引言
在当今的信息时代,互联网上的数据如同浩瀚的海洋,充满了无尽的宝藏。Python爬虫作为一种高效的数据抓取工具,能够帮助我们轻松地获取这些数据,并进行后续的分析和处理。本文将深入探讨Python爬虫的原理,并结合实战案例,帮助读者快速掌握爬虫技术。
一、Python爬虫原理
1、爬虫是什么?
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
2、爬虫的基本流程
Python爬虫的核心原理是通过模拟浏览器的行为,自动访问目标网站,并抓取其中的数据。这个过程主要包括以下几个步骤:
- 发送请求:使用Python中的第三方库(如requests)向目标网站发送HTTP请求,获取网页的HTML代码。
- 解析网页:利用Python的解析库(如BeautifulSoup、lxml等)对获取的HTML代码进行解析,提取出所需的数据。
- 存储数据:将解析得到的数据存储到本地文件、数据库或其他存储介质中,以便后续分析和处理。
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
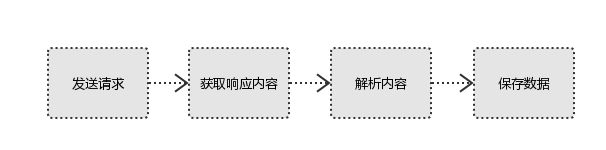
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
接下来,我们将通过一个实战案例来演示如何使用Python爬虫抓取目标网站的数据。
3、客户端HTTP请求格式
在网络传输中HTTP协议非常重要,该协议规定了客户端和服务器端请求和应答的标准。HTTP协议能保证计算机正确快速地传输超文本文档,并确定了传输文档中的哪一部分,以及哪一部分内容首先显示(如文本先于图形)等。
根据HTTP协议的规定,客户端发送了一个HTTP请求到服务器的请求消息,由请求行、请求头部、空行以及请求数据四个部分组成。


下面结合一个典型的HTTP请求示例,详细介绍HTTP请求信息的各个组成部分:
Get https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: https://www.baidu.com/link?url=8vUrPYDUaSkXWxUEOlT8QhvB5kMr1o6I27EP0NJICmG&wd=&eqid=e69078350001654000000003641051fc
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BIDUPSID=498703BAB592E42B1A4200A2F69121AD; PSTM=1657099499; MCITY=-291%3A; BAIDUID=498703BAB592E42BC6776C4114ED28E6:SL=0:NR=10:FG=1; BD_UPN=12314753; BDUSS=J5OEFjZ3pBb05tR3QxNUo0TEVJdjVpYzQ5Q2FORC04TnlrMHhFYkhRMnNKeGxrRVFBQUFBJCQAAAAAAQAAAAEAAAAXv8pawrfIy73U1qpUYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKya8WOsmvFjLT; BDUSS_BFESS=J5OEFjZ3pBb05tR3QxNUo0TEVJdjVpYzQ5Q2FORC04TnlrMHhFYkhRMnNKeGxrRVFBQUFBJCQAAAAAAQAAAAEAAAAXv8pawrfIy73U1qpUYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKya8WOsmvFjLT;(1)请求行
