摘要
本文档描述了使用时的两种拥塞控制方法万维网(RTCWEB)上的实时通信;一种算法是基于延迟策略,一种算法是基于丢包策略。
1.简介
拥塞控制是所有共享网络的应用程序的要求互联网资源 [RFC2914]。
实时媒体的拥塞控制对于许多企业来说都是一个挑战的原因是:
o 媒体通常以无法快速编码的形式进行编码更改,以适应不同的带宽和带宽需求通常只能在离散的、相当大的范围内改变脚步
o 参与者可能对如何响应 - 这可能不会减少所需的带宽发现拥塞的流
o 编码通常对丢包敏感,而实时要求排除了通过以下方式修复数据包丢失的可能性重传
本文描述了两种拥塞控制算法
能够提供良好的性能和合理的带宽共享
与使用相同拥塞控制的其他视频流以及 TCP共享相同链接的流。
使用的信令包括实验性 RTP 标头扩展和RTCP 消息 RFC 3550 [RFC3550],如 [abs-send-time] 中定义,[ID.alvestrand-rmcat-remb] 和 [ID.holmer-rmcat-transport-wide-cc-extensions]。
1.1. 数学符号约定
本文档的数学内容是从更多内容转录而来的公式友好的格式。
使用以下符号约定:
X_hat 变量 X 真实值的估计 - 按照惯例在变量名称顶部用抑扬音符号标记。
X(i) 向量 X 的第“i”个值 - 通常用 a 标记下标岛
E{X} 随机变量 X 的期望值
2. 系统模型
系统中包含以下元素:
o RTP 数据包 - 包含媒体数据的RTP数据包。
o数据包组 - 从网络传输的一组RTP数据包由组出发和组唯一标识的发件人到达时间(绝对发送时间)[abs-send-time]。这些可能是视频数据包、音频数据包或音频和视频数据包的混合。
o传入媒体流 - 由RTP组成的帧流数据包。
o RTP发送器 - 通过网络将RTP流发送到RTP接收者。它生成 RTP 时间戳和绝对发送时间标头扩展
o RTP 接收器 - 接收 RTP 流,标记到达时间。
o RTP 接收器处的 RTCP 发送器 - 发送接收器报告、REMB消息和传输范围的 RTCP 反馈消息。
o RTP 发送器处的 RTCP 接收器 - 接收接收器报告和 REMB消息和传输范围的 RTCP 反馈消息,报告这些到发送方控制器。
o RTCP 接收器在 RTP 接收器处,接收来自发送器的报告发件人。
o基于损耗的控制器 - 进行往返损耗率测量时间测量和 REMB 消息,并计算目标发送比特率。
o基于延迟的控制器 - 获取数据包到达信息,无论是在RTP接收器,或来自RTP发送器收到的反馈,并计算最大比特率,并将其传递给基于损失的控制器。
基于损耗的控制器和基于延迟的控制器一起实现拥塞控制算法。
3.反馈和扩展
有两种方法可以实现所提出的算法。一处两个控制器都在发送端运行,其中一个控制器在发送端运行基于延迟的控制器在接收端运行,基于损耗的控制器在接收端运行控制器在发送端运行。
第一个版本可以通过使用每包反馈来实现协议,如通过描述[ID.holmer-rmcat-transport-wide-cc-extensions]。
