地理空间数据聚类是空间分析和地理信息系统(GIS)领域的一项关键技术。这种方法对于理解地理数据固有的空间模式和结构、促进城市规划、环境管理、交通和公共卫生等各个领域的决策过程至关重要。本文探讨了地理空间数据聚类的概念、方法、应用、挑战和未来方向。
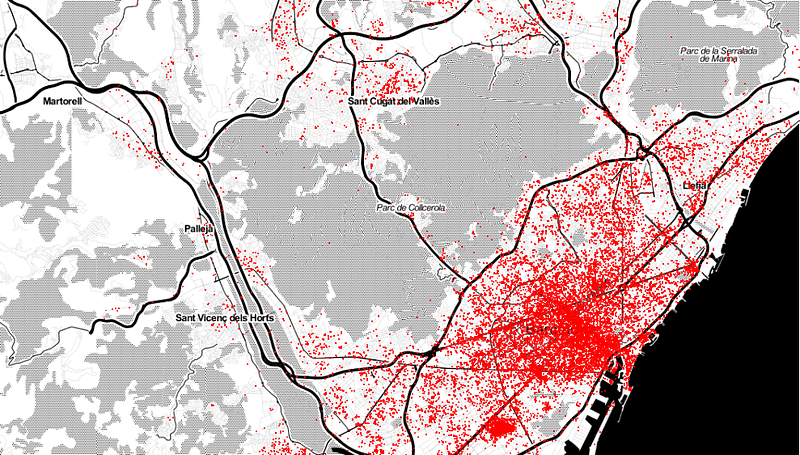
当模式出现时,理解就会随之而来:地理空间数据聚类的艺术揭示了我们世界中看不见的挂毯。
概念和重要性
聚类涉及对一组对象进行分组,使得同一组(或簇)中的对象彼此比其他组中的对象更相似。在地理空间数据的背景下,聚类旨在识别某些现象集中的区域。例如,它可以揭示空气污染热点、犯罪率高的地区或土地利用类似的地区。这对于揭示并非立即显现的模式、促进有针对性的干预措施和有效的资源分配至关重要。
方法论
多种聚类算法广泛用于地理空间数据分析。这些包括:
- K-means 聚类:一种流行的方法,它将 n 个观测值划分为 k 个簇,其中每个观测值属于具有最接近均值的簇。然而,它需要提前指定簇的数量,并且对于非圆形簇形状可能表现不佳。
- DBSCAN(基于密度的噪声应用空间聚类):该算法将紧密堆积的点分组在一起,并将单独位于低密度区域的点标记为异常值。由于它能够处理任意形状的簇和噪声的存在,因此它对于地理空间数据特别有用。
- 层次聚类:以聚合方式(自下而上)或分裂方式(自上而下)构建集群层次结构。这种方法对于地理空间数据是