文章目录
- 一、前言
- 二、正则表达式与Python中的实现
- 1、字符串构造
- 2、字符串截取
- 3、字符串格式化输出
- 4、字符转义符
- 5、字符串常用函数
- 6、字符串常用方法
- 7、正则表达式
- 1. `.`:表示除换行符以外的任意字符
- 2. `[]`:指定字符集
- 3. `^` :匹配行首,匹 ^后面的字符串
- 4.`$`:匹配行尾,匹配$之前的字符串
- 5. `\`:反斜杠后面可以加不同的字符以表示不同的特殊意义
- 6. `*`:匹配重复 0 次或多次的字符
- 7. `+`:匹配重复 1 次或多次的字符
- 8. `?`:匹配 0 次或 1 次的字符
- 9.“{m,n}”:表示至少有m个重复,至多有n个重复。m,n均为十进制数
- 典例
一、前言
本文将介绍正则表达式中常见的
.、[]、^、$、*、+、?、{m,n}等元字符。
二、正则表达式与Python中的实现
1、字符串构造
2、字符串截取
【自然语言处理】NLP入门(一):1、正则表达式与Python中的实现(1):字符串构造、字符串截取
3、字符串格式化输出
【自然语言处理】NLP入门(二):1、正则表达式与Python中的实现(2):字符串格式化输出(%、format()、f-string)
4、字符转义符
【自然语言处理】NLP入门(三):1、正则表达式与Python中的实现(3):字符转义符
5、字符串常用函数
在Python中有很多内置函数可以对字符串进行操作。如len()、ord()、chr()、max()、min()、bin()、oct()、hex()等。
自然语言处理】NLP入门(四):1、正则表达式与Python中的实现(4):字符串常用函数
6、字符串常用方法
由于字符串属于不可变序列类型,常用方法中涉及到返回字符串的都是新字符串,原有字符串对象不变
【自然语言处理】NLP入门(五):1、正则表达式与Python中的实现(5):字符串常用方法:对齐方式、大小写转换详解
【自然语言处理】NLP入门(六):1、正则表达式与Python中的实现(6):字符串常用方法:find()、rfind()、index()、rindex()、count()、replace()
7、正则表达式
正则表达式是一个特殊的字符序列,利用事先定义好的一些特定字符以及它们的组合组成一个“规则”,检查一个字符串是否与这种规则匹配来实现对字符的过滤或匹配。
- Python中,re模块提供了正则表达式操作所需要的功能。