这里,RTP接收器将记录到达时间和运输范围内的顺序每个收到的数据包的编号,该编号将被发送回发送方定期使用传输范围的反馈消息。这建议的反馈间隔是每个接收到的视频帧一次或如果是纯音频或多流,则至少每30毫秒一次。如果需要限制反馈开销,可以增加此间隔至100毫秒。
发送者将收到的{序列号,到达时间}进行映射与反馈报告涵盖的每个数据包的发送时间配对,并将这些时间戳提供给基于延迟的控制器。它会还根据中的序列号计算丢失率反馈消息。
第二个版本可以通过基于延迟的控制器来实现在接收端,监控并处理到达时间和传入数据包的大小。发送者应该使用abs-send-time RTP 标头扩展 [abs-send-time] 使接收方能够计算组间延迟变化。延迟的输出基于控制器将是一个比特率,它将被发送回发送方使用 REMB 反馈消息[ID.alvestrand-rmcat-remb]。
丢包率通过RTCP 接收器报告发回。
发送方 REMB 消息中的比特率和数据包的比例损失被馈送到基于损失的控制器,该控制器输出最终的目标比特率。建议尽快发送 REMB 消息当检测到拥塞时,否则至少每秒一次。
4. 发送引擎
起搏用于驱动由计算得出的目标比特率控制器。
当媒体编码器生成数据时,数据会被送入 Pacer 队列。
Pacer每隔burst_time向网络发送一组数据包间隔。burst_time的推荐值为5毫秒。数据包组的大小计算为目标之间比特率和burst_time的乘积。
5. 基于延迟的控制
基于延迟的控制算法可以进一步分解为四种部件:预过滤器、到达时间过滤器、过度使用检测器、和速率控制器。
5.1. 到达时间模型
本节介绍一个不断更新的自适应滤波器根据接收到的时间估计网络参数数据包组。
我们将到达间隔时间 t(i) - t(i-1) 定义为两组数据包的到达时间。相应地,出发时间 T(i) - T(i-1) 定义为两组数据包的出发时间。最后,组间延迟变化 d(i) 定义为到达间隔时间和出发间隔时间。或解释为不同的是,第i组和第i组的延迟之间的差异i-1。
d(i) = t(i) - t(i-1) - (T(i) - T(i-1))
连续组之间的出发时间计算如下:
T(i) - T(i-1),其中 T(i) 是最后一趟航班的出发时间戳当前正在处理的数据包组中的数据包。任何数据包到达时间模型会忽略按顺序接收的数据。
每个组被分配一个接收时间 t(i),它对应于收到该组的最后一个数据包的时间。一组是如果 t(i) - t(i-1) > T(i) - T(i-1),则相对于其前一个延迟,即,如果到达间隔时间大于出发间隔时间时间。
我们可以将组间延迟变化建模为:
d(i) = w(i)
这里,w(i) 是随机过程 W 的样本,它是链路容量、当前交叉流量和当前发送比特率。我们将 W 建模为白高斯过程。要是我们过度使用我们期望 w(i) 平均值增加的通道,如果网络路径上的队列被清空,则 w(i) 的平均值会减少;否则 w(i) 的平均值将为零。
从 w(i) 中分离出平均值 m(i) 以使过程为零均值,我们得到公式1
d(i) = m(i) + v(i)
噪声项 v(i) 表示网络抖动和其他延迟影响没有被模型捕获。
5.2. 预过滤
预滤波旨在处理由通道中断引起的延迟瞬变。在中断期间,数据包在网络缓冲区中排队,由于与拥塞无关的原因,在以下情况下会突发传送:
停电结束。
预过滤将到达的数据包组合并在一起爆裂。如果这两个数据包之一被合并到同一组中条件成立:
