文章目录
- 成果演示
- 背景
- 整体能力
- 功能描述
- 相关细节
- 安装使用
成果演示
Github地址:数据治理脚手架
wiki:kg-ctl-core使用文档

背景
- 为什么要做这个?
一个老生常谈且不得不谈问题:随着业务日益发展,如果不做数据迁移,MySQL在每天几百万数据产生的背景下,到千万级时,由于B+树的成长导致查询性能下降越来越明显,即便是以大名鼎鼎NoSQL:ES、MongoDB、TIDB 都不会去单独承载一个公司的全量数据,势必会在一个标志性时间内以冷热区分,用热数据来极大发挥关系数据库的读写性能,用冷数据发挥NoSQL存储和查询性能【事实上ES、TIDB在TB级数据下写入速度也会打折扣】。
因此当业务体量到达一个层面,就需要去通过数据迁移手段来维护冷热数据
注:分表终究是缓兵之计,
- 为啥不用canal?
首先canal确实有一定便捷性,特别是解耦了业务;但是不知道有多少人用过,我们最初也用过,但是有几次未知的事故下来总结几点不适合:
- canal本身也是服务需要单独部署,交给运维管控,同时因为其内部黑盒导致排查问题困难,而且如果出现网络异常造成消息丢失,无人知晓,本质缺少细粒度error日志和监控
