本教程参考《RDeepLearningEssential》
本篇我们将学习如何建立并训练深度预测模型。我们将关注深度前馈神经网络
5.1 深度前馈神经网络
我们还是使用之前提到的H2O包,详细可以见之前的博客:R语言深度学习-1-深度学习入门(H2O包安装报错解决及接入/H2O包连接数据集)-CSDN博客
library('h2o')
cl <- h2o.init(max_mem_size = "20G",nthreads = 10,ip = "127.0.0.1", port = 54321)深度前馈神经网络,也被称为前馈神经网络或多层感知机(MLP),是一种典型的多层神经网络,其中数据在神经元之间单向流动,从输入层经过一个或多个隐藏层传递到输出层。这种类型的网络不包含任何循环或反馈连接,意味着信息的流向是从上到下,不会从输出层返回至输入层。
深度前馈神经网络的核心优势在于其能够通过学习输入数据和目标输出之间的复杂映射关系来执行各种任务。这得益于它的层次结构,每一层都从前一层接收信息并产生输出,这些输出作为下一层的输入。随着网络层次的加深,它能够捕捉更抽象的特征,从而提升模型的性能和泛化能力。
如图所示,来自输入X到输出Y的全部映射是一个多层函数。第一个隐藏层是:
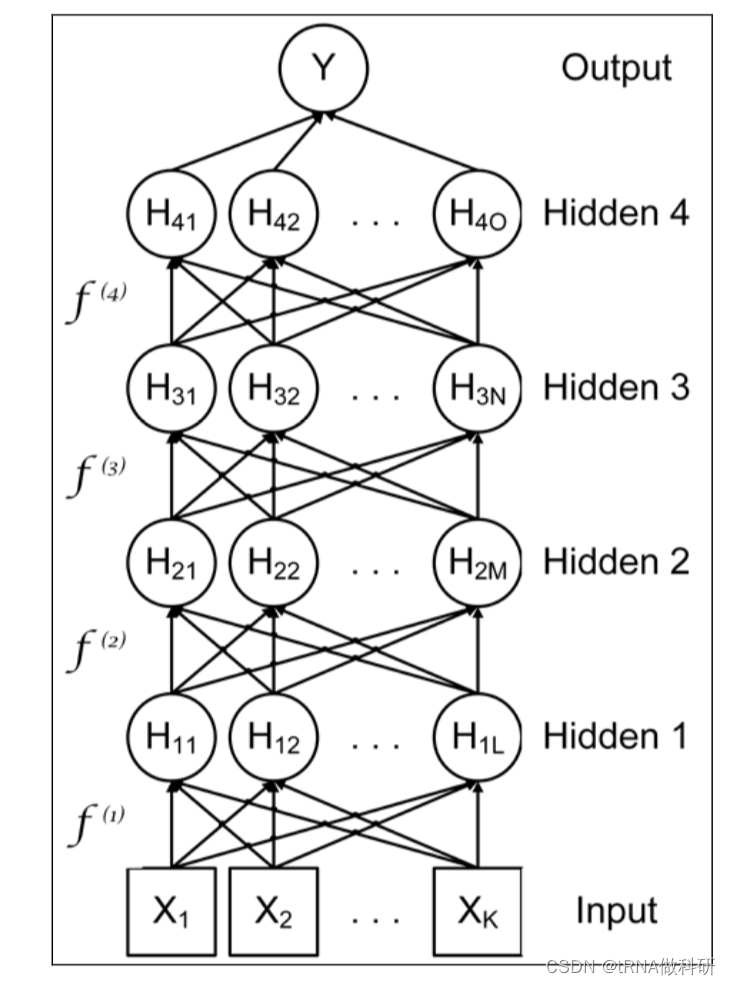
而在每一层中有多少隐藏神经元及使用什么激活函数,我们在5.2讨论,另一个关键是成本或损失函数,常用的是交叉熵(cross-entropy)和二次的函数均方差(MSE)。
5.2 激活函数
激活函数在神经网络中扮演着至关重要的角色。它们通常被嵌入到神经网络的隐藏层中,用以引入非线性因素,使得神经网络能够学习和模拟复杂的数据模式。没有激活函数,无论神经网络有多少层,最终都只是相当于一个线性变换,无法解决非线性问题。
激活函数的种类多样,每种都有其特定的用途和特性。以下是一些常见的激活函数及其特点:
1. Sigmoid函数:Sigmoid函数可以将任意实数映射到(0,1)区间内,这使得它可以用来做二分类问题的输出层。然而,当输入值较大或较小时,Sigmoid函数的梯度接近于0,容易导致梯度消失
2. Tanh函数:Tanh函数是Sigmoid函数的变种,它将实数映射到(-1,1)区间内,相比于Sigmoid函数,Tanh函数的输出以0为中心,但它同样存在梯度消失的问题。
