目录
- 1. 新建管道类,并启用
- 2. 准备好mysql数据库新建表
- 3. 实现管道写入数据库的代码
- 测试一下
- 总结
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
如果对mysql和+python不熟悉可看专栏【Python之pymysql库学习】
1. 新建管道类,并启用
在 Scrapy 中,Item Pipeline 中的方法执行顺序一般会按照以下步骤进行:
- open_spider:在 Spider 开始爬取时调用,用于初始化操作。
- from_crawler:在创建 Pipeline 实例时调用,可以获取 Crawler 对象中的配置信息。
- process_item:处理爬取到的 item 数据的主要方法,会在 Spider 返回 item 数据后被调用。
- process_spider_input:处理来自 Spider 的输入数据。
- process_spider_output:处理 Spider 输出的数据。
- process_spider_exception:处理 Spider 抛出的异常。
- get_media_requests:从 item 中提取需要下载的媒体文件的 Request 对象。
- close_spider:在 Spider 结束爬取时调用,用于清理操作。
这些方法的执行顺序并不是严格固定的,但通常遵循上述顺序。你可以根据自己的需求选择性地实现这些方法来对爬取到的数据进行处理和操作。
pipelines.py新增标准的模板,以后写新的管道直接cv这个模板
#用于将数据存入mysql的类
class DBPipeline:# 初始化def __init__(self):pass# 开始爬虫时候要进行的操作def open_spider(self, spider):pass# 处理爬取到的数据并进行后续处理def process_item(self, item, spider):pass# 关闭爬虫时候要进行的操作def close_spider(self, spider):pass
setting.py新增
# 配置数据管道
ITEM_PIPELINES = {'myscrapy.pipelines.DBPipeline': 200, #数据库管道'myscrapy.pipelines.MyscrapyPipeline': 300, #数字越小先执行,后期可以有多个管道# '你的项目名.pipelines.刚刚管道的类名': 权重, #权重越小先执行,后期可以有多个管道
}
2. 准备好mysql数据库新建表
数据库mzh_scrapy,数据表tb_top_movie
建表代码,注意是反引号不是单引号
USE mzh_scrapy;DROP TABLE IF EXISTS tb_top_movie;CREATE TABLE tb_top_movie (`mov_id` INT UNSIGNED AUTO_INCREMENT COMMENT '编号',`title` VARCHAR(50) NOT NULL COMMENT '标题',`score` DECIMAL(3,1) NOT NULL COMMENT '评分',`quato` VARCHAR(200) DEFAULT '' COMMENT '评价',PRIMARY KEY (`mov_id`)
) ENGINE=InnoDB COMMENT='top电影表';
3. 实现管道写入数据库的代码
安装库
pip install pymysql
有一个经典问题,什么时候提交数据到数据库,有两种写法,大家自行取舍self.cursor.commit()写在什么位置.
import openpyxl
import pymysql
#用于将数据存入mysql的类
class DBPipeline:# 初始化def __init__(self):self.conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='123456',database='mzh_scrapy',charset='utf8mb4')self.cursor=self.conn.cursor()# 开始爬虫时候要进行的操作def open_spider(self, spider):pass# 处理爬取到的数据并进行后续处理def process_item(self, item, spider):title=item.get('title',"")#如果没有获取到标题,默认空score=item.get('score',0)#如果没有获取到评分,默认0quato=item.get('quato',"")#如果没有获取到评价默认空self.cursor.execute('insert into tb_top_movie(title,score,quato) values (%s,%s,%s)',(title,score,quato))#把数据存入缓冲区# self.conn.commit()#把数据缓冲区的数据提交到数据库,如果写在这里就是一行数据一行数据的提交# 一行一行提交对于整体效率来说变低了,但是数据安全一点return item #为什么是return? 我们要让这个管道先,return会把item数据传递给下一个管道用于保存excel的# 关闭爬虫时候要进行的操作def close_spider(self, spider):self.conn.commit()#把数据缓冲区的数据提交到数据库,把之前所有数据缓冲区的数据一次性提交#一次性提交如果系统性能高有利于提高性能,但有数据丢失的风险self.conn.close()
测试一下
Scrapy crawl douban
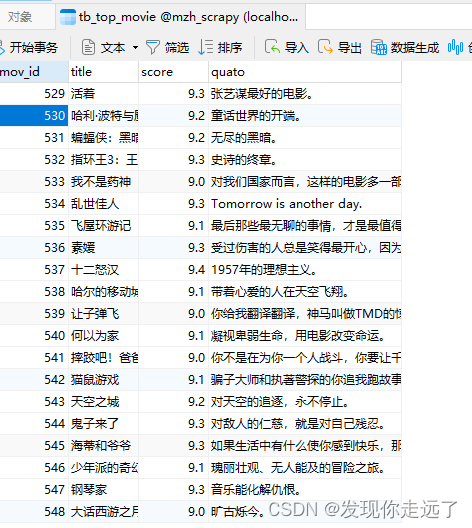
这里的我的编号是500-750主要是因为我们这个数据是最后一次性存入的,我不小心运行了多次`````相同的数据在mysql中又覆盖掉了,但是编号自动编号会增加.
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2024 mzh
Crated:2024-3-1
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
『未完待续』




![[蓝桥杯练习题]确定字符串是否包含唯一字符/确定字符串是否是另一个的排列](https://img-blog.csdnimg.cn/direct/03007ca25d4e46a28e136723e476fa20.png)