o 在burst_time间隔内发送的一系列数据包构成一个群体。
o 到达间隔时间小于burst_time 的数据包,并且考虑组间延迟变化 d(i) 小于0是当前数据包组的一部分。
5.3. 到达时间过滤器
参数 d(i) 对于每组数据包都很容易获得,i > 1. 我们想要估计 m(i) 并使用这个估计来检测瓶颈链路是否被过度使用。参数可以由任何自适应滤波器估计 - 我们使用卡尔曼滤波器。
令 m(i) 为时间 i 的估计值
我们将从时间 i 到时间 i+1 的状态演化建模为
m(i+1) = m(i) + u(i)
其中 u(i) 是我们建模为平稳过程的状态噪声具有零均值和方差的高斯统计量
q(i) = E{u(i)^2}
q(i) 建议等于 10^-3
给定方程 1,我们得到
d(i) = m(i) + v(i)
其中 v(i) 是零均值高斯白测量噪声方差 var_v = E{v(i)^2}
卡尔曼滤波器递归地将我们的估计 m_hat(i) 更新为:

方差 var_v(i) = E{v(i)^2} 使用指数估计平均滤波器,针对可变采样率进行修改
var_v_hat(i) = max(alpha * var_v_hat(i-1) + (1-alpha) * z(i)^2, 1)
alpha = (1-chi)^(30/(1000 * f_max))
其中 f_max = max {1/(T(j) - T(j-1))} for j in i-K+1,...,i 是接收最后 K 个数据包组的最高速率以及chi 是滤波器系数,通常选择为中的数字区间 [0.1, 0.001]。由于我们假设 v(i) 应该为零平均 WGN 在某些情况下不太准确,我们引入了一个围绕 var_v_hat 更新的附加异常值过滤器。如果 z(i) >3*sqrt(var_v_hat) 过滤器更新为 3*sqrt(var_v_hat)比z(i) 。例如,在以下情况下 v(i) 不会是白色的:
数据包以高于信道容量的速率发送,其中情况下,他们将排在彼此后面。
5.4. 过度使用探测器
组间延迟变化估计 m(i),作为输出获得到达时间滤波器的值与阈值进行比较del_var_th(i)。高于阈值的估计被视为过度使用的迹象。这样的指示还不足以检测器向速率控制子系统发出过度使用信号。A仅当过度使用已被确定时才会发出明确的过度使用信号检测到至少 overuse_time_th 毫秒。然而,如果 m(i)< m(i-1),即使以上所有情况也不会发出过度使用信号条件满足。同样,相反的状态,即未使用状态,是当 m(i) < -del_var_th(i) 时检测到。如果既不过度使用也不使用不足使用检测后,检测器将处于正常状态。
del_var_th 阈值对整体影响显着算法的动力学和性能。特别是,它有已经表明,使用静态阈值 del_var_th,流由所提出的算法控制可以被并发饥饿TCP 流 [Pv13]。这种饥饿可以通过增加将 del_var_th 阈值设置为足够大的值。
原因是,通过使用较大的 del_var_th 值,排队延迟是可以容忍的,而 del_var_th 较小时,过度使用检测器会对偏移的小幅增加做出快速反应通过生成过度使用信号来估计 m(i),该信号会减少基于延迟的可用带宽 A_hat 估计(参见第 4.4 节)。因此,需要动态调整阈值 del_var_th 在最常见的情况下获得良好的性能场景,例如与基于损失的流量竞争时。
