在现代web开发中,Node.js因其高效和灵活性而备受青睐。其中,中间件的概念是构建高效Node.js应用的关键。在这篇博客文章中,我们将深入探讨Node.js中间件的高级应用,包括创建自定义中间件、使用第三方中间件等。我们将从基础讲起,逐步深入,旨在为读者提供全面而深入的指南。
中间件简介
在Node.js中,中间件是一个函数,它可以访问请求对象(req)、响应对象(res)和应用程序的请求/响应循环中的下一个中间件函数。这些函数可以执行以下任务:
- 执行任何代码。
- 修改请求和响应对象。
- 结束请求/响应循环。
- 调用堆栈中的下一个中间件函数。
如果当前中间件函数没有结束请求/响应循环,它必须调用next()方法将控制权传递给下一个中间件函数,否则请求将被挂起。
中间件的类型
在 Node.js 中,根据用途和功能的不同,中间件大体可以分为以下几类:
-
应用级中间件: 通过使用
app.use()和app.METHOD()函数加载,并且可以执行任何代码、修改请求和响应对象、结束请求-响应循环、调用下一个中间件。 -
路由级中间件: 和应用级中间件相似,但它绑定到一个实例上 express.Router()。
-
错误处理中间件: 用来处理应用中发生的各种错误。这类中间件通常定义了四个参数
(err, req, res, next)。 -
内置中间件: Express 框架自带的中间件,例如
express.static,用于提供静态资源。 -
第三方中间件: 由社区开发,需要通过 npm 安装,可以提供额外的功能,比如解析请求体、处理 cookie 等。
创建自定义中间件
自定义中间件是扩展Express应用功能的基石。它允许我们对进入的请求进行预处理、实施安全检查、处理日志等。
示例:追踪请求时间
// 追踪请求处理时间的中间件
function requestTimeLogger(req, res, next) {const start = Date.now(); // 请求开始时间res.on('finish', () => { // 响应结束时触发const duration = Date.now() - start; // 计算处理时长console.log(`${req.method} ${req.url} - ${duration}ms`); // 记录请求方法、URL和处理时长});next(); // 继续处理请求
}app.use(requestTimeLogger); // 将中间件添加到应用中
运行结果:
结合之前学过的books demo完成测试:

使用express.static提供静态文件服务
const express = require('express');
app.use(express.static('public')); // `public`目录下的文件现在可以通过Web访问了
创建public文件夹,在该文件夹下创建index.html文件,打开本地服务默认为index页面
使用第三方中间件
第三方中间件大大简化了常见功能的实现,如体解析、Cookie处理等。
示例:使用cors中间件管理跨源请求
const cors = require('cors'); // 引入cors中间件app.use(cors()); // 应用cors中间件,允许所有跨域请求
这行代码使得我们的Node.js应用可以接受跨域请求,极大地简化了配置过程
响应格式化中间件
