0. 总结
0.1 万字长文,当机器人拥抱大模型
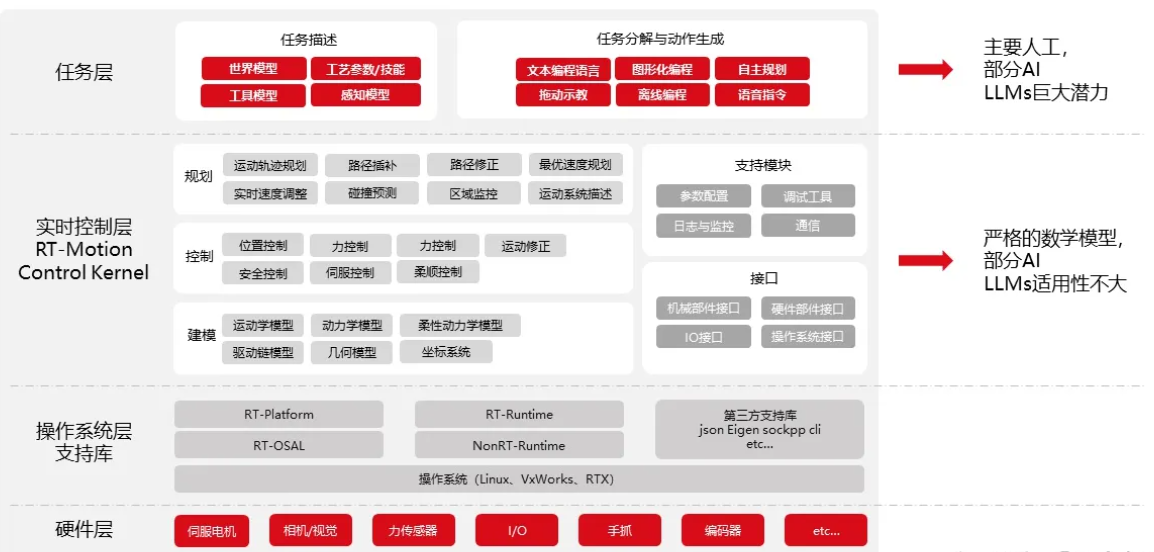
只需要告诉机器人它要做的任务是什么,机器人就会理解需要做的事情,拆分任务动作,生成应用层控制指令,并根据任务过程反馈修正动作,最终完成人类交给的任务。整个过程基本不需要或者仅需少量人类的介入和确认,基本实现了机器人自主化运行,无需掌握机器人专业操作知识的机器人应用工程师介入。
(0) My Conclusion:
解决数据,预设安全性,是这个领域的2个重点任务
(1) 挑战
(1-1)不确定的安全性
这里涉及的安全性包括两个部分,操作安全性与数据安全性,其中操作安全性又可分为任务级安全性与操作级安全性。
任务生成的安全性:虽然大模型具备很强的通识能力,但是如何保证每一次生成的任务都符合彼时情境的安全规范,仍然是一个需要持续优化的问题。
操作动作的安全性:除了以上需要常识就能解决的任务生成问题,在很多需要专业技能的领域机器人还要关注细微工艺动作是否符合安全规范,譬如在机器人手术中,机器人生成的磨削骨头或者切割软组织的某个细微动作是否符合手术手法要求,是否会对病人造成额外伤害,也是需要慎重考虑的问题。
(1-2) 高质量训练数据缺乏
机器人需要通过多种传感器感知环境状态,然后执行实际动作来完成任务,因此训练用于机器人的大模型需要用到大量机器人在真实世界中与环境进行交互的数据集。
0.2 大模型在机器人中的应用
具身AI Embodied Artificial Intelligence (微软)
Microsoft Research的Autonomous Systems and Robotics Group
ChatGPT for Robotics
AI研究者们开始不再满足于虚拟环境中的AI,开始希望AI能感知现实世界并与现实世界交互,这个方向在AI领域叫 Embodied AI(具身AI),主要涉及robotics的感知、规划、决策等上层部分。具身AI不再像传统AI仅从图像、视频、文本等数据库中学习,而是基于自身传感器(多是视觉传感器)感知环境并通过与环境交互进行学习(一般是强化学习方法**)**。


