GeoChat : Grounded Large Vision-Language Model for Remote Sensing
一、引言
GeoChat,将多模态指令调整扩展到遥感领域以训练多任务会话助理。
遥感领域缺乏多模式指令调整对话数据集。受到最近指令调优工作的启发,GeoChat 使用 Vicuna-v1.5和自动化管道来生成包含近 318k 指令的各种遥感多模式指令跟踪数据。
我们从为不同任务开发的各种现有遥感数据集创建图像文本对。其中包括用于 VQA 的 LRBEN、用于场景分类的 NWPU-RESISC-45 和用于对象检测的 SAMRS。
GeoChat 的一项关键功能是在单个pipline中统一 RS 图像的多个图像和区域级推理任务:

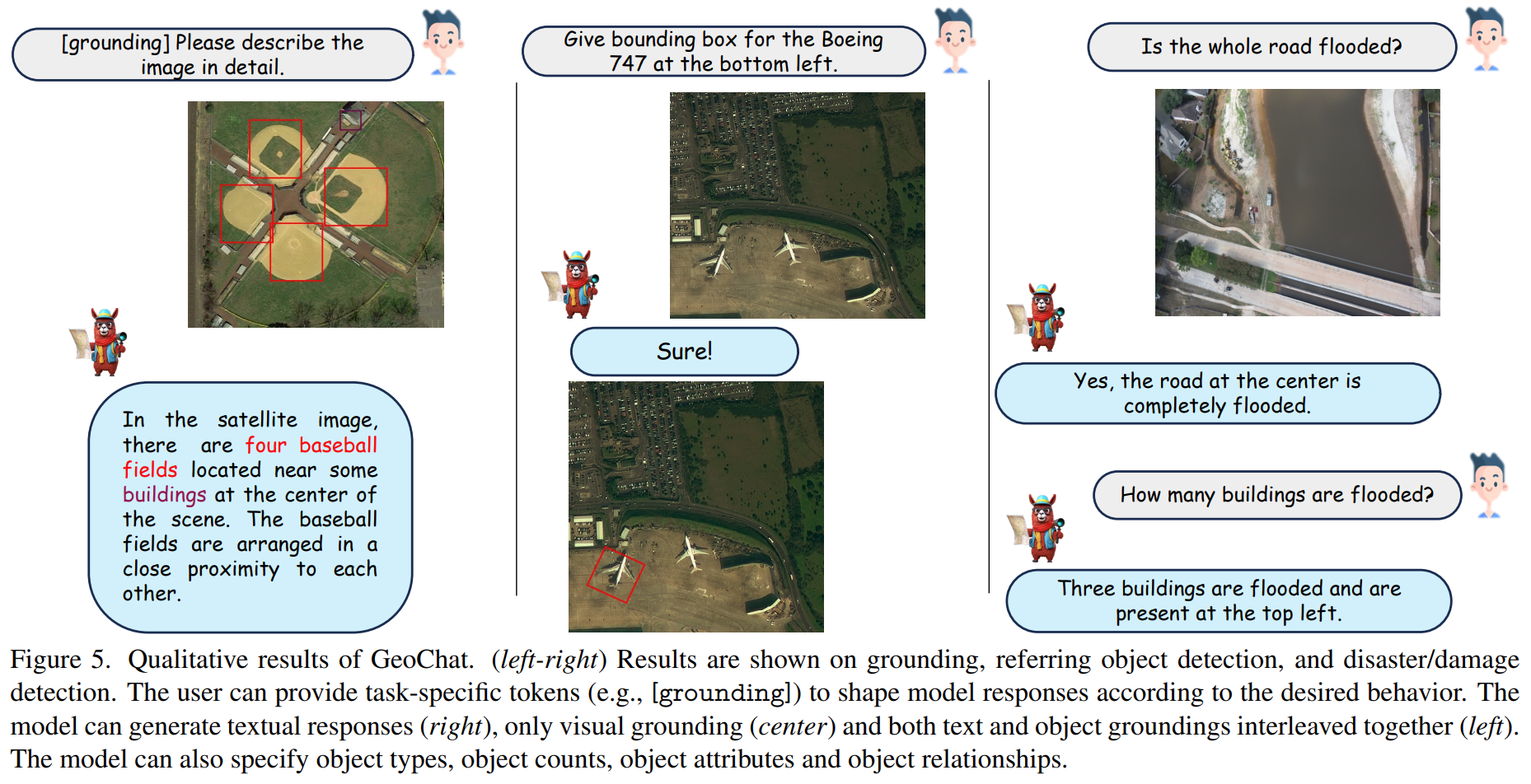
GeoChat可以在一个统一的框架中完成遥感(RS)图像理解的多个任务。给定合适的任务标记和用户查询,该模型可以生成基于视觉的响应(带有相应对象位置的文本-如上图所示)、图像和区域的视觉问答(分别为左上角和右下角)以及场景分类(右上角)和正常自然语言对话(下图)。这使其成为第一个具有接地能力的RS VLM。
贡献:
1、RS 多模态指令遵循数据集。我们提出了一种新颖的数据生成pipline,利用现有的对象检测数据集创建图像的简短描述,然后使用 Vicuna-v1.5和仅使用生成的文本创建对话。此外,我们使用相应的数据集添加视觉问答和场景分类能力。总共有 318k 个指令对的RS数据集。
2、GeoChat。利用我们的数据集,我们微调 LLaVA1.5 以创建遥感领域视觉语言模型 - GeoChat。我们的 LoRA 微调非常高效,并且避免忘记嵌入在完全调整的 LLaVA 模型中的必要上下文,该模型的 MLP 投影经过训练,可将图像对齐到 LLM 的词嵌入空间 。这使得 GeoChat 能够保留 LLaVA 的对话和指令跟踪能力,并将其领域知识扩展到遥感任务。
3、我们还解决了缺乏评估基准来评估现有 VLM 在遥感对话方面的能力的问题。为此,我们为 RS 中的对话建立了评估协议,并设置了一套任务,以便与未来在这个方向上的努力进行比较。我们展示了针对不同遥感任务的各种监督评估和零样本评估,包括图像字幕、视觉问答和场景分类,以证明 GeoChat 会话 VLM 的通用性。