第一行为请求行,包含了请求的方法,URL地址和协议版本。GET是请求方法,https://www.baidu.com是URL地址,HTTP/1.1指定了协议版本。
不同的请求方法含义不同,如下:
| 序号 | 方法 | 描述 |
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | POST | 向指定资源提交数据进行处理请求(如提交表单或者上传文件),数据被包含在请求体中。Post请求可能会导致新的资源的建立和已有资源的修改 |
| 3 | HEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 4 | PUT | 这种请求方式下,从客户端向服务器传送的数据取代指定的文档的内容 |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | CONNECT | HTTP1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | OPTIONS | 允许客服端查看服务器的性能 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
其中GET和POST请求最常用,区别在于:
GET是从服务器上获取指定页面信息,POST是向服务器提交数据并获取页面信息。
GET请求参数都显示在URL上,服务器根据该请求所包含URL中的参数来产生响应内容。由于请求参数都暴露在外,所以安全性不高。
POST请求参数在请求体中,消息长度没有限制而且采取隐式发送,通常用来向HTTP服务器提交量比骄大的数据(如请求中包含许多参数或者文件上传的操作)POST请求的参数不在URL中,而在请求体中,在安全性方面比GET请求要高。
(2)请求报头
请求行下是若干个请求报头,下面介绍常用的请求报头及含义:
Host(主机和端口号):指定被请求的资源的Internet主机和端口号,对应网址URL中的Web名称和端口号,通常属于URL的Host部分。
Connection(连接类型):表示客户端与服务端的连接类型。
Upgrade-Insecure-Requests(升级为HTTPS请求):表示升级不安全的请求,会在加载HTTP资源时自动替换成HTTPS请求,让浏览器不再显示HTTPS页面中的HTTP请求警报。HTTPS时以安全为目标的HTTP通道,所以在HTTPS承载的页面上不允许出现HTTP请求,一旦出现就会提示或报错。
User-Agent(浏览器名称):表示客户端身份的名称,通常页面会根据不同的User-Agent信息自动做出适配,甚至返回不同的响应内容。
Accept(传输文件类型):指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions,多用途因特网邮件扩展)文件类型,服务器可以根据他判断并返回适当的文件格式
Referer(页面跳转来源):表明产生请求的网页来自于哪个URL,用户是从该Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站下载下来的,有时下载某网站的图片时,需要对应的Referer,否则是无法下载图片,那是因为做了防盗链。原理就是根据Referer去判断URL是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载。
4. 服务器HTTP响应格式
HTTP响应报文由四部分组成,分别是状态行,响应报头,空行和响应正文。
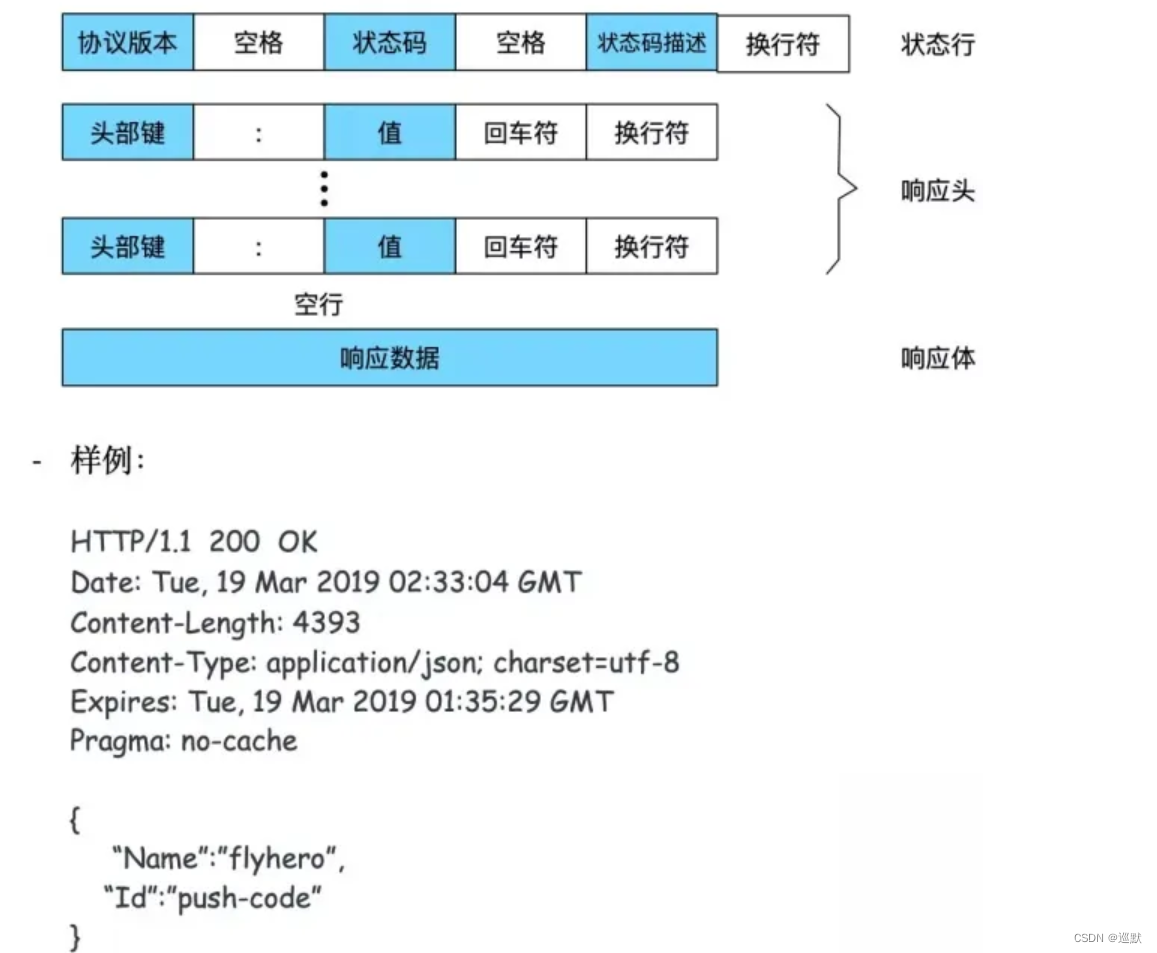
响应状态码
响应状态码由3位数字组成,其中第一位数字定义了响应的类别,有5种可能取值,常见的响应状态码如下:
100~199:表示服务器成功接收部分请求,要求客户端继续提价奥其余请求才能完成整个处理过程。
200~299:表示服务器成功接受请求并已完成整个处理过程。常用的状态码为200(表示OK,请求成功)。
200~399:为完成请求,客户需进一步细化请求。例如,请求的资源已经移动到一个新的地址。常用状态码包括302(表示所请求的页面已经临时转移至新的URL)、307和304(表示使用缓存资源)。
400~499:客户端的请求有错误,常用状态码包括404(表示服务器无法找到被请求的页面)和403(表示服务器拒绝访问,权限不够)。
500~599:服务器端出现错误,常用的状态码为500(表示请求未完成,服务器遇到不可预知的情况)。
二、Python爬虫实战
2、实战案例:抓取豆瓣电影Top250榜单
1. 发送请求
首先,我们需要向豆瓣电影Top250榜单的URL发送请求,获取网页的HTML代码。这里我们使用requests库来实现:
import requests url = 'https://movie.douban.com/top250'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = response.text2. 解析网页
接下来,我们需要对获取的HTML代码进行解析,提取出电影榜单的数据。这里我们使用BeautifulSoup库来实现:
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find_all('div', class_='item') for movie in movie_list: title = movie.find('span', class_='title').text info = movie.find('p').text.strip().split('\n') rating_num = float(movie.find('span', class_='rating_num').text) print(f'标题:{title}') print(f'信息:{info}') print(f'评分:{rating_num}') print('----')3. 存储数据
最后,我们可以将解析得到的数据存储到本地文件中,以便后续分析和处理:
with open('douban_top250.txt', 'w', encoding='utf-8') as f: for movie in movie_list: title = movie.find('span', class_='title').text info = movie.find('p').text.strip().split('\n') rating_num = float(movie.find('span', class_='rating_num').text) f.write(f'标题:{title}\n') f.write(f'信息:{info}\n') f.write(f'评分:{rating_num}\n') f.write('----\n')三、注意事项与总结
在使用Python爬虫时,我们需要注意以下几点:
- 遵守robots.txt协议:在爬取网站数据时,要遵守目标网站的robots.txt协议,避免对网站造成不必要的负担。
- 设置合理的请求频率和间隔时间:为了避免对目标网站造成过大的压力,我们需要设置合理的请求频率和间隔时间。
- 处理反爬虫机制:一些网站会采用反爬虫机制来防止数据被抓取,我们需要采取相应的措施来绕过这些机制。
- 尊重数据版权:在爬取和使用数据时,要尊重数据的版权和隐私,避免侵犯他人的权益。
总结来说,Python爬虫是一种强大的数据抓取工具,通过掌握其原理和实战技巧,我们可以轻松地获取互联网上的数据,并进行后续的分析和处理。然而,在使用爬虫时,我们也需要遵守相关的规定和注意事项,确保数据的合法性和安全性。