1. 插入优化
使用insert语句单条单条数据插入效率偏低,建议使用insert批量插入数据,批量控制在500-1000条数据较为合适,当面对数以百万的数据时,可以使用load指令,提升插入数据效率
相关指令
#客户端连接服务端加上参数 --local-infile
mysql --local-infile -u -root -p;
#设置全局参数,将local_infile设置为1,即开启从本地导入数据的开关
set global local_infile = 1;
#执行load指令,将数据加载进表中
load data local infile '文件路径‘ into table '加载相对应表的名称‘ fields terminated by '以什么形式进行分割表格里面的每一行数据' lines terminated by '每一行最后以什么形式结尾'
加载数以百万数据的指令需要先以该指令登录数据库才能执行相对应指令
mysql --local-infile -u root -pmysql> #创建sb数据库
mysql> create database sb;
Query OK, 1 row affected (0.01 sec)mysql> #展示当前数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sb |
| sys |
+--------------------+
5 rows in set (0.01 sec)mysql> #查看批量添加脚本开关是否开启,默认关闭开关
mysql> select @@local_infile;
+----------------+
| @@local_infile |
+----------------+
| 0 |
+----------------+
1 row in set (0.00 sec)mysql> #开添加脚本数据开关
mysql> set global local_infile = 1;
Query OK, 0 rows affected (0.03 sec)mysql> select @@local_infile;
+----------------+
| @@local_infile |
+----------------+
| 1 |
+----------------+
1 row in set (0.00 sec)mysql> use sb;
Database changed
mysql>
mysql> #执行脚本,将数据添加到要添加的数据库
mysql> CREATE TABLE `tb_user` (-> `id` INT(11) NOT NULL AUTO_INCREMENT,-> `username` VARCHAR(50) NOT NULL,-> `password` VARCHAR(50) NOT NULL,-> `name` VARCHAR(20) NOT NULL,-> `birthday` DATE DEFAULT NULL,-> `sex` CHAR(1) DEFAULT NULL,-> PRIMARY KEY (`id`),-> UNIQUE KEY `unique_user_username` (`username`)-> ) ENGINE=INNODB DEFAULT CHARSET=utf8 ;
Query OK, 0 rows affected, 2 warnings (0.11 sec)mysql> #将文本数据加载进sb数据库中的tb_user表中
mysql> load data local infile '/root/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n';
Query OK, 1000000 rows affected (1 min 18.07 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 0mysql> select count(*) from tb_user;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.98 sec)
2. 主键优化
磁盘空间图
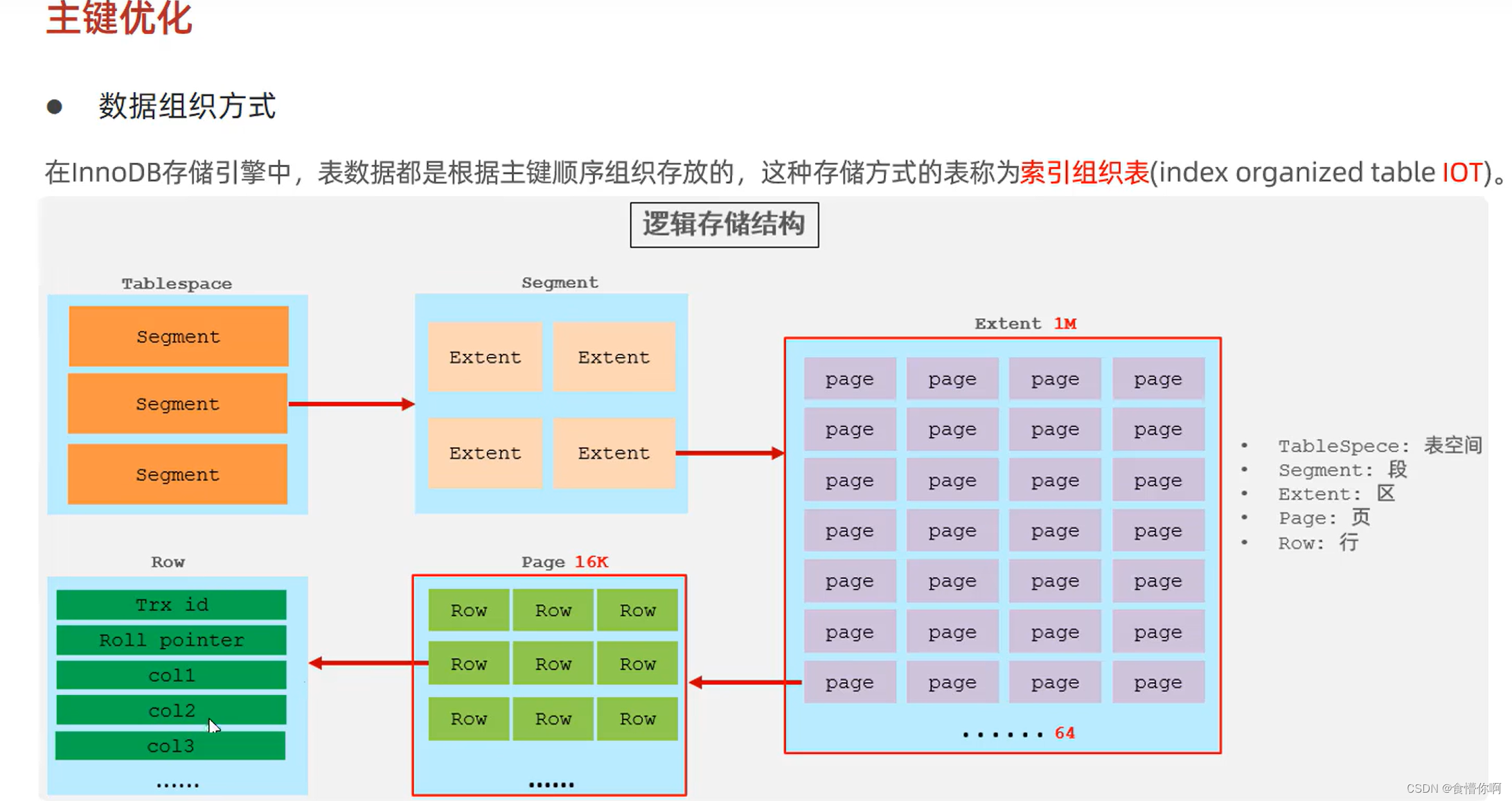
主键的乱序插入和删除会引起两个现象:页分裂和页合并
页:可以为空,也可以已存储50%、66%、100%等待空间,页和页之间有个指针进行联通
页分裂: 当两个页面已经填满数据,但是又有新的数据要插入到两个页面之间时会发生页分裂现象,此时会新建一个页,将第一个页面的50%的数据和新数据一起存入新页面中,而那移动的50%的数据原来所占的空间将会被标记为空,即可以有数据存入该位置,最后页面的之间的指针连接调整,保证数据存储的顺序。