二、GeoChat
GeoChat可能完成的任务
a)图像级对话任务。在此任务中,GeoChat处理图像x,和用户文本查询q,其输入或输出中没有任何特定的空间坐标。目标是在图像范围内的整体水平上执行基于对话的任务,如视觉问答(VQA)、场景分类和图像描述。
B)区域级对话任务。此任务在GeoChat的输入中提供x和q之外的空间框位置b。区域位置b将模型的注意力引导到图像内的特定区域,使得模型可以执行诸如区域级字幕、区域特定VQA或多轮对话之类的任务。
c)固定的谈话任务。通过使用称为task-specification的特殊token t,可以引导GeoChat以不同的粒度提供对象位置,同时保持会话能力。它可以帮助执行任务,包括接地图像描述/对话,object grounding and referring expression detection.
GeoChat Architecture

GeoChat遵循LLaVA-v1.5 的架构,由三个核心组件组成,
i)全局图像编码器
ii)MLP适配器(两个线性层)
iii)LLM。
与LLaVA不同,GeoChat 添加了特定的任务提示,指示模型所需的任务类型,即,grounding, image-level or region-level conversations.。此外,我们允许输入和输出中的空间位置,we allow spatial positions within both inputs and outputs, enabling visual prompts as inputs and grounded objects in GeoChat outputs.。值得注意的是,原始LLaVA模型不能执行object grounding或接受区域输入。此外,原始的LLaVA不能推理遥感图像。
任务Token:GeoChat 能够在不同类型的遥感视觉解译任务之间轻松切换,为了消除任务之间的不确定性,为每个任务分配一个唯一的任务标识,![]() ,分别代表grounded conversations, region captioning and referring expression comprehension。对于视觉问答和场景分类的情况,我们直接要求模型以单个单词或短语输出答案。
,分别代表grounded conversations, region captioning and referring expression comprehension。对于视觉问答和场景分类的情况,我们直接要求模型以单个单词或短语输出答案。
空间位置表示:![]() ,角度θ表示边框旋转角度。x和y坐标在区间[0100]内归一化。
,角度θ表示边框旋转角度。x和y坐标在区间[0100]内归一化。
视觉骨干网络:CLIP-ViT(L-14),这个模型原始输入336×336,不适合遥感图像,不足以理解遥感图像中呈现的细节(例如,小物体和物体细节),所以对这个模型的位置编码插值,使输入图片大小为504×504。
MLP Cross-modal Adaptor:使用MLP(输入1024,输出4096)把CLIP-ViT输出的向量映射到语言模型空间。激活函数GeLU。
Large Language Model:Vicunav1.5(7B)作为GeoChat的基础模型。显式地与语言模型交互,构建边界框的文本表示,以表达其空间坐标,用于需要产生空间位置的视觉基础任务。类似地,LLM的安全、一致和有效行为是通过与给定输入一起附加的系统提示来确保的。基于低秩自适应(LoRA)的策略用于对LLM进行微调。

训练细节:
我们使用预训练的CLIP-ViT(L-14)编码器、预训练的MLP适配器和Vicuna-v1.5来初始化我们的模型,该编码器在大量文本和视觉数据上进行训练,该适配器在带有BLIP字幕的LAION-CC-SBU数据集的558K子集上进行预训练。为了使我们的模型适应遥感图像,我们随后对LLM进行了LoRA微调,同时在训练过程中保持MLP适配器和CLIP编码器冻结。
三、RS Multimodal Instruction Dataset