- canal 作为mysql的slave,会无脑接受binlog,然后解析成消息通过各种中间件如kafka、rocketmq发送给真正接受数据源:这时候有两个选择
2.1 另起一个服务,消费消息同步【我们采用这种方式,在写多、数据库抖动情况下容易出现消息积压, 】
2.2 直接通过canal已支持目的数据源配置方式同步,目前NoSQL这块仅仅支持ES、HBase,并且新能力几乎不在研发- 公司处于疫情之后的降本增效阶段,各组都在缩容服务器资源,难以提供新机器来维持
- canal 只管数据同步,却不考虑如何校验数据一致性,即便同步完成可不可用还两说
总上所述几个痛点,结合背景,我们采用内置SDK方式,将通用同步能力、通用数据比对能力、数据归档、数据恢复能力构成完整的迁移体系于一身自研低代码脚手架,以提高数据治理的效率,同时降低机器成本,后续运维成本【小公司非常建议】
整体能力
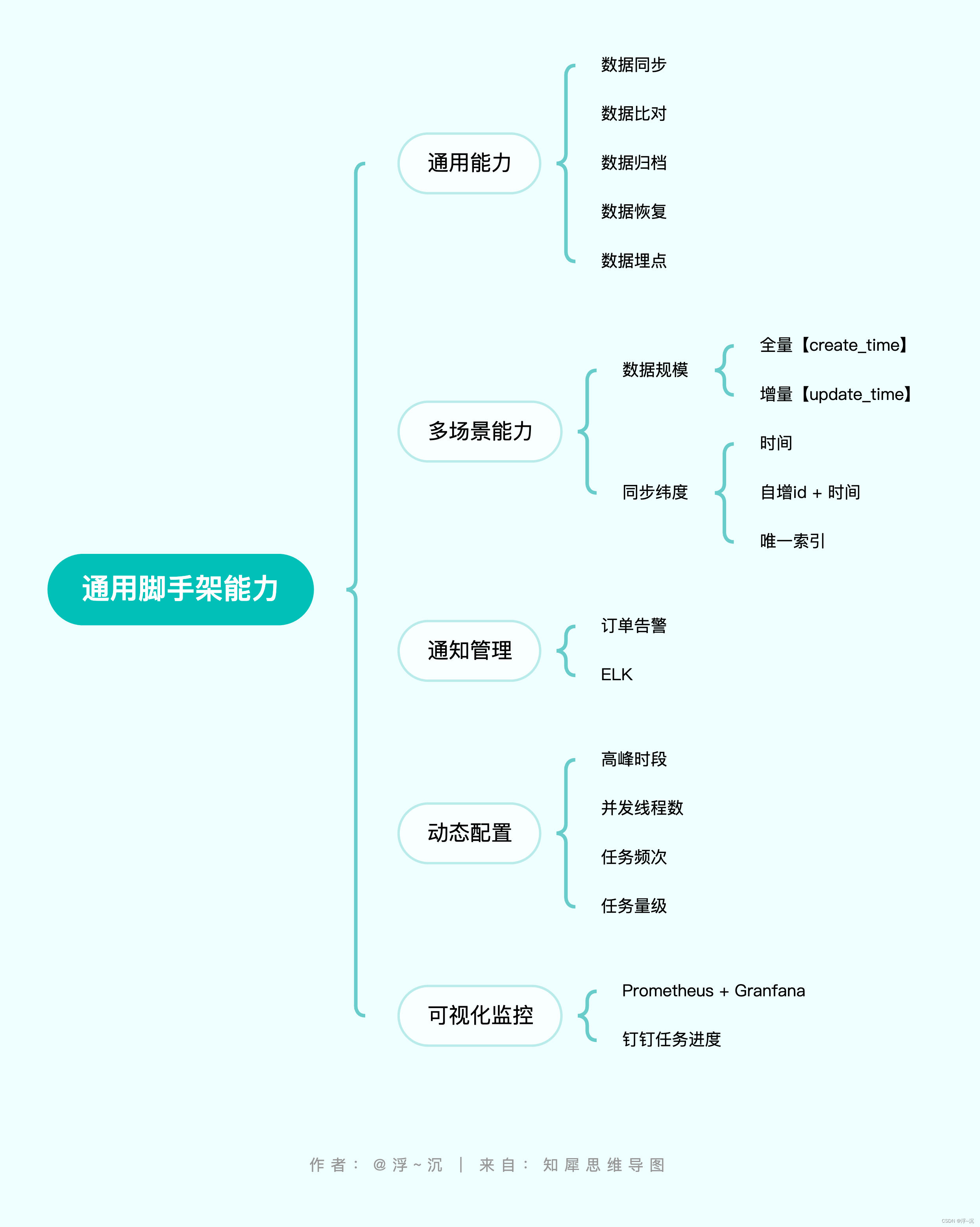
功能描述
1. 面向通用数据治理,减少90%的重复冗余的数据同步工作开发
2. 精细化控制任务频次、量级甚至可以联动高低峰时段
3. 支持多维度数据同步、数据恢复,支持业务唯一id、时间段,包括分表
4. 无需额外部署服务器资源,可直接内置在现有业务中