3. ReLU函数:ReLU(Rectified Linear Unit)函数是目前最常用的激活函数之一。它在输入大于0时直接输出该值,小于等于0时输出0。ReLU函数解决了梯度消失问题,计算简单且加速了神经网络的训练。但ReLU函数也有缺点,比如当输入为负数时,梯度始终为0,可能导致神经元“死亡”。
4. Leaky ReLU函数:Leaky ReLU是对ReLU的改进,它在输入小于等于0时,梯度不为0,而是一个很小的正数。这样可以缓解ReLU的死神经元问题。
5. Softmax函数:Softmax函数常用于多分类问题的输出层,它可以将一组数值转化为概率分布。
6. Swish函数:Swish函数是一个平滑且非单调的激活函数,由谷歌提出,在某些情况下比ReLU表现更好。
7. Mish函数:Mish函数结合了ReLU和Swish的优点,具有更好的性能表现。
5.3 选取超参数
我们在之前的模型选择参数,一般是选取如权重或者截距。不过还有一些参数能够被学到或者能被优化,我们在进行模型选择的时候,也是一种超参数。我们还是使用之前的手写字数据进行实践:
R语言深度学习-2-训练预测模型-CSDN博客
我们使用H2O的深度学习算法来训练一个分类器,并比较不同学习率对模型性能的影响。以下是两个深度学习模型的配置和它们的运行时间分析。
options(width = 70, digits = 2)
#初始化
dig_train <- read.csv("C:\\Users\\Huzhuocheng\\Desktop\\digit-recognizer\\train.csv")
dim(dig_train) #数据维度查看
dig_train$label <- factor(dig_train$label, levels = 0:9)h2odigits <- as.h2o(dig_train,destination_frame = "h2odigits")
i <- 1:32000
h2odigits.train <- h2odigits[i, ]
itest <- 32001:42000
h2odigits.test <- h2odigits[itest, ]
xnames <- colnames(h2odigits.train)[-1]#训练模型
system.time(ex1 <- h2o.deeplearning(x = xnames,y = "label",training_frame= h2odigits.train,validation_frame = h2odigits.test,activation = "RectifierWithDropout",hidden = c(100),epochs = 10,adaptive_rate = FALSE,rate = .001,input_dropout_ratio = 0,hidden_dropout_ratios = c(.2)