- 元字符是一些在正则表达式中有特殊用途、不代表它本身字符意义的一组字符。
/^1[34578][0-9]$/
【自然语言处理】NLP入门(七):1、正则表达式与Python中的实现(7):常用正则表达式、re模块:findall、match、search、split、sub、compile
1. .:表示除换行符以外的任意字符
- 与“.”类似(但不相同)的一个符号是“\S”,表示不是空白符的任意字符。注意是大写字符S
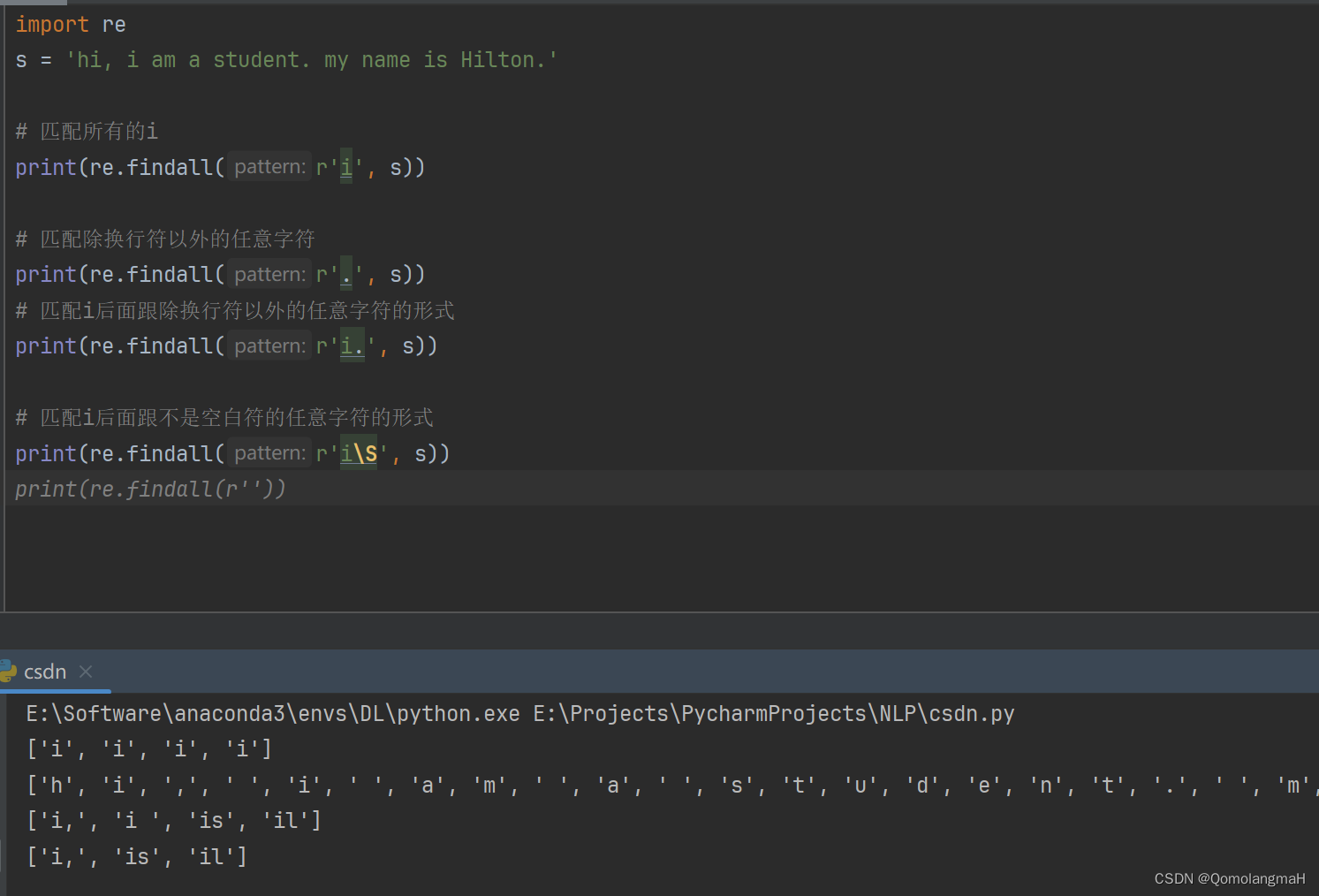
import re
s = 'hi, i am a student. my name is Hilton.'# 匹配所有的i
print(re.findall(r'i', s)) # ['i', 'i', 'i', 'i']# 匹配除换行符以外的任意字符
print(re.findall(r'.', s)) # ['h', 'i', ',', 'i', ' ', 'a', 'm', ' ', 'a', ' ', 's', 't', 'u', 'd', 'e', 'n', 't', '.', 'm', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'H', 'i', 'l', 't', 'o', 'n', '.']# 匹配i后面跟除换行符以外的任意字符的形式
print(re.findall(r'i.', s)) # ['i,', 'i ', 'is', 'il']# 匹配i后面跟不是空白符的任意字符的形式
print(re.findall(r'i\S', s)) # ['i,', 'is', 'il']
2. []:指定字符集
[]用来指定一个字符集,可以匹配字符集中的任何一个字符。- 例如
[abc]表示匹配a、b或c中的任何一个字符;[a-z]表示匹配任意小写字母;[0-9]表示匹配任意数字字符。下面是一个关于它的示例:
- 例如
- 元字符在方括号中不起作用,例如:
[akm$]和[m.]中元字符都不起作用; - 方括号内的
^表示补集,匹配不在区间范围内的字符,例如:[^3]表示除3以外的字符。
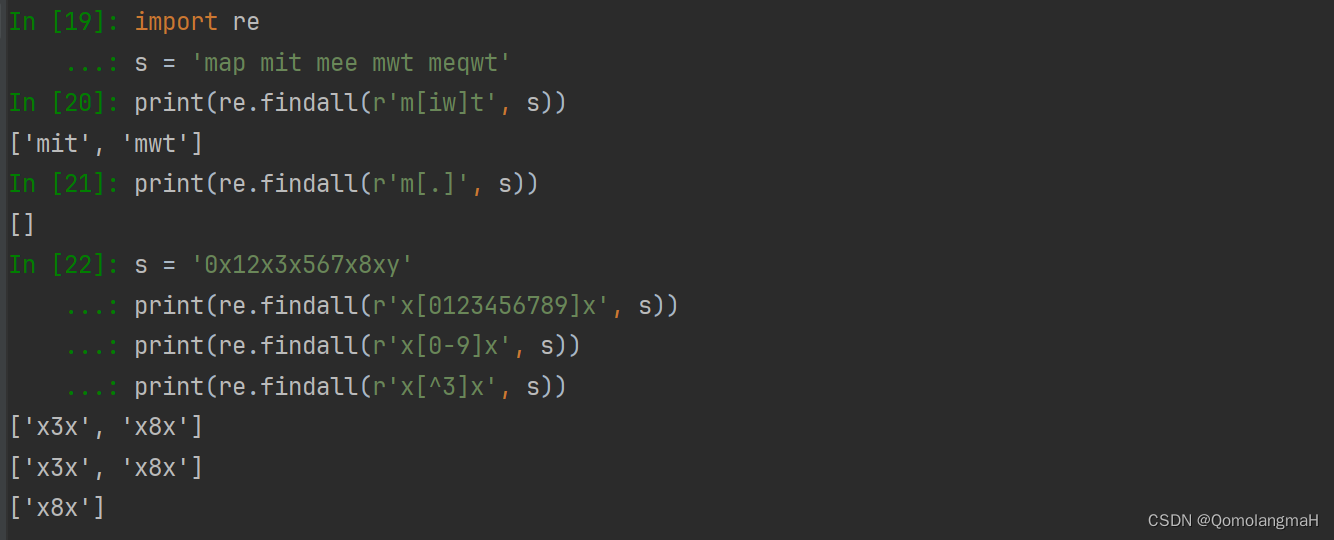
import re
s = 'map mit mee mwt meqwt'# 匹配'me'