我们专门提供系统指令作为提示,要求Vicuna以一种好像可以看见图像的方式生成多轮问答对(尽管它只能访问文本)。这是通过提供在提示中手动编写的少量上下文示例来实现的,以向Vicuna展示如何基于所提供的标题和信息构建高质量的指令-响应对。我们随机抽取65k张图像来创建多轮对话,10k张图像来生成复杂的问题答案,30k张图像用于生成给定简短描述的详细描述。
组成数据集:集合了三个不同类型的数据集:object detection, scene classification, and visual question answering (VQA)。三个对象检测(DOTA、DIOR和FAIR1M,它们共同形成了SAMRS数据集)、一个场景分类(NWPURESISC-45)、一种VQA(LRBEN)和一种洪水检测VQA数据集。
尽管对象检测数据库中包括各种各样的对象类,但缺少一些基本类别,如建筑物、道路和树木,所以先在LoveDA数据集上预先训练的ViTAE RVSA模型,该模型包括所需的重要类。该模型用于在SAMRS数据集上推断这些类,从而产生伪标签。

属性提取:对于referring expression标注,RS图像中的各种属性是很重要的。选择了五种不同类型的属性,如表3所示。对象类别信息可以直接从SAMRS数据集中获得。对于颜色提取,我们使用K-Means聚类算法。具体来说,我们使用GT框从图像中提取对象的像素,并将其聚类为K组。然后选择最大簇的中心作为对象的颜色。为了指定对象的相对大小,我们将对象分为三种大小:小、正常和大。这种分类是通过测量整个数据集中类的所有实例的面积并将第80个百分位数指定为大标签来确定的。同样,第20个百分位被指定为小尺寸,其余的属于正常类别。为了确定对象在图像中的相对位置,我们将整个图像划分为3×3网格,定义区域,如右上、上、左上、左、中、右、右下、左下和下。根据对象的中心像素坐标,我们相应地指定其相对位置。
为了定义给定图像中对象之间的关系,我们根据边界框之间的距离对不同的对象进行分组,对于每个子图,我们根据对象的类标签分配对象之间的不同关系。表4给出了对象关系的各种示例。为了建立像“被包围”这样的关系,我们交叉参考像素级坐标,以验证一个对象是否完全包含在另一个对象中。


表达式生成:为了模拟自然语言表达式,我们使用预定义文本模板。短语模板包含表3中的属性{a1,…,a5}。同一类的一组对象的表达式公式化为:
![]()
类似地,句子模板结合了关系属性a5,以通过这种结构在两个对象之间建立连接:
![]()
Visual Grounding:使用我们的简短描述作为参考表达来创建三种不同类型的问答对,即基础图像描述、参考表达和区域级字幕,如表1所示。
四、实验
1、实验细节
我们使用预训练的CLIP-ViT和LLM(Vicuna-v1.5)初始化我们的模型的权重,并应用LoRA微调。利用LoRA,我们通过低秩自适应来细化参数Wq和Wv,在我们的实现中,指定秩r设置为64。该模型在整个过程中始终以504×504的图像分辨率进行训练。每个训练步骤都包含专门为训练过程中的各种视觉语言任务设计的多模态指令模板。我们使用AdamW优化器和余弦学习速率调度器来训练我们的模型。我们将全局批量大小保持为144。我们分两个阶段训练我们的模型,首先,我们使用所有数据集训练1个时期,相应地训练2400步,然后是第2阶段,我们只在grounding dataset上训练1600步。
2、数据集介绍:
场景分类:
AID:AID是根据Google Earth图像编译的大规模航空图像集合,有30个类别,例如河流、密集住宅区等。这些图像由遥感图像解释领域的专家标记。总的来说,AID数据集包含 30 个类别的 10,000 张图像。这些图像是在不同的国家和不同的天气条件下拍摄的。
(AID 数据集的 20%用于评估)
UCMerced:UCMerced 是一个土地利用场景分类数据集,包含 2,100 张图像和 21 个类别。每张图像的大小为 256×256。
(使用整个 UCMerced数据集作为零样本测试集。)
我们提示模型使用所有类别,并提示仅使用一个单词/短语对图像进行分类。

视觉问答:
RSVQA-HRBEN: RSVQA-HRBEN包含 10,569 张高分辨率照片和 1,066,316 个问答对,其中 61.5%、11.2%、20.5% 和 6.8% 分别分为训练集、验证集、测试集 1 和测试集 2。该数据集具有三种问题类型:存在、比较和计数。
(使用 RSVQA-HRBEN 测试集 2,有47k 问题答案对评估)
RSVQA-LR :RSVQA-LR 由 772 个低分辨率图像和 77,232 个问答对组成,其中 77.8%、11.1% 和 11.1% 分别用于训练、验证和测试。有四种不同类别的问题:存在、比较、农村/城市和计数。
评估过程中省略了面积和计数问题,将答案是数字的量化为多个类别。例如,在 RSVQA-LRBEN数据集中,计数问题被量化为五类:0、1 到 10 之间、11 到 100 之间、101 到 1000 之间以及大于 1000。为了评估,我们使用测试一组包含 7k 问题-答案对的 RSVQA-LRBEN。
为了将答案限制为简单的是/否以及农村/城市问题类型,我们在每个问题末尾添加合适的提示。
Visual Grounding:
对这个任务,使用SAMRS的验证集,用上面介绍数据集构建流程来重新构建了一个test benchmark,有7653 [refer], 758 [grounding], and 555 grounding description questions. 我们使用accuracy@0.5作为评估度量。如果预测框与GT框的重叠超过0.5IoU,则计算精度。
3、结果: