组。alpha -- 可学习的负值斜率参数,默认为0.01。返回:PReLU激活后的结果。"""return np.where(x > 0, x, alpha * x)
解读
prelu(x, alpha=0.01)函数:此函数接受输入 x x x,可以是一个单一数值或者NumPy数组。参数 a a a代表当 x x x小于等于0时的斜率,这是一个可学习的参数,但在这个简单实现中,我们将其视为一个固定的值。函数使用np.where操作来选择性地应用正值或是乘以 a a a的负值,这与PReLU的定义相匹配。
注意
这个简单实现并不涉及 a a a的学习过程,它假设 a a a是一个给定的参数。在实际的深度学习框架中, a a a会作为模型参数之一,通过反向传播和梯度下降等优化算法进行更新。
为了在深度学习模型中使用可学习的 a a a,你需要使用支持自动梯度计算和参数优化的库,如PyTorch或TensorFlow。这些框架提供了内建的PReLU实现,其中 a a a自动作为模型训练的一部分进行优化。
在TensorFlow中,你可以使用tf.keras.layers.PReLU来实现具有可学习参数 a a a的PReLU激活函数。tf.keras是一个高级神经网络API,它允许以相对简单的方式构建、训练和部署机器学习模型。
以下是一个简单的例子,演示如何在TensorFlow中使用PReLU:
import tensorflow as tf
from tensorflow.keras.layers import Dense, PReLU
from tensorflow.keras.models import Sequential# 构建一个简单的模型
model = Sequential([Dense(64, input_shape=(784,)), # 假设我们的输入是一个784维的向量PReLU(alpha_initializer='zeros'), # 使用PReLU作为激活函数Dense(10, activation='softmax') # 假设这是一个10分类问题
])# 编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])# 打印模型概要
model.summary()
关键点
PReLU层:在这个例子中,PReLU被用作第一个Dense层后的激活函数。alpha_initializer参数决定了 a a a参数的初始值,这里使用'zeros'表示初始时 a a a被设置为0。TensorFlow提供多种初始化器,允许你根据需要自定义 a a a的初始状态。- 模型构建:这个例子中使用的是
Sequential模型,这是一种简单的线性堆叠模型。首先添加一个具有64个单元的全连接层(Dense),然后是一个PReLU激活层,最后是输出层,使用softmax激活函数进行多分类。 - 编译模型:通过
compile方法编译模型时,你需要指定优化器(这里使用adam)、损失函数(对于多分类问题常用categorical_crossentropy)和评估标准(这里使用accuracy)。
训练模型
要训练模型,你需要准备数据集并调用fit方法。假设你已经有了训练数据X_train和y_train,以及验证数据X_val和y_val,训练过程大概像这样:
model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10, batch_size=32)
在训练过程中,TensorFlow将自动调整 a a a参数,以及模型中的其他可学习参数,以最小化损失函数。通过这种方式,PReLU的 a a a参数将根据数据自适应地优化,有助于提升模型的性能。
七、参考文献
Sigmoid & Tanh
- Cybenko, G. (1989). “Approximation by superpositions of a sigmoidal function.” Mathematics of Control, Signals, and Systems (MCSS), 2(4), 303-314.
- LeCun, Y., Bottou, L., Orr, G. B., & Müller, K. R. (1998). “Efficient backprop.” In Neural networks: Tricks of the trade (pp. 9-50). Springer, Berlin, Heidelberg.
ReLU
- Nair, V., & Hinton, G. E. (2010). “Rectified linear units improve restricted boltzmann machines.” In Proceedings of the 27th International Conference on Machine Learning (ICML-10), 807-814.
- Glorot, X., Bordes, A., & Bengio, Y. (2011). “Deep sparse rectifier neural networks.” In Proceedings of the fourteenth international conference on artificial intelligence and statistics, 315-323.
Leaky ReLU
- Maas, A. L., Hannun, A. Y., & Ng, A. Y. (2013). “Rectifier nonlinearities improve neural network acoustic models.” In Proc. icml, volume 30, page 3.
PReLU
- He, K., Zhang, X., Ren, S., & Sun, J. (2015). “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” In Proceedings of the IEEE international conference on computer vision, 1026-1034.
综合与综述文章
- Goodfellow, I., Bengio, Y., Courville, A. (2016). “Deep Learning.” MIT Press. 链接 - 提供深度学习中各种激活函数的综合概述。
- Ramachandran, P., Zoph, B., & Le, Q. V. (2017). “Searching for activation functions.” arXiv preprint arXiv:1710.05941. - 探索了自动搜索激活函数的新方法,并提出了Swish函数。
- Xu, B., Wang, N., Chen, T., & Li, M. (2015). “Empirical Evaluation of Rectified Activations in Convolution Network.” arXiv preprint arXiv:1505.00853. - 比较了ReLU及其变体在卷积网络中的表现。