print(re.findall(r'me', s)) # ['me', 'me']# 匹配m后面跟i或者w再跟t形式
print(re.findall(r'm[iw]t', s)) # ['mit', 'mwt']# 元字符“.”放在[]内,不起作用
print(re.findall(r'm[.]', s)) # []s = '0x12x3x567x8xy'
print(re.findall(r'x[0123456789]x', s)) # ['x3x', 'x8x']
print(re.findall(r'x[0-9]x', s)) # ['x3x', 'x8x']
print(re.findall(r'x[^3]x', s)) # ['x8x']
3. ^ :匹配行首,匹 ^后面的字符串
^匹配行字符串的开始。在多行模式中,还匹配换行符后面的位置。
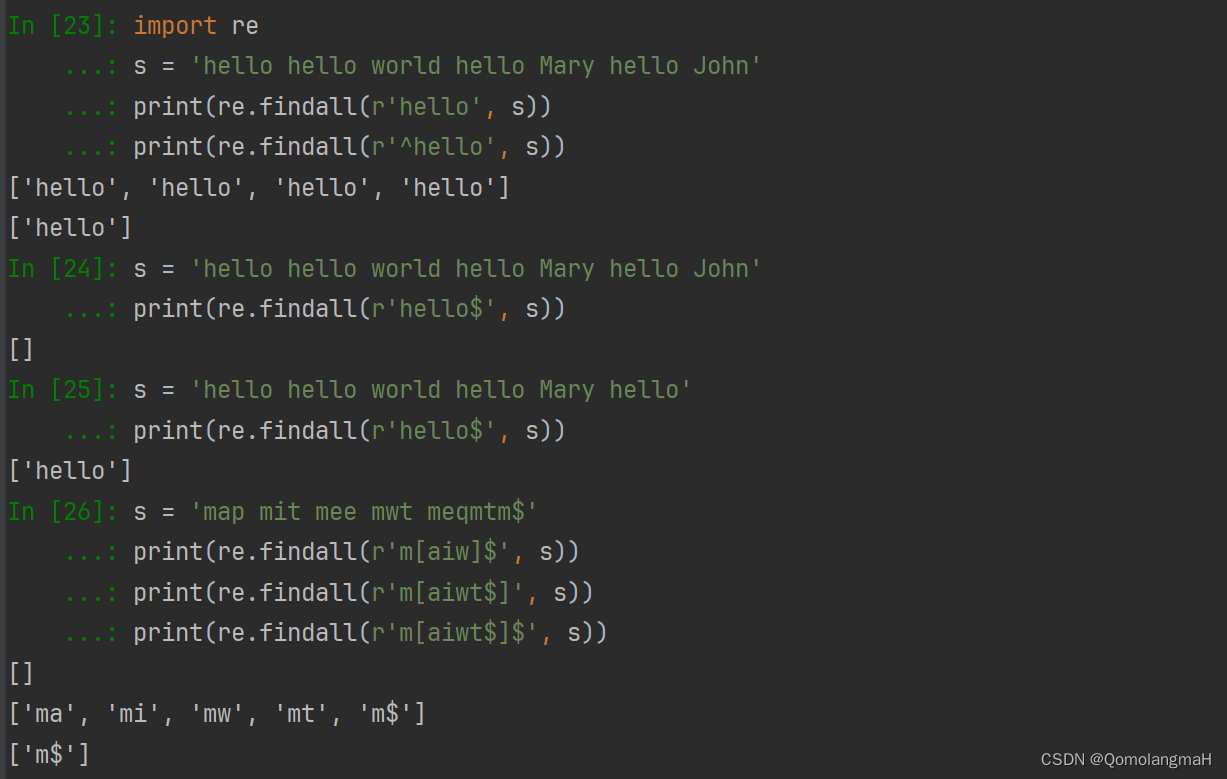
import re
s = 'hello hello world hello Mary hello John'
print(re.findall(r'hello', s)) # ['hello', 'hello', 'hello', 'hello']
print(re.findall(r'^hello', s)) # ['hello']
4.$:匹配行尾,匹配$之前的字符串
$匹配行字符串的结尾。在多行模式中,还匹配换行符的前面的位置。
import re
s = 'hello hello world hello Mary hello John'
print(re.findall(r'hello$', s)) # []
s = 'hello hello world hello Mary hello'
print(re.findall(r'hello$', s)) # ['hello']
s = 'map mit mee mwt meqmtm$'
print(re.findall(r'm[aiw]$', s)) # []
print(re.findall(r'm[aiwt$]', s)) # ['ma', 'mi', 'mw', 'mt', 'm$']
print(re.findall(r'm[aiwt$]$', s)) # ['m$']
5. \:反斜杠后面可以加不同的字符以表示不同的特殊意义