))
system.time(ex2 <- h2o.deeplearning(x = xnames,y = "label",training_frame= h2odigits.train,validation_frame = h2odigits.test,activation = "RectifierWithDropout",hidden = c(100),epochs = 10,adaptive_rate = FALSE,rate = .01,input_dropout_ratio = 0,hidden_dropout_ratios = c(.2)
))
我们选择了不同的学习率,ex1中学习率是0.001,在ex2中,学习率是0.01,我们发现ex1的运行时间长很多,但是就模型效果来说,ex1更好:
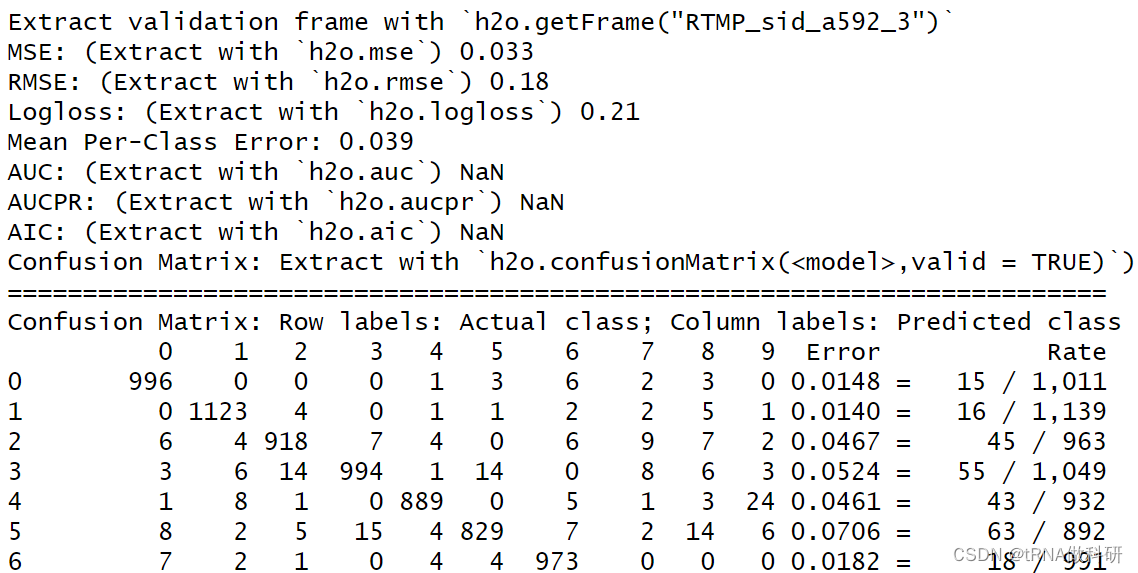

深刻理解超参数,对我们在模型进行训练中有事半功倍的效果,有的时候不是模型不行,而是选择了错误的超参数,这很重要。
5.4 深度神经网络训练及预测
我们使用之前提到的UCI数据进行演示:UCI Machine Learning Repository
#数据导入
train_x <- read.table("C:/Users/Huzhuocheng/Desktop/UCI数据/UCI HAR Dataset/UCI HAR Dataset/train/X_train.txt")
train_Y <- read.table("C:/Users/Huzhuocheng/Desktop/UCI数据/UCI HAR Dataset/UCI HAR Dataset/train/y_train.txt")
test_x <- read.table("C:/Users/Huzhuocheng/Desktop/UCI数据/UCI HAR Dataset/UCI HAR Dataset/test/X_test.txt")
test_Y <- read.table("C:/Users/Huzhuocheng/Desktop/UCI数据/UCI HAR Dataset/UCI HAR Dataset/test/y_test.txt")
barplot(table(train_Y))
