ElasticSearch基础概念以及可视化界面安装
文章目录
- ElasticSearch基础概念以及可视化界面安装
- 1、引言
- 2、基本概念
- 3、倒排索引机制
- 3.1、倒排索引
- 4、使用docker安装ElasticSearch
- 4.1、下载镜像文件
- 4.2 、创建实例,启动es
- 5.安装Kibana
1、引言
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的 接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。 是一种搜索引擎,依靠分词等多种方式实现许多数据库不能实现的搜索场景。
REST API:天然的跨平台。
官方文档:ES官方文档
官方中文:官方中文版文档
社区中文:
https://es.xiaoleilu.com/index.html
http://doc.codingdict.com/elasticsearch/0/
2、基本概念
Index:索引,相当于关系数据库中的database概念,是一类数据的集合,是一个逻辑概念。Type:类型,相当于数据库中的table概念,在6.0版本之前,一个Index中可以有多个type,7.0版本后彻底废弃多type,每个索引只能有一个type,即“ _doc”。这个概念就不用太关注了。Document:文档,存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。文档是Json格式的。Field:字段,存在于文档中,字段是包含数据的键值对,可以理解为Mysql一行数据的其中一列。Mapping:映射,是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的Mapping。
| Elasticsearch | Mysql |
|---|---|
| 索引(Index) | 库(Database) |
| 类型(Type) | 表(Table) |
| 文档(Document) | 行(Row) |
| 字段(Field) | 列(Column) |
| 映射(Mappings) | 表结构(schema) |
3、倒排索引机制
提到搜索,人们会立刻联想到在百度、谷歌上输入关键词获取相关的内容的场景。但搜索不等于百度,大部分APP支持的站内搜索更加大行其道。
数据库是储存和查询数据的利器,那么数据库是否适合做搜索呢?答案是不合适。第一个原因是,当数据库存储了大量数据后,查询效率大幅降低。
但是有些搜索场景,数据库也是不支持的,例如在下表中,我们试图通过“中国足球”这个关键词搜索数据,数据库是无法查询到相应内容的。
| id | name |
|---|---|
| 1 | 中国男子足球队 |
| 2 | 中国男子田径队 |
| 3 | 中国女子排球队 |
| 4 | 中国女子跳水队 |
3.1、倒排索引
什么是倒排索引?倒排索引也叫反向索引,我们通常理解的索引是通过key寻找value,与之相反,倒排索引是通过value寻找key,故而被称作反向索引。下面我们用一个简单的例子描述一下倒排索引的作用过程:假如现在有三份数据文档,内容分别是:
Doc 1:Java is the best programming languageDoc 2:PHP is the best programming languageDoc 3:Javascript is the best programming language
为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下:
| term | Doc 1 | Doc 2 | Doc 3 |
|---|---|---|---|
| Java | √ | ||
| is | √ | √ | √ |
| the | √ | √ | √ |
| best | √ | √ | √ |
| programming | √ | √ | √ |