\b:匹配单词的边界(单词的开头或结尾)\B:与\b相反,匹配非单词的边界\d:匹配任何十进制数字,相当于字符集[0-9]\D:与\d相反,匹配任何非数字字符,相当于[^0-9]\s:匹配任何空白字符,包括空格、制表符、换行符等,相当于字符集[\t\n\r\f\v]\S:与\s相反,匹配任何非空白字符,相当于[^ \t\n\r\f\v]\w:匹配任何字母、数字或下划线字符,相当于字符集[a-zA-Z0-9_]\W:与\w相反,匹配任何非字母、数字和下划线字符,相当于[^a-zA-Z0-9_]
import re
s = '0x12x3x567x8xy'# 使用字符集匹配数字
print(re.findall(r'[0-9]', s))
# ['0', '1', '2', '3', '5', '6', '7', '8']# 使用\d匹配数字
print(re.findall(r'\d', s))
# ['0', '1', '2', '3', '5', '6', '7', '8']# 匹配字母“x”或数字
print(re.findall(r'[x\d]', s))
# ['0', 'x', '1', '2', 'x', '3', 'x', '5', '6', '7', 'x', '8', 'x']
正则表达式除了能够匹配定长的字符集,还能匹配不定长的字符集、这需要指定正则表达式的一部分的重复次数,所涉及的元字符有
*、+、?、{}。
6. *:匹配重复 0 次或多次的字符
import re
s = 'a ab abbbbb abbbbbxa'
print(re.findall(r'ab*', s))
# ['a', 'ab', 'abbbbb', 'abbbbb', 'a']
注意:
匹配abbbbb(5个b),为什么不匹配abbbb(4个b)、abbb(3个b)、abb(2个b)?(abbbbb的字串)
- 0次或多次出现,贪心算法~匹配最长的
7. +:匹配重复 1 次或多次的字符
import re
s = 'a ab abbbbb abbbbbxa'
print(re.findall(r'ab+', s))
# ['ab', 'abbbbb', 'abbbbb']
8. ?:匹配 0 次或 1 次的字符
- 当“?”紧随其他限定符(*、+、{n}、{n,}、{n,m})之后时,匹配模式是“非贪心的”。“非贪心的”模式匹配搜索到尽可能短的字符串,而默认的“贪心的”模式匹配搜索到的、尽可能长的字符串。
import re
s='a ab abbbb abbbbbxa'