// 响应格式化中间件
function responseFormatter(req, res, next) {res.apiResponse = (data, error = null) => {if (error) {res.status(500).json({ success: false, error }); // 发送错误响应} else {res.status(200).json({ success: true, data }); // 发送成功响应}};next();
}app.use(responseFormatter);
中间件组合应用
请求时间记录和请求大小限制
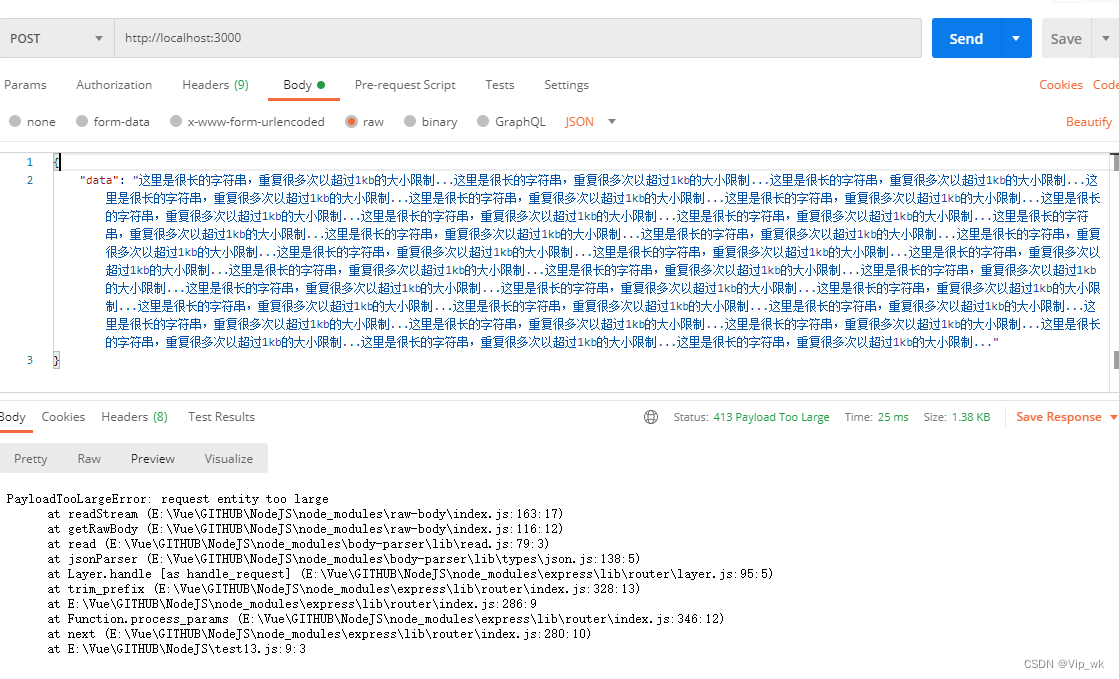
这个例子中,我们将使用两个自定义中间件,一个用于记录请求时间,另一个用于限制请求体的大小。
const express = require('express');
const bodyParser = require('body-parser');const app = express();// 中间件1: 记录请求时间
app.use((req, res, next) => {req.requestTime = Date.now(); // 添加一个新属性来保存请求时间next(); // 调用下一个中间件
});// 中间件2: 限制请求体的大小
app.use(bodyParser.json({ limit: '10kb' })); // 使用body-parser限制请求体大小为10kb// 路由处理
app.get('/', (req, res) => {const responseText = `Requested at: ${req.requestTime}`; // 使用中间件1添加的属性res.send(responseText);
});
// 测试限制请求体大小
app.post('/', (req, res) => {res.send('Received your request!');
});
// 添加错误处理中间件来观察限制
app.use((err, req, res, next) => {if (err instanceof SyntaxError && err.status === 400 && 'body' in err) {// 当请求体过大时,body-parser会抛出一个错误return res.status(413).send({ message: 'Request entity too large' });}// 如果不是请求体大小的问题,继续传递错误next(err);
});
// 启动服务器
app.listen(3000, () => {console.log('Server is running on port 3000');
});
运行结果:
条件性中间件和资源压缩
在这个例子中,我们将创建一个条件性中间件,用于根据请求的路径决定是否压缩响应。我们还会使用compression中间件来进行资源压缩。
const express = require('express');
const compression = require('compression');const app = express();// 条件性中间件: 只有请求路径为"/compress"时才使用compression中间件
