目录
- 实验目的
- 整体思路
- 数据介绍
- 代码与实验步骤
4.1 爬虫代码
4.2 数据清洗
4.3 分词
4.4 去停用词
4.5 计算TF-IDF词频与聚类算法应用
4.6 生成词云图 - 实验结果
5.1 词云图
5.2 聚类结果分析 - 不足与反思
- 参考资料
1. 实验目的
掌握无监督学习问题的一般解决思路和具体解决办法;
熟悉 python sklearn 库的使用方法
2. 整体思路
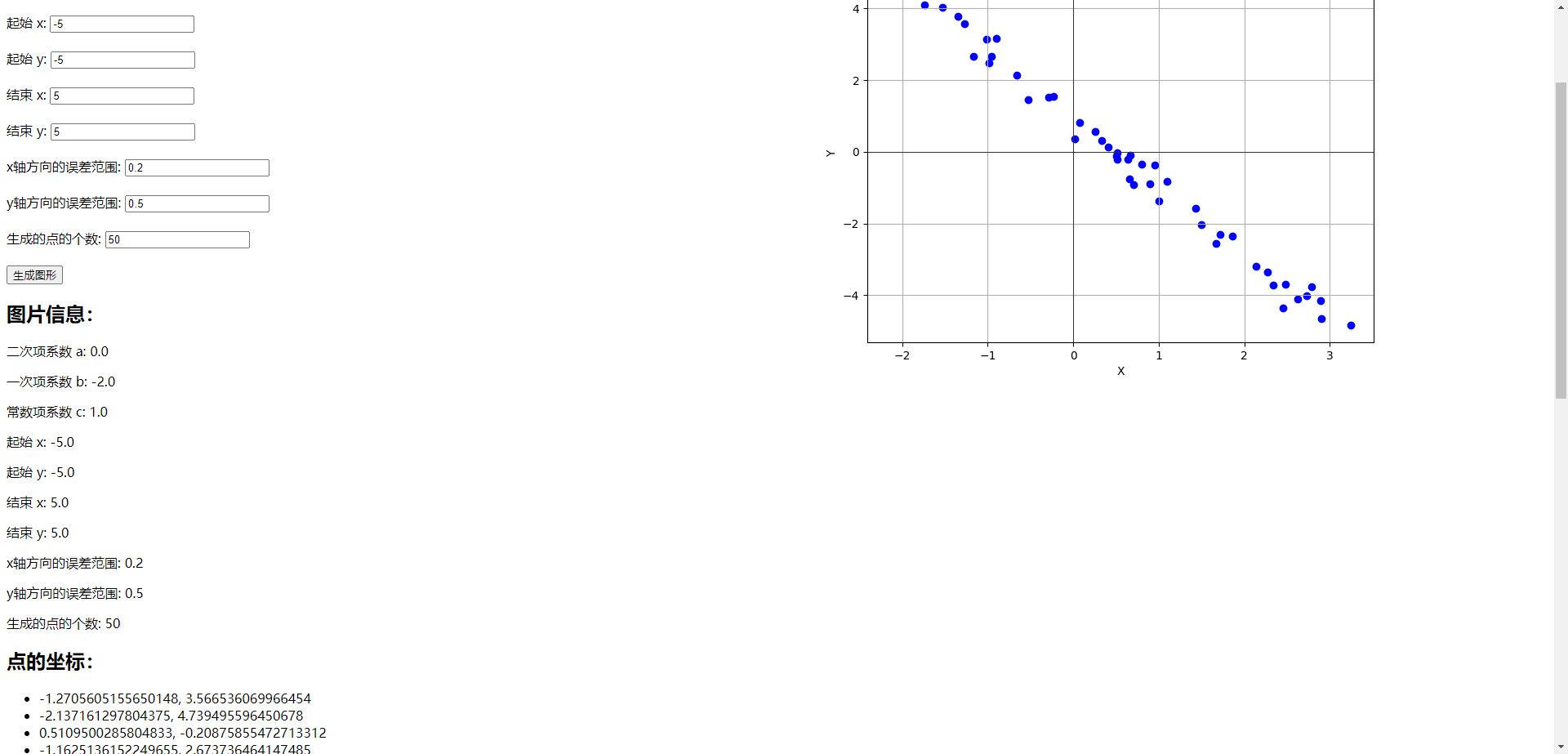
首先,通过 python 爬虫下载电商网站上关于某产品的用户评论数据;
其次,清洗数据(移除表情符号等)、分词、去停用词;
再次,计算每条评论的 TF-IDF 词频,使用 KMeans 算法进行聚类;
最后,通过词云工具,生成每个分类的词云图。
3. 数据介绍
电商评论数据选自京东 kindle 产品的全部用户评论,排序顺序为“推荐”。
4. 代码与实验步骤
4.1 爬虫代码
每页输出10条评论,遍历100页
# !/usr/bin/python
# -*- coding: utf-8 -*-
import urllib.request
import time
if __name__ == "__main__":
# JD的数据是以GBK编码的
f = open("jd-comments-json.txt", mode="w", encoding="gbk")
for i in range(100):
# 每页数据量为 50 条
url = "https://sclub.jd.com/comment/productPageComments.action?productId=2002883&score=0&sortType=5&page=" + str(i) + "&pageSize=10"
ret = urllib.request.urlopen(url).read().decode("gbk")
f.write("%s\n" % ret)
print("%d %s" % (i, ret))
time.sleep(i % 2) # 爬虫的节操:不能拖垮人家的数据库
4.2 数据清洗
主要是去除表情符号,因为表情符号存在的情况不多,所以这部分工作是手动进行的。
评论数据是以 JSON 格式从京东上面下载的,所以需要对JSON进行解析。
# !/usr/bin/python
# -*- coding: utf-8 -*-
import json
if __name__ == "__main__":
f_comment = open("comments.txt", encoding="gbk", mode="w")
with open("jd-comments-json.txt", encoding="gbk") as f:
for line in f:
s = json.loads(line.strip())
comments = s["comments"]
for comment in comments:
content = comment['content'].replace("\n", "")
f_comment.write("%s\n" % content)
4.3 分词
分词工具使用的是哈工大开发的语言技术平台云,通过 REST 调用的方式对每一条评论都分好了词
# !/usr/bin/python
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import time
def word_seg(sentence):
url = "http://api.ltp-cloud.com/analysis/"
args = {
"api_key" : "your-api-key",
'text' : sentence,
'format' : 'plain',
'pattern' : 'ws'
}
ret = urllib.request.urlopen(url, urllib.parse.urlencode(args).encode(encoding="utf-8"))
return ret.read().decode(encoding="utf-8")
if __name__ == "__main__":
f_in = open("comments-utf8.txt", encoding="utf8")
f_out = open("comments-ws.txt", encoding="utf-8", mode="w")
for line in f_in:
ret = word_seg(line.strip()).replace("\n", " ")
print(ret)
f_out.write("%s\n" % ret)
time.sleep(0.5)