(0) My Conclusion:
SayCan:SayCan通过LLM和Afforddance Function模型的结合,在预定义的551种技能库中,选择有高概率的动作执行,完成从语言提示到任务级动作完成。
LM-Nav:LM-Nav通过结合三个预训练大模型LLM,VLM和VNM(视觉-导航模型),完成从语言提示到路径规划的执行。
PaLM-E:通过使用 PaLM-E 多模态大语言模型,添加物体的姿态信息,让机器人可以执行更细粒度的动作完成,比如将指定颜色的物体放入指定位置。
(1) SayCan
Do As I Can, Not As I Say (谷歌)
(2022年4月) M. Ahn et al., “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances.” arXiv, Aug. 16, 2022. doi: 10.48550/arXiv.2204.01691.
问一个LLM(大语言模型)如何清理桌子,LLM可能给出很好的回答,但是这些回答无法部署到实际机器人上。Google Robotics 2022年的工作SayCan为LLM与机器人结合提供了一个思路。SayCan背后的LLM是PalM (540B)。
SayCan的主要思想是LLM将抽象的高级指令拆解为动作(Say),然后有一个affordance function(来判断动作的可行性(Can)。在这个过程中,LLM扮演了推理决策的角色,将人类给出的抽象指令拆解为几个预先设定的子任务,为机器人提供可能的下一步的动作,affordance function(相当于评委)判断这个动作行不行。
实际要预先给定一系列机器人的动作序列,研究者针对17个物体、常见的7类动作(捡去、放置、布置、开抽屉、关抽屉、导航、特殊情形下的放置)共计可开发了551种技能(类似脚本)。人类给出一个抽象的指令,LLM给出下一步动作(对指令有帮助的)的概率分布,affordance 给出这个动作在当前状态下执行的概率(一般是根据视觉判断有没有这个东西),根据这两个概率的乘积选择下一步动作。
(2) LM-Nav
(2023年PMLR) D. Shah, B. Osinski, B. Ichter, and S. Levine, “LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action.” arXiv, Jul. 26, 2022. doi: 10.48550/arXiv.2207.04429. (谷歌)
LM-Nav这篇工作实现的效果为:人类向移动机器人给出一连串的自然语言导航指令,这些导航指令中有非常多的具有视觉特征的参照物(就好像你跟人问路别人跟你说在什么建筑附近左拐),然后LLM可以解析人类的自然语言,提取其中的关键地标信息的文本,然后通过视觉-文本多模态模型找到哪些图片出现了对应地标,然后机器人可以根据这些图片生成导航路径,自动找到说的地方。

整个系统由三个预训练的大模型组成:LLM (Large Language Model) + VLM (Vision and Language Model) + VNM (Visual Navigation Model)

三个模型结合相互结合,从自然语言(充满冗余的口语化描述)到文本(地标的字符串)到图像(根据文本找图像中的物体),最终生成机器人的路径规划。
- LLM(GPT-3)理解人类给出的自然语言,将话语中提到的文本提示中的解析为一系列地标。
- VLM (CLIP) 将文本和图像联系起来,在图像中找到LLM解析出来的地标。
- VNM (ViNG) 根据图像进行建图和导航。VNM可以根据一系列有时间(时间戳)和空间(GPS)信息的图片建立空间的拓扑图,生成简化的地图方便后续路径规划。
(3) PaLM-E
(2023年3月) D. Driess et al., “PaLM-E: An Embodied Multimodal Language Model.” arXiv, Mar. 06, 2023. Accessed: Mar. 20, 2023. [Online]. Available: http://arxiv.org/abs/2303.0337 (谷歌)
PaLM-E本身是个多模态的大模型,不仅能理解文本,还能理解图片(因为加了ViT),可以理解图片中的语义信息。

与谷歌之前两篇工作(SayCan和LM-Nav)相比,视觉-语言模型进一步提升,之前只是一张图片有对应语义信息(图片分类),谷歌在之前的基础上加入了物体实例级分割,得到了图片中物体的信息。并且将图片中物体的状态信息作为一个新的模态进行了编码,这也是PaLM-E的明显提升:新增了状态估计这个模态,这里状态估计包括机器人的状态,也包括物体的状态(比如位姿、大小、颜色等)。
所以我们可以看到通过PaLM-E可以让机器人执行下面视频这样推方块的任务。人类仅仅给出“将方块按颜色分类到角落”的自然语言指令,PaLM-E自己将任务拆解为什么颜色到什么角落,然后并且推动(有动力学的考量)各颜色方块到各个角落。