因此,我们建议改变阈值 del_var_th(i)
根据以下动力学方程:
del_var_th(i) =del_var_th(i-1) + (t(i)-t(i-1)) * K(i) * (|m(i)|-del_var_th(i-1))
其中 K(i)=K_d if |m(i)| < del_var_th(i-1) 或 K(i)=K_u 否则。这基本原理是当 m(i) 超出范围时增加 del_var_th(i) 范围 [-del_var_th(i-1),del_var_th(i-1)],而当偏移量估计 m(i) 回落到范围内,del_var_th 减小。在这样,当 m(i) 增加时,例如由于 TCP 流进入同样的瓶颈,del_var_th(i) 增加并避免了过度使用信号的不受控制的生成可能会导致由所提出的算法控制的流量饥饿[Pv13]。
此外,如果出现这种情况,则不应更新 del_var_th(i)
持有:
|m(i)| - del_var_th(i) > 15
还建议将 del_var_th(i) 限制在 [6, 600] 范围内,因为太小的 del_var_th(i) 会导致检测器变得过度敏感。
另一方面,当 m(i) 回落到范围内时[-del_var_th(i-1),del_var_th(i-1)] 阈值 del_var_th(i) 为减少,从而可以实现较低的排队延迟。
建议选择 K_u > K_d,以便速率del_var_th 增加的速率高于其增加的速率减少了。通过此设置,可以增加并发 TCP 流情况下的阈值并防止饥饿以及执行协议内的公平性。推荐值del_var_th(0)、overuse_time_th、K_u 和 K_d 分别为 12.5 ms,10 毫秒、0.01 和 0.00018。
5.5. 速率控制
速率控制分为两部分,一部分控制带宽基于延迟的估计,以及控制带宽估计基于损失。两者的目的都是为了增加估计只要没有检测到拥塞,可用带宽 A_hat并确保我们最终能够匹配可用带宽通道并检测过度使用。
一旦检测到过度使用,可用带宽基于延迟的控制器估计的值会减少。这样我们获得可用带宽的递归和自适应估计。
在本文档中,我们假设速率控制子系统定期执行,并且该周期是恒定的。
速率控制子系统有 3 种状态:增加、减少和保持。
“Increase”是没有检测到拥塞时的状态;“减少”是检测到拥塞的状态,“Hold”是这样的状态:
等到已建立的队列耗尽后再“增加”状态。
状态转换(空白字段表示“保持状态”)
是:

子系统以增加状态启动,并一直保持该状态直到检测器子系统已检测到过度使用或使用不足。
每次更新时,基于延迟的可用带宽估计乘法或加法增加,具体取决于其当前状态。
如果当前带宽,系统会成倍增加估计似乎远未达到收敛,但它确实如果看起来更接近收敛,则加性增加。我们假设我们已经接近收敛,如果当前传入的比特率 R_hat(i) 接近输入比特率的平均值。