re.findall(r'ab+',s) #最大模式、贪心模式
# ['ab', 'abbbb', 'abbbbb']
re.findall(r'ab+?',s) #最小模式、非贪心模式
# ['ab', 'ab', 'ab']
- 实验 :两个问号是否就是彻底不贪心的了???
- 错误的:在正则表达式中,两个问号 "??” 是语法错误,在正则表达式中使用两个问号 "??” 是无效的。
9.“{m,n}”:表示至少有m个重复,至多有n个重复。m,n均为十进制数
- 忽略m表示0个重复,忽略n表示无穷多个重复。
- {0,}等同于*;{1,}等同于+;{0,1}与?相同。
- 但是如果可以的话,最好使用*、+、或?
import re
s = '021-33507yyx,021-33507865,010-12345678,021-123456789'
print(re.findall(r'021-\d{8}', s))
# ['021-33507865', '021-12345678']
print(re.findall(r'\b021-\d{8}\b', s))
# ['021-33507865']
典例
随机产生10个长度为1~25之间,由字母、数字、和“_”“.”“#”“%”特殊字符组成的字符串构成列表,找出列表中符合下列要求的字符串:长度为5-20,必须以字母开头、可带数字、“_”“.”
import re
import random
import stringdef generate_random_string(length):characters = string.ascii_letters + string.digits + "_.#%"return ''.join(random.choice(characters) for _ in range(length))random_strings = [generate_random_string(random.randint(1, 25)) for _ in range(10)]
print("随机生成的字符串列表:", random_strings)filtered_strings = [s for s in random_strings if re.match(r"^[a-zA-Z][a-zA-Z0-9_.]{4,19}$", s)]
print("符合条件的字符串列表:", filtered_strings)