5. 提供自动check同步数据源之间表结构差异,及时感知业务变更对目的数据源的影响【进行中】
6. 基于Prometheus提供可视化监控告警
7. 钉钉进度同步
相关细节
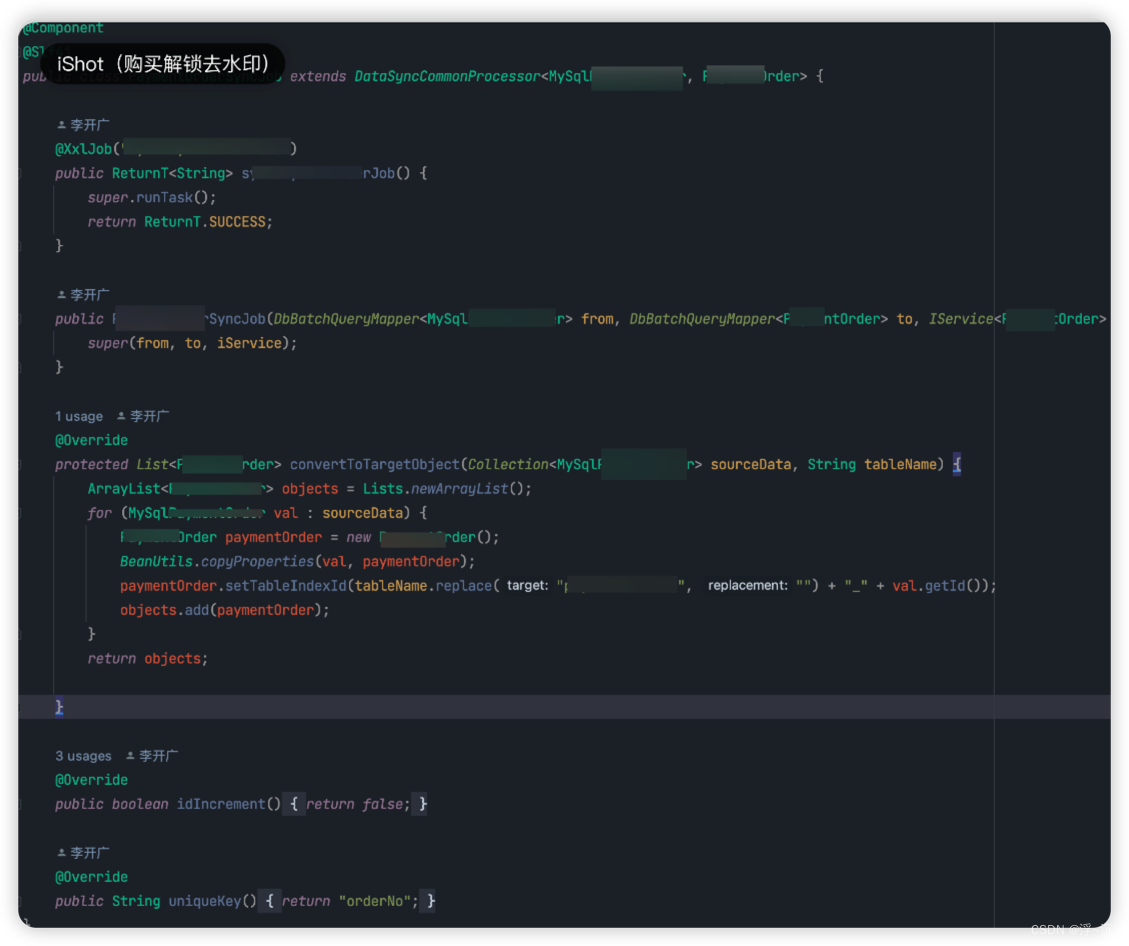
1、仅仅通过不到20行代码和配合即可实现
2、日志输出

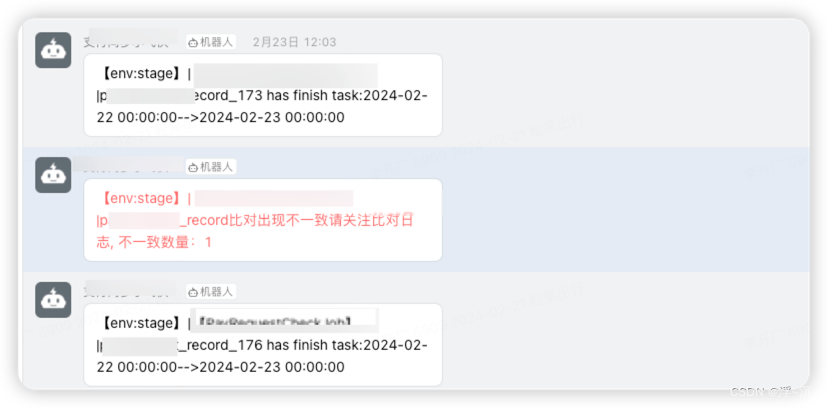
3、钉钉实时进度推送&告警
4、Granfana 监控收集

安装使用
看个人需要,既可以以jar方式依赖注入到已有项目中,或者单独部署成服务进行通用化数据治理
无论哪一种都需要下载依赖,然后只需要如下几步:
- 在你的项目中,配置目标数据源 【推荐抽一个公共服务来统一做】
- 实现目标接口,按示例照做即可
- 配置xxl-job请求参数
- 配置apollo任务控制参数
- 启动job
有关具体实操可以前往Github下载源码查看quick-start操作实例;
或者直接参考wiki:kg-ctl-core使用文档
另外本文主要聚焦低代码如何去实现整个数据迁移过程,有关更多迁移细节可以参考我的这篇体系讲解:从梳理到落地-DB单表千万级归档详细流程讲解