| language | √ | √ | √ |
| PHP | √ | √ | |
| Javascript | √ | √ |
这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:

其中,几个核心术语需要着重理解:
- 词条(term):索引里面最小的存储和查询单元,对于英文来说是一个词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary):也叫字典,是词条的组合。搜索引擎的通常索引单位是单词,单词词典是文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向倒排所有的指针。
- 倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过及出现的位置。每个记录称为一个倒排项(Posting),倒排表记录的不单单是文档编号,还记录了词频等信息。
- 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene这种很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘。
相关性得分:以上面的图片为例,如果我们搜索 “Java is best”,我们会发现拆分的成三个单词,在文档一中命中(出现)了三个单词,文档二和文档三中命中了两个单词,那么文档一的相关性得分就最高。根据相关性得分从高到低排序,就会检索出相关的文档。
4、使用docker安装ElasticSearch
安装docker可以参考我的另一篇文章,直接从上到下傻瓜式安装。如下:
docker的介绍与安装
4.1、下载镜像文件
首先需要下载这两个镜像文件
docker pull elasticsearch:7.4.2 存储和检索数据引擎 docker pull kibana:7.4.2 可视化检索数据工具
4.2 、创建实例,启动es
mkdir -p /mydata/elasticsearch/config mkdir -p /mydata/elasticsearch/data --任何一台远程主机都可以访问
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml -- 保证权限
chmod -R 777 /mydata/elasticsearch/ -- 9200是发送http请求restful请求的,9300是es集群之间的通信端口,single-node 单节点运行,并指定es启动占用的内存
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
如果用docker ps 发现es没启动成功到/mydata/elasticsearch/路径下执行上面的chmod -R 777 /mydata/elasticsearch/ 保证赋予文件及子文件的权限为 RWX
然后重新启动elasticsearch。报错的话可以看对应的容器启动日志 ,报错一般都是因为上面run命令空格和换行问题
docker logs +`容器id前三位`
删除容器
docker rm 容器id
docker ps -a 查看es的容器id
文件权限没问题后用容器id启动es(比如我的容器id是 13e30b6e7c1a ),报错就看日志重新run启动
docker start 13e30b6e7c1a
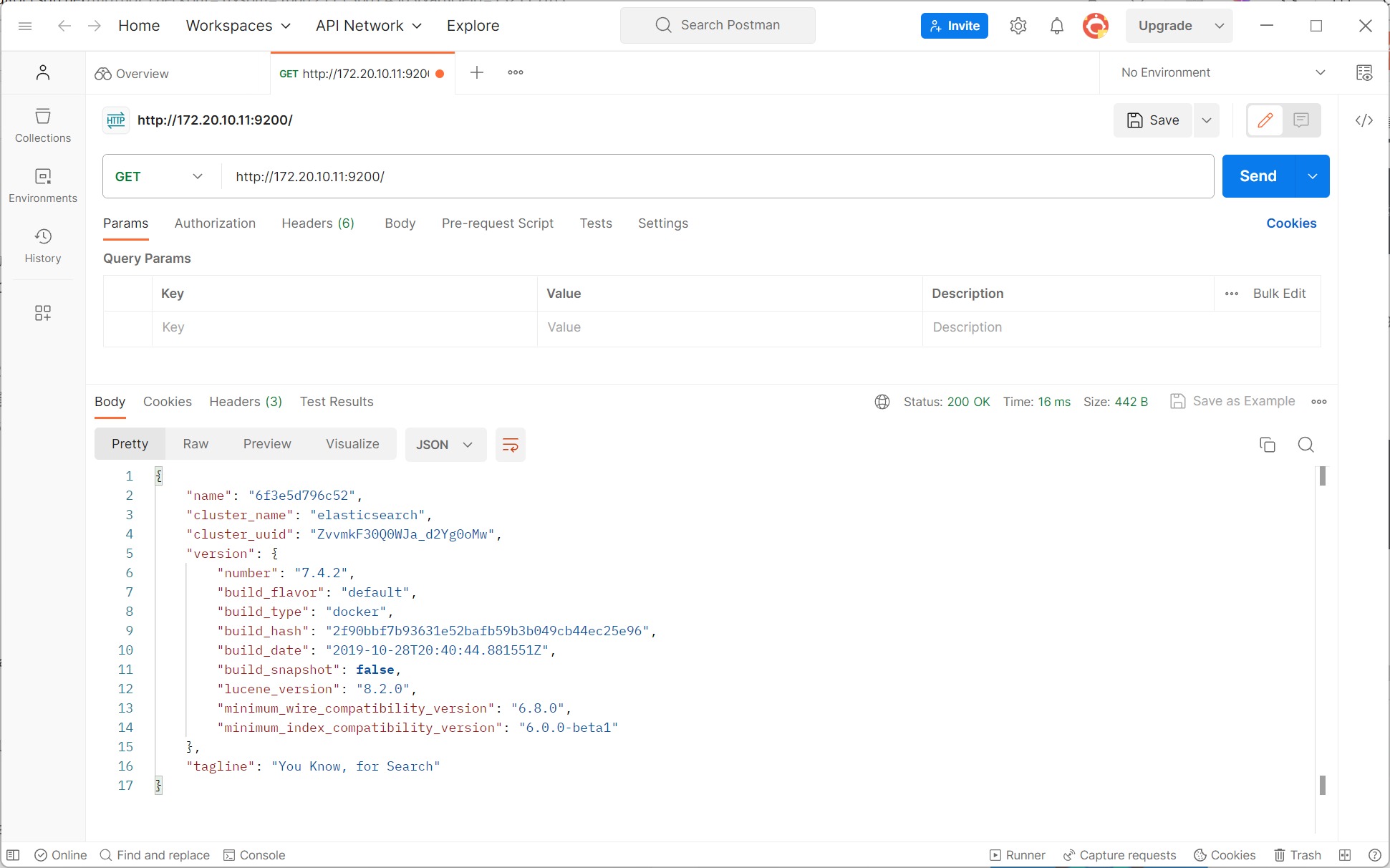
postman测试访问虚拟机9200端口的elasticSearch
5.安装Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://172.20.10.11:9200 -p 5601:5601 \
-d kibana:7.4.2172.20.10.11为自己的虚拟机ip ifconfig命令查看
访问虚拟机5601端口的Kibana
如下:安装成功