页合并:当一个页面的数据被删除到一定程序时(50%)那么该页会在前后两个页面查找,看两个页面是否有合并的可能,如果有则两个页面数据进行合并


主键设计原则:
- 主键长度尽量不要过长
- 主键尽量顺序插入
- 尽量减少主键的修改操作,主键修改需重新调整存储顺序
3. Order by优化

mysql> explain select age, phone from tb_user order by age asc, phone desc;
+----+-------------+---------+------------+-------+---------------+------------------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+------------------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_pho | 48 | NULL | 21 | 100.00 | Using index; Using filesort |
+----+-------------+---------+------------+-------+---------------+------------------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)#此时不通过索引直接返回,效率相对较差#建立索引
mysql> create index idx_user_age_pho_ad on tb_user(age asc, phone desc);
Query OK, 0 rows affected (0.49 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> explain select age, phone from tb_user order by age asc, phone desc;
+----+-------------+---------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_pho_ad | 48 | NULL | 21 | 100.00 | Using index |
+----+-------------+---------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.10 sec) 
4. Group by优化
当extra查询结果显示有using temporary时(使用临时表)查询分组效率相对较低的 ,此时应当建立索引提高分组效率,当extra结果为using index即走了索引,分组效率相对临时大幅提高
mysql> explain select profession, count(*) from tb_user group by profession;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 21 | 100.00 | Using temporary |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+
1 row in set, 1 warning (0.00 sec)#建立索引后分组效率提高
mysql> explain select profession, count(*) from tb_user group by profession;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user | NULL | index | idx_user_pro_age_sta | idx_user_pro_age_sta | 54 | NULL | 21 | 100.00 | Using index |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
5. limit优化
当进行分页查询时越往后查询时间相对越长,此时可以通过覆盖索引+子查询的方式提高分页查询效率
6. count优化
innodb引擎中统计总行数是将数据从磁盘中逐行读出进行统计的,统计效率低
优化思路:定义变量自己统计

7. update优化
innodb引擎针对索引加的锁,不是针对数据加的锁
不通过主键/索引更新数据容易发生行锁升级为表锁的事件, 一旦升级为表锁,并发性能将会降低