app.use((req, res, next) => {if (req.path === '/compress') {compression()(req, res, next); // 调用compression中间件} else {next(); // 不需要压缩,直接调用下一个中间件}
});// 路由处理
app.get('/compress', (req, res) => {// 发送一个大文本,压缩后传输const largeText = '...'; // 假设这里是一个很大的文本内容res.send(largeText);
});app.get('/no-compress', (req, res) => {// 发送一个文本,不进行压缩res.send('This response is not compressed.');
});// 启动服务器
app.listen(3000, () => {console.log('Server is running on port 3000 with conditional compression');
});
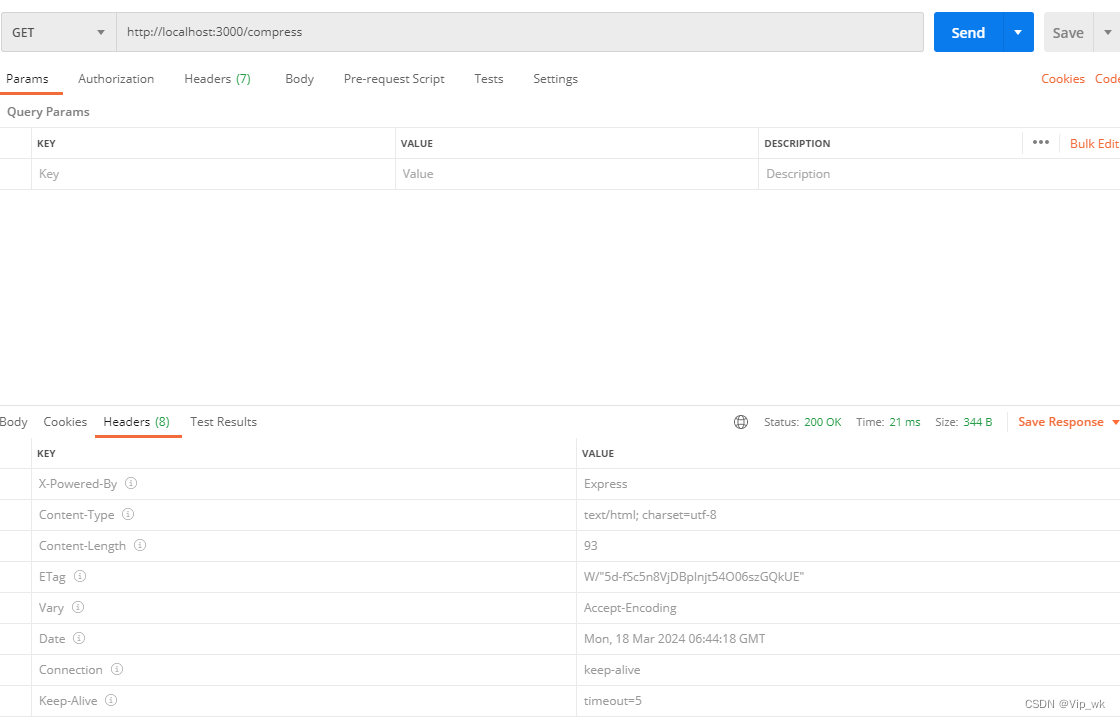
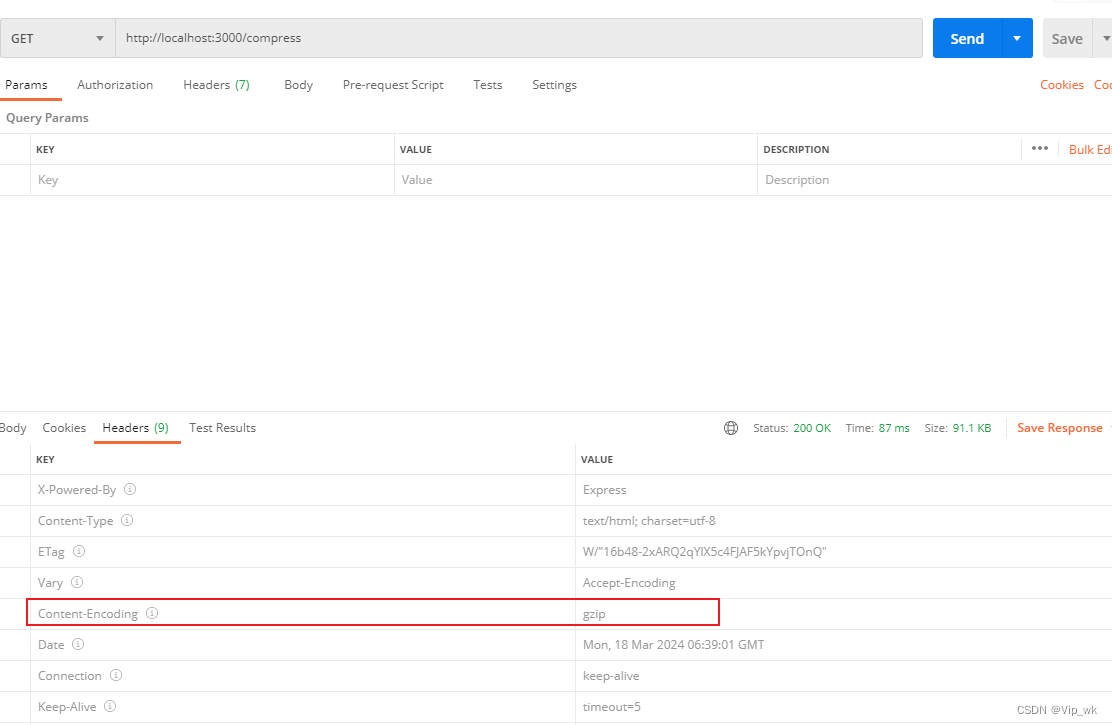
我们要做的是向/compress路由发送一个GET请求,并观察返回的响应头信息。检查响应头中的Content-Encoding是否包含gzip,这表明响应已经被压缩。
运行结果:
响应数据太小,没有达到压缩的阈值:
足够大的数据响应:
// 路由处理
app.get('/compress', (req, res) => {// 发送一个大文本,压缩后传输const largeText = '这是一个重复的大文本字符串,用于生成足够大的响应体来触发压缩。'.repeat(1000);res.send(largeText);
});
API速率限制和缓存
在这个例子中,我们将使用express-rate-limit来限制API的调用速率,以及使用简单的内存缓存来存储响应数据,减少重复计算。
mcache.put是memory-cache库中的一个方法,用于将数据存储在内存中。它接受三个参数:
key(字符串):用于存储和检索缓存值的唯一标识符。
value(任意类型):要存储在缓存中的数据。
time(毫秒):缓存数据在内存中存储的时间。超过这个时间后,数据将从缓存中删除。
const express = require('express');
const rateLimit = require('express-rate-limit');
const mcache = require('memory-cache');const app = express();// API速率限制中间件
const limiter = rateLimit({windowMs: 15 * 60 * 1000, // 15分钟max: 100 // 在15分钟内每个IP最多100次请求
});// 应用API速率限制中间件
app.use('/api', limiter);// 缓存中间件