4.4 去停用词
去掉分词结果中:的、了,以及各种标点符号。
# !/usr/bin/python
# -*- coding: utf-8 -*-
stop_word = ("的", "了",",", "、", "。", ";", "!", "*", ":", "~")
f_out = open("comments-processed.txt", encoding="utf-8", mode="w")
with open("comments-ws.txt", encoding="utf-8") as f:
for line in f:
line = line.strip()
sen = ""
for c in line:
if c not in stop_word:
sen = sen + c
for word in sen.split(" "):
if len(word) != 0:
f_out.write("%s " % word)
f_out.write("\n")
4.5 计算TF-IDF词频与聚类算法应用
本部分代码参考了CSDN博客[2]
# !/usr/bin/python
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
if __name__ == "__main__":
corpus = list()
with open("comments-processed.txt", encoding="utf-8") as f:
for line in f:
corpus.append(line.strip())
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
clf = KMeans(n_clusters=5) # 假设数据内在地分为 5 组
resul = clf.fit(weight)
with open("comments-processed.txt", encoding="utf-8") as f:
for i, line in enumerate(f):
group = clf.labels_[i]
f = open("group-" + str(group) + ".txt", encoding="utf-8", mode="a")
f.write("%s" % line)
f.close()
该代码将生成 5 份对评论聚类后的文件,分别是 group-0.txt,group-1.txt,......,group-4.txt。
其中,每个文件的内容都将是改组别下的评论数据。
4.6 生成词云图
采用了一款工具[3][3],而没有使用代码实现。
5 实验结果
5.1 词云图
5.1.1 第 0 组词云图 5.1.2 第 1 组词云图
5.1.2 第 1 组词云图
 5.1.3 第 2 组词云图
5.1.3 第 2 组词云图
 5.1.5 第 4 组词云图
5.1.5 第 4 组词云图

5.2 聚类结果分析
5.2.1 第 1 组
共 89 条记录,举例如下:
确实 不错 比 手机 看 书 好 多 了 不 刺眼 可以 总 邮箱 把 TXT 传 到 这 上面 自动 就 转换 了 挺 方便
很 不错 东东 主要 是 比 实体 书 带 着 方便 很多
很 好 用 跟 纸张 看 书 效果 很 像 携带 也 很 方便
5.2.2 第 2 组
共 167 条记录,举例如下:
确实 不错 感觉 比 平板省 眼睛 而且 这个 续航 比较 牛 确实 不错
送货 速度 快 价廉物美 有 了 这个 看 书 眼睛 就 不 会 很 累 真 不错
5.2.3 第 3 组
共 117 条记录,举例如下:
宝贝 很 好 看 书 很 舒服 不 似 手机 一样 会 眼睛 疲劳 干涩 这 是 我 第一 部 阅读器 很 喜欢 也 经常 在 京东 买 东西 一直 很 满意
喜欢 小巧 轻便 可以 尽情 看看看 了 再 也 不 担心 眼睛 痛 问题 了 看 一 下午 眼睛 疲惫感 还 好
5.2.4 第 4 组
共 77 条记录,举例如下:
东西 很 好 也 没有 出现 亮点 很 完美 物流 也 很快
东西 还 不错 就是 就是 反应 有 点 慢
5.2.5 第 5 组
共 548 条记录,举例如下:
kindl 读书 装 B 一条龙 服务
一直 没 买 kendle 这 次 买 回来
6.不足与反思
- 写爬虫时我没有考虑到“中评”、“差评”的情况,所以该实验的数据集是有偏见的;
- 由于时间仓促,没有使用对评论数据分类效果最好的 惩罚GMM聚类算法[1]惩罚���聚类算法[1];
- 即便是对评论进行了聚类,但是聚类的结果从实际的角度来考虑,并没有发现其用处;
- 考察聚类结果发现,各个类别下面的数据量分布不均匀,第4组数据量达 500+ 条,但第 0、1、2 组仅90+ 条。