我们之前处于 Decrease 状态的时间。“关闭”定义为围绕该平均值的三个标准差。这是建议使用以下方法测量平均值和标准差平滑因子为 0.95 的指数移动平均线预计这个平均值涵盖了我们所处的多个场合处于减少状态。每当这些统计数据的有效估计不可用,我们假设我们还没有接近收敛,因此保持乘法增长状态。
如果 R_hat(i) 增加到平均值的三个标准差以上最大比特率,我们假设当前拥塞程度已经改变,此时我们重置平均最大比特率并返回到乘法增加状态。
R_hat(i) 是基于延迟的测量的输入比特率T 秒窗口上的控制器:
R_hat(i) = 1/T * sum(L(j)) 对于 j 从 1 到 N(i)
N(i) 是过去 T 秒内收到的数据包数量,L(j) 是数据包 j 的有效负载大小。0.5 到 1 秒之间的窗口是
受到推崇的。
在乘法增加期间,估计值最多增加每秒 8%。
eta = 1.08^min(time_since_last_update_ms / 1000, 1.0)
A_hat(i) = eta * A_hat(i-1)
在附加增加期间,估计值最多增加每个response_time 间隔半个数据包。响应时间间隔估计为往返时间加上 100 ms 的估计值过度使用估计器和检测器反应时间。
响应时间毫秒 = 100 + rtt_ms
阿尔法 = 0.5 * 分钟(time_since_last_update_ms / response_time_ms, 1.0)
A_hat(i) = A_hat(i-1) + max(1000, alpha * Expected_packet_size_bits)
Expected_packet_size_bits 用于获得稍慢的斜率
较低比特率下的附加值会增加。例如它可以是假设帧速率为 30,根据当前比特率计算每秒帧数:
每帧位数 = A_hat(i-1) / 30
每帧数据包 = ceil(每帧位数 / (1200 * 8))
avg_packet_size_bits = 每帧位数 / 每帧数据包数
由于系统依赖于过度使用通道来验证当前可用带宽估计,我们必须确保我们的估计值与发送者的速率没有偏差实际上发送。因此,如果发送者无法产生比特具有拥塞控制器要求的比特率的流,可用带宽估计应保持在给定范围内。
因此我们引入一个阈值A_hat(i) < 1.5 * R_hat(i)
当检测到过度使用时,系统会转为减少使用状态,其中基于延迟的可用带宽估计为减少到当前输入比特率的倍数。
A_hat(i) = beta * R_hat(i)
beta 通常选择在区间 [0.8, 0.95] 内,0.85 是推荐值。
当检测器向速率控制子系统发出未充分使用的信号时,我们知道网络路径中的队列正在被清空,表明
我们的可用带宽估计 A_hat 低于实际可用带宽。根据该信号,速率控制子系统将进入保持状态,此时接收端可用带宽在等待队列时估计值将保持不变稳定在较低水平 - 一种将延迟保持在较低水平的方法可能的。这种延迟的减少是我们所希望的,也是预期的,由于过度使用而减少估计值后立即,但是如果某些链路上的交叉流量减少,也会发生这种情况。
建议至少运行更新 A_hat(i) 的例程每个response_time间隔一次。
5.6. 参数设置
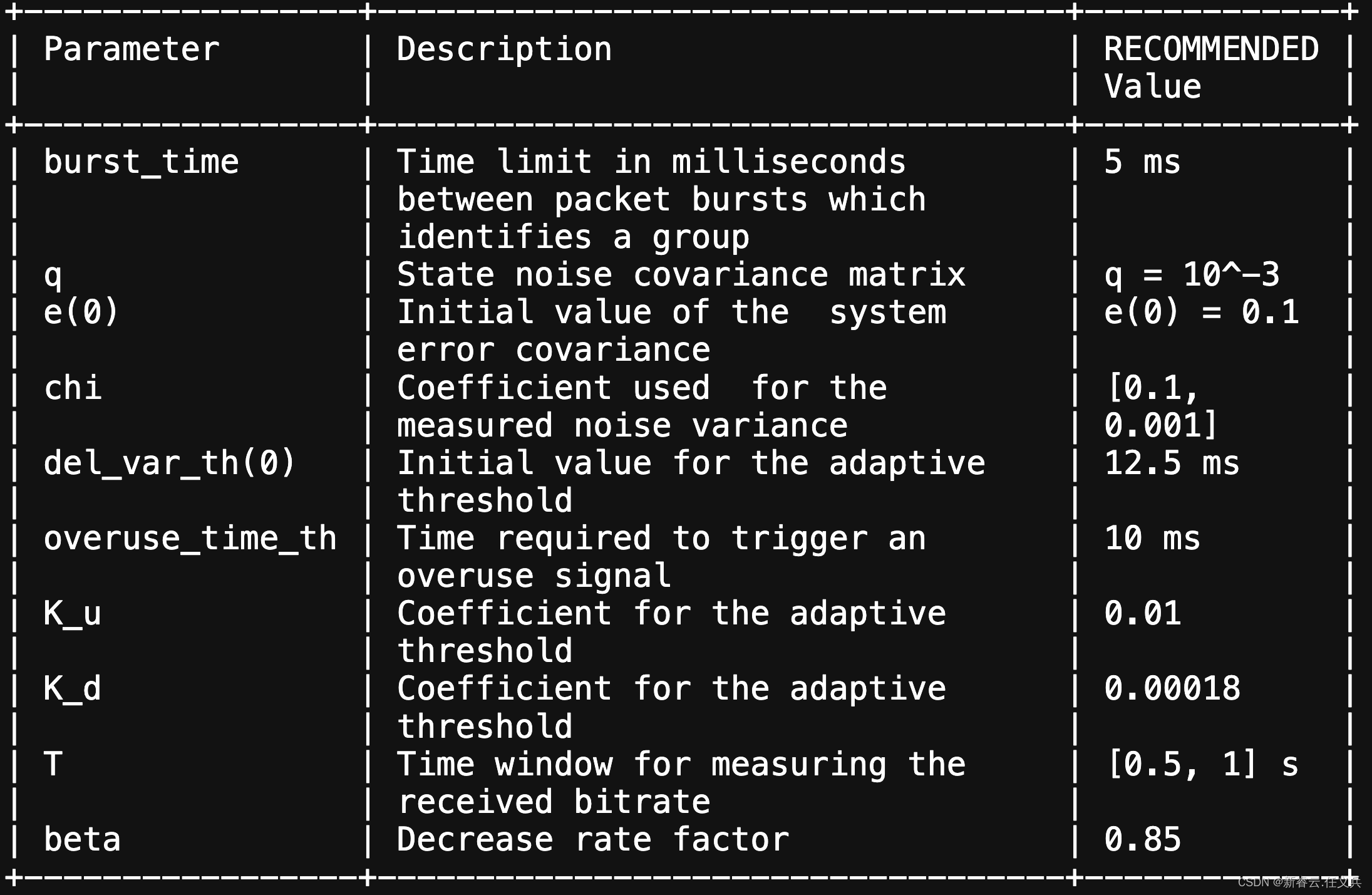
表 1:基于延迟的控制器的推荐值
6. 基于损失的控制