const cache = (duration) => {return (req, res, next) => {let key = '__express__' + req.originalUrl || req.url;let cachedBody = mcache.get(key);if (cachedBody) {res.send(cachedBody);return;} else {res.sendResponse = res.send;res.send = (body) => {mcache.put(key, body, duration * 1000);// 将响应体存储在缓存中,duration以秒为单位res.sendResponse(body);};next();}};
};// 路由处理
app.get('/api/expensive-data', cache(30), (req, res) => {// 假设这里有一些计算成本很高的数据生成过程const expensiveData = 'Expensive Data';res.send(expensiveData);
});// 启动服务器
app.listen(3000, () => {console.log('Server is running on port 3000 with rate limiting and caching');
});
限制API调用速率
为了测试例子3中限制API调用速率的功能,我们可以快速连续发送多个请求到服务器的/api路由。如果超过了限制的数量,服务器应该返回429状态码(Too Many Requests)。
使用curl命令来测试API速率限制:
for i in {1..101}; do curl -X GET http://localhost:3000/api/expensive-data; done
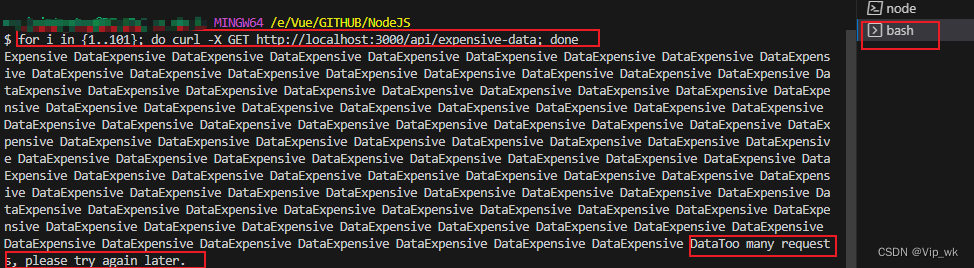
这个命令会连续发送101个GET请求到/api/expensive-data。由于我们设置了15分钟内每个IP最多100次请求,所以在第101次请求时,将会收到Too many requests, please try again later.
测试内存缓存
为了测试内存缓存的功能,我们可以发送两次请求到同一个路由,并观察响应时间。第一次请求会生成数据并将其缓存,而第二次请求应该会直接从缓存中获取数据,响应时间应该更短。
app.get('/api/cache-data', cache(30), (req, res) => {// 假设这里有一些计算成本很高的数据生成过程const largeText = '这是一个重复的大文本字符串,用于生成足够大的响应体来触发压缩。'.repeat(1000);res.send(largeText);
});
使用curl命令来测试内存缓存:
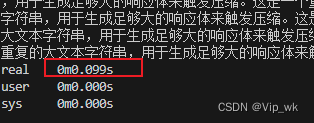
# 第一次请求
time curl -X GET http://localhost:3000/api/cache-data# 等待几秒钟# 第二次请求
time curl -X GET http://localhost:3000/api/cache-data
time命令会显示curl命令执行所需的时间。第二次请求应该比第一次快,因为它应该是从缓存中获取数据。
第一次:

第二次:
总结
在上述例子中,我们展示了如何使用Node.js中间件进行请求时间记录、请求大小限制、条件性资源压缩、API速率限制以及简单的内存缓存。这些中间件的组合运用能够帮助你构建更加健壮和高效的Node.js应用程序。