train_x <- as.data.frame(train_x)
train_Y <- as.data.frame(train_Y)train_Y <- factor(train_Y)
test_Y <- factor(test_Y) use.train <- cbind(train_x, Outcome = train_Y)
use.test <- cbind(test_x, Outcome = test_Y)use.labels <- read.table("C:\\Users\\Huzhuocheng\\Desktop\\UCI数据\\UCI HAR Dataset\\UCI HAR Dataset\\activity_labels.txt")
h2oactivity.train <- as.h2o(use.train,destination_frame = "h2oactivitytrain")
h2oactivity.test <- as.h2o(use.test,destination_frame = "h2oactivitytest")
接下来,我们使用H2O的deeplearning包进行深度学习,使用的激活函数是线性整流器,并且使用了我们上次讲的丢弃正则化,带有输入变量20%丢弃和隐藏神经元50%丢弃,并且我们建立的是一个50神经元和10次迭代的浅层网络,损失函数是交叉熵。
mt1 <- h2o.deeplearning(x = colnames(train_x),y = "Outcome",training_frame= h2oactivity.train,activation = "RectifierWithDropout",hidden = c(50),epochs = 10,loss = "CrossEntropy",input_dropout_ratio = .2,hidden_dropout_ratios = c(.5),export_weights_and_biases = TRUE
)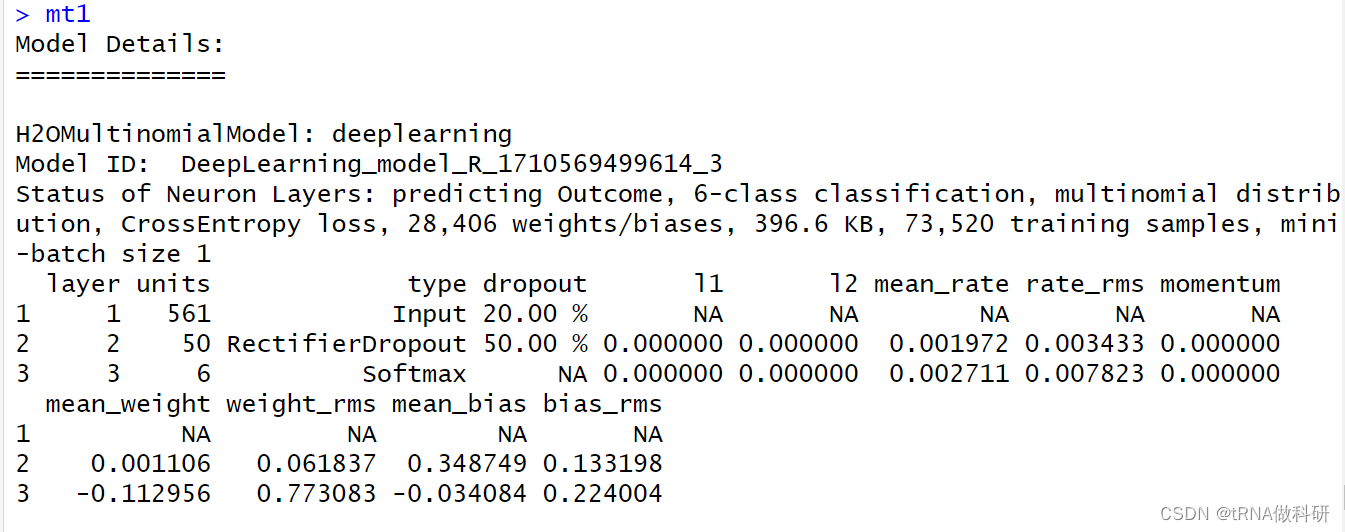
显示了层数及每个层中单元的个数,单元的类型,丢弃百分比和其他正则信息。

这个则显示了模型的性能,包括均方误,对数损失等。
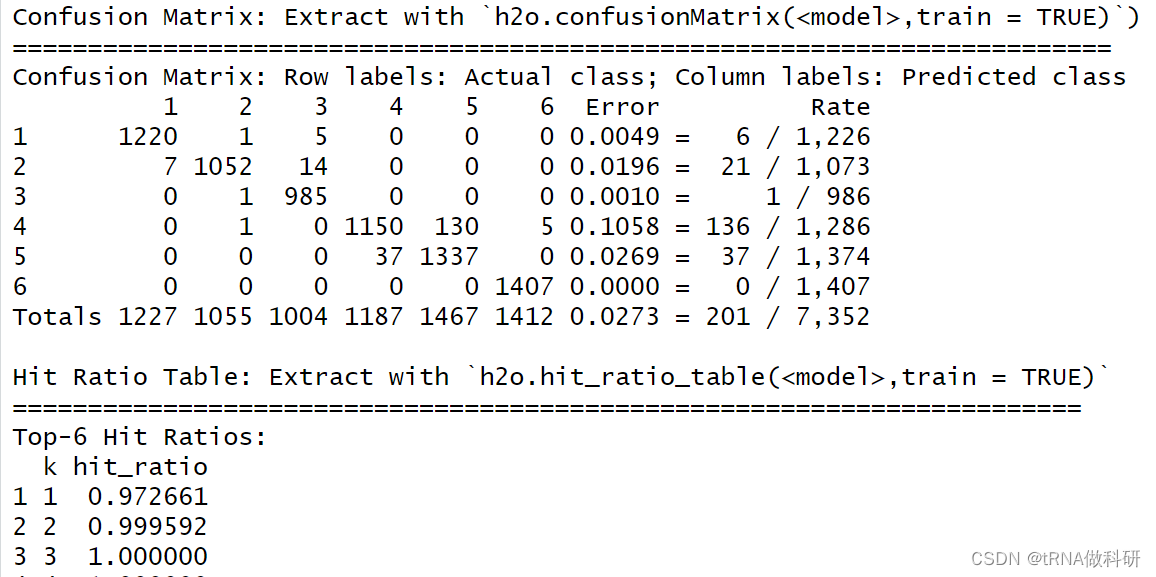
混淆矩阵显示了预测与真实值的差距。
5.5 小结
我们本次使用H2O包对深度神经网络进行了学习应用,不过我们在例子中构建的都是浅层的神经网络,大家可以自己调参数实现更好的理解与应用。