一、环境准备
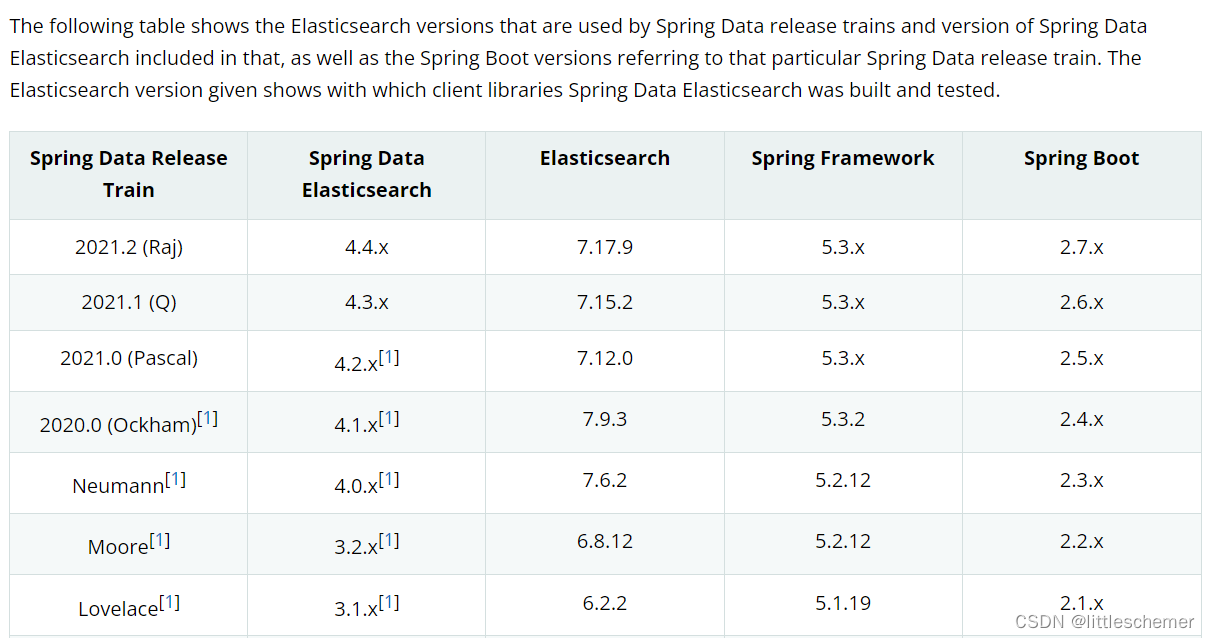
springboot与elasticsearch的更新都非常快,为了避免兼容性问题,要注意下选择的版本问题。具体的可参考官网 --> springboot与elasticsearch版本兼容性
1.1导入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId><version>2.7.18</version></dependency><dependency><groupId>jakarta.json</groupId><artifactId>jakarta.json-api</artifactId><version>2.0.1</version></dependency>
</dependencies>1.2application.properties文件配置
spring.elasticsearch.rest.uris=http://localhost:9200
spring.elasticsearch.rest.username=dev
spring.elasticsearch.rest.password=1234561.3创建实体对象
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "employee")
@Data
public class Employee {@Idprivate int id;@Field(name = "name")private String name;@Field(name = "addr", type = FieldType.Keyword)private String addr;}
该实体类加上@Document注解之后,程序启动后就会自动向ED发送创建索引的请求(若没有则创建)。
1.4创建Repository接口
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface EmployeeRepository extends ElasticsearchRepository<Employee, Integer> {
}
1.5Crud测试案例
使用该接口可方便对索引进行增删查改。例子比较简单,我们直接写个单元测试。代码如下:
import gamecontext.admin.elasticsearch.Employee;
import gamecontext.admin.elasticsearch.EmployeeRepository;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;@SpringBootTest()
@RunWith(SpringRunner.class)
public class ElasticsearchTest {@Autowiredprivate EmployeeRepository repository;@Testpublic void testSave() {Employee p = new Employee();p.setId(3);p.setAddr("北京");p.setName("Tim");repository.save(p);Assert.assertEquals("Tim", repository.findById(3).get().getName());}@Testpublic void testDelete() {Employee p = new Employee();p.setId(4);p.setAddr("北京");p.setName("Tim");repository.save(p);repository.deleteById(4);Assert.assertFalse(repository.findById(4).isPresent());}@Testpublic void testUpdate() {Employee p = repository.findById(3).get();p.setName("南京");repository.save(p);Assert.assertEquals(repository.findById(3).get().getName(), "南京");}}二、使用QueryBuilder进行文档的复杂查询
ElasticsearchRepository只能对文档进行简单的增删查改,如果遇到复杂的全文搜索,则需要借助QueryBuilder和ElasticsearchRestTemplate相关API
2.1数据准备
往索引插入3条文档,数据如下

2.2进行must查询
import gamecontext.admin.elasticsearch.Employee;
import gamecontext.admin.elasticsearch.EmployeeRepository;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.test.context.junit4.SpringRunner;@SpringBootTest()
@RunWith(SpringRunner.class)
public class ElasticsearchTest2 {@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;@Testpublic void testMust() {NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.matchQuery("name", "李")).must(QueryBuilders.matchQuery("name", "四"));nativeSearchQueryBuilder.withQuery(boolQueryBuilder);SearchHits<Employee> hits = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), Employee.class);Assert.assertTrue(hits.stream().findFirst().isPresent());Assert.assertEquals(hits.stream().findFirst().get().getContent().getName(), "李四");}
}等效的Kibana命令

2.3进行range查询
@Testpublic void testRange() {NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();RangeQueryBuilder builder = QueryBuilders.rangeQuery("age").lte(20).gte(10);nativeSearchQueryBuilder.withQuery(builder);SearchHits<Employee> hits = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), Employee.class);Assert.assertEquals(2, hits.getTotalHits());}等效的Kibana命令

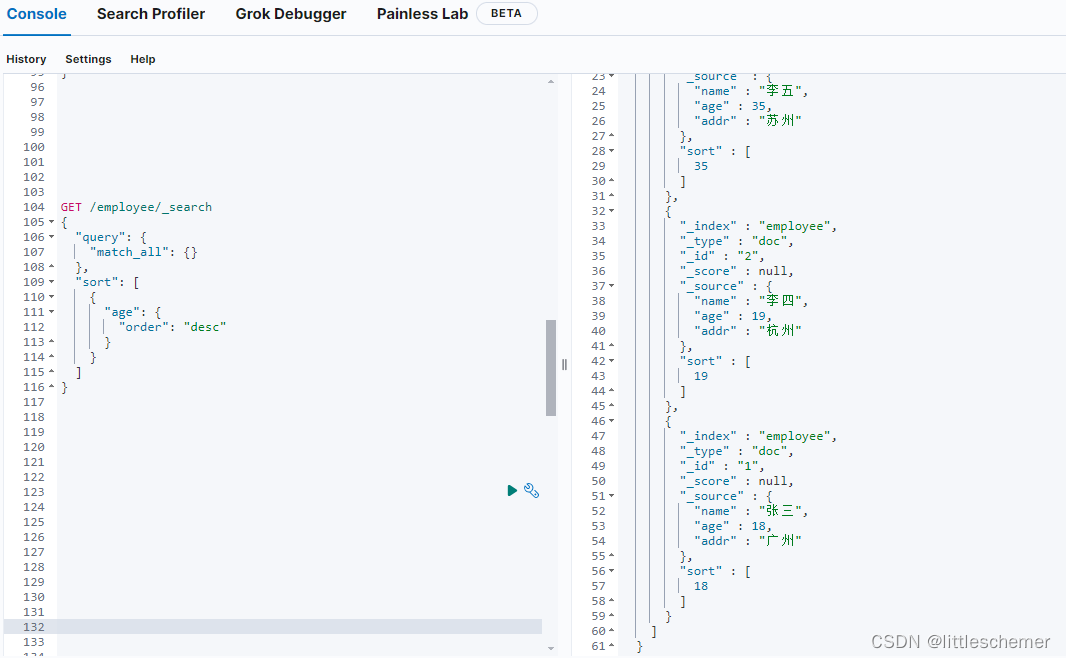
2.4进行sort排序
@Testpublic void testSort() {NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();nativeSearchQueryBuilder.withQuery(QueryBuilders.matchAllQuery());nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("age").order(SortOrder.DESC));
// .withSort(SortBuilders.fieldSort("name").order(SortOrder.ASC));SearchHits<Employee> hits = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), Employee.class);Employee p1 = hits.stream().findFirst().get().getContent();List<SearchHit<Employee>> list = hits.stream().collect(Collectors.toUnmodifiableList());Assert.assertTrue(list.get(0).getContent().getAge()>list.get(1).getContent().getAge());Assert.assertTrue(list.get(1).getContent().getAge()>list.get(2).getContent().getAge());}等效的Kibana命令
默认情况下,text类型的字段是不能排序的,否则会报以下异常,
Caused by: ElasticsearchException[Elasticsearch exception [type=illegal_argument_exception, reason=Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [name] in order to load field data by uninverting the inverted index. Note that this can use significant memory.]]翻译如下:
默认情况下,文本字段禁用字段数据。在[region]上设置fielddata=true,以便通过取消反转索引将fielddata加载到内存中。请注意,这可能会占用大量内存。解决方法:
- 将name字段设置为keyword类型
- 将name字段的fielddata()为true
2.5进行文本高亮
可以使用HighlightBuilder 类来设置查询结果文本高亮
@Testpublic void testHighlight() {String PRE_TAG = "<mark>";String POST_TAG = "</mark>";HighlightBuilder.Field titleField = new HighlightBuilder.Field("name");titleField.preTags(PRE_TAG);titleField.postTags(POST_TAG);NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.matchQuery("name", "李"));nativeSearchQueryBuilder.withQuery(boolQueryBuilder);nativeSearchQueryBuilder.withHighlightFields(titleField);SearchHits<Employee> search = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), Employee.class);Map<String, List<String>> files = search.getSearchHits().stream().findFirst().get().getHighlightFields();Assert.assertFalse(CollectionUtils.isEmpty(files));}