拥塞控制器的第二部分基于往返时间、数据包丢失和可用带宽估计 A_hat从基于延迟的控制器接收。可用带宽基于损失的控制器计算的估计值表示为正如那样。
基于延迟的网络产生的可用带宽估计 A_hat仅当队列的大小符合要求时,控制器才可靠路径足够大。如果队列很短,就会过度使用仅通过数据包丢失可见,而数据包未使用基于延迟的控制器。
基于损耗的控制器应该在每次反馈时运行接收器已收到。
o 如果自上次报告以来有 2-10% 的数据包丢失从接收器、发送器可用带宽估计As_hat(i) 将保持不变。
o 如果超过 10% 的数据包丢失,则新的估计值是计算公式为 As_hat(i) = As_hat(i-1)(1-0.5p),其中 p 是损失比率。
o 只要丢失的数据包少于 2% As_hat(i) 将增加为 As_hat(i) = 1.05(As_hat(i-1))
基于损失的估计 As_hat 与基于延迟的估计进行比较估计A_hat。实际发送速率设置为最小值介于 As_hat 和 A_hat 之间。
我们通过注意到如果传输通道由于过大而有少量丢包使用,如果发件人不调整他的金额,该金额很快就会增加比特率。因此我们很快就会达到 10% 的门槛以上并调整As_hat(i)。但如果丢包率不增加,损失可能与自己造成的无关拥塞,因此我们不应对它们做出反应。
7. 互操作性注意事项
如果实现这些算法的发送者与接收者对话不实现任何建议的 RTCP 消息和 RTP头扩展,建议发送方监听RTCP接收器报告并使用丢失数据包的比例和轮次跳闸时间作为基于损耗的控制器的输入。基于延迟的控制器应保持禁用状态。
八、实施经验
该算法已在开源WebRTC中实现
项目,自 M23 以来一直在 Chrome 中使用,并且正在使用谷歌环聊。
该算法的部署揭示了与以下相关的问题:
WiFi 网络拥塞或存在其他问题,导致算法改进。该算法还经过了测试多方会议场景,会议服务器终止端点之间的拥塞控制。这确保了拥塞控制没有做出任何假设最大发送和接收比特率等,通常超出会议服务器的控制。
9. 进一步的工作
该草案将作为拥塞控制讨论的输入。
在此基础上可以做的工作包括:
o 综合损失控制的考虑因素:损失和延误如何发生控制可以更好地集成,损失控制得到改善。
o 控制点考虑因素:评估绩效相比之下,所有拥塞控制逻辑都位于发送方发送者和接收者之间的逻辑分离。
o 使用 ECN 作为拥塞信号的考虑估计和链接过度使用检测。
10. IANA 考虑因素
本文件没有向 IANA 提出任何要求。
RFC 编辑注意:本节可能会在发布时作为RFC。
11. 安全考虑
攻击者能够在网络上插入或删除消息连接将有能力破坏速率控制。这可以使算法产生低于发送速率
利用瓶颈链路容量或发送速率过高造成网络拥塞。
在这种情况下,控制信息是在RTP内部携带的,并且可以使用 SRTP 防止修改或消息插入,就像媒体一样。鉴于RTP中携带时间戳标头未加密,因此不受保护披露,但似乎很难根据时机发起攻击仅供参考。
12. 致谢
感谢兰德尔·杰瑟普、马格努斯·韦斯特伦德、瓦伦·辛格、蒂姆·潘顿,周秀贤、吉姆·盖蒂斯、英格玛·约翰逊、迈克尔·韦尔茨尔和其他人对此早期版本提供了宝贵的反馈草稿。
13. 关于转载
转载此文请注明“引用于新睿云.弘电脑”,否则请回避。