本文首发于公众号:机器感知
DreamPolisher、InternLM2 、AniArtAvatar、PlainMamba、AniPortrait
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion

We present DreamPolisher, a novel Gaussian Splatting based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions. While recent progress on text-to-3D generation methods have been promising, prevailing methods often fail to ensure view-consistency and textural richness. This problem becomes particularly noticeable for methods that work with text input alone. To address this, we propose a two-stage Gaussian Splatting based approach that enforces geometric consistency among views. Initially, a coarse 3D generation undergoes refinement via geometric optimization. Subsequently, we use a ControlNet driven refiner coupled with the geometric consistency term to improve both texture fidelity and overall consistency of the generated 3D asset. Empirical evaluations across diverse textual prompts spanning various object categories demonstrate the efficacy of DreamPolisher in generating consistent and realistic 3D objects, aligning closely with the semantics of the textual instructions.
InternLM2 Technical Report

The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
ALISA: Accelerating Large Language Model Inference via Sparsity-Aware KV Caching
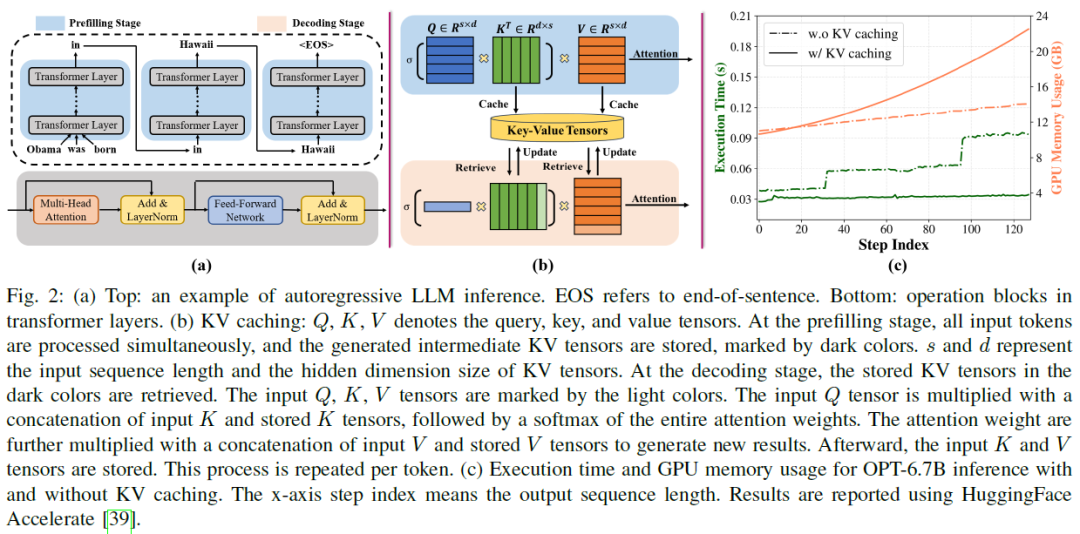
The Transformer architecture has significantly advanced natural language processing (NLP) and has been foundational in developing large language models (LLMs) such as LLaMA and OPT, which have come to dominate a broad range of NLP tasks. Despite their superior accuracy, LLMs present unique challenges in practical inference, concerning the compute and memory-intensive nature. Thanks to the autoregressive characteristic of LLM inference, KV caching for the attention layers in Transformers can effectively accelerate LLM inference by substituting quadratic-complexity computation with linear-complexity memory accesses. Yet, this approach requires increasing memory as demand grows for processing longer sequences. The overhead leads to reduced throughput due to I/O bottlenecks and even out-of-memory errors, particularly on resource-constrained systems like a single commodity GPU. In this paper, we propose ALISA, a novel algorithm-system co-design solution to address the challenges imposed by KV caching. On the algorithm level, ALISA prioritizes tokens that are most important in generating a new token via a Sparse Window Attention (SWA) algorithm. SWA introduces high sparsity in attention layers and reduces the memory footprint of KV caching at negligible accuracy loss. On the system level, ALISA employs three-phase token-level dynamical scheduling and optimizes the trade-off between caching and recomputation, thus maximizing the overall performance in resource-constrained systems. In a single GPU-CPU system, we demonstrate that under varying workloads, ALISA improves the throughput of baseline systems such as FlexGen and vLLM by up to 3X and 1.9X, respectively.
AniArtAvatar: Animatable 3D Art Avatar from a Single Image

We present a novel approach for generating animatable 3D-aware art avatars from a single image, with controllable facial expressions, head poses, and shoulder movements. Unlike previous reenactment methods, our approach utilizes a view-conditioned 2D diffusion model to synthesize multi-view images from a single art portrait with a neutral expression. With the generated colors and normals, we synthesize a static avatar using an SDF-based neural surface. For avatar animation, we extract control points, transfer the motion with these points, and deform the implicit canonical space. Firstly, we render the front image of the avatar, extract the 2D landmarks, and project them to the 3D space using a trained SDF network. We extract 3D driving landmarks using 3DMM and transfer the motion to the avatar landmarks. To animate the avatar pose, we manually set the body height and bound the head and torso of an avatar with two cages. The head and torso can be animated by transforming the two cages. Our approach is a one-shot pipeline that can be applied to various styles. Experiments demonstrate that our method can generate high-quality 3D art avatars with desired control over different motions.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation

Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation

In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks. Subsequently, we employ a robust diffusion model, coupled with a motion module, to convert the landmark sequence into photorealistic and temporally consistent portrait animation. Experimental results demonstrate the superiority of AniPortrait in terms of facial naturalness, pose diversity, and visual quality, thereby offering an enhanced perceptual experience. Moreover, our methodology exhibits considerable potential in terms of flexibility and controllability, which can be effectively applied in areas such as facial motion editing or face reenactment. We release code and model weights at https://github.com/scutzzj/AniPortrait
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition

We present PlainMamba: a simple non-hierarchical state space model (SSM) designed for general visual recognition. The recent Mamba model has shown how SSMs can be highly competitive with other architectures on sequential data and initial attempts have been made to apply it to images. In this paper, we further adapt the selective scanning process of Mamba to the visual domain, enhancing its ability to learn features from two-dimensional images by (i) a continuous 2D scanning process that improves spatial continuity by ensuring adjacency of tokens in the scanning sequence, and (ii) direction-aware updating which enables the model to discern the spatial relations of tokens by encoding directional information. Our architecture is designed to be easy to use and easy to scale, formed by stacking identical PlainMamba blocks, resulting in a model with constant width throughout all layers. The architecture is further simplified by removing the need for special tokens. We evaluate PlainMamba on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves performance gains over previous non-hierarchical models and is competitive with hierarchical alternatives. For tasks requiring high-resolution inputs, in particular, PlainMamba requires much less computing while maintaining high performance. Code and models are available at https://github.com/ChenhongyiYang/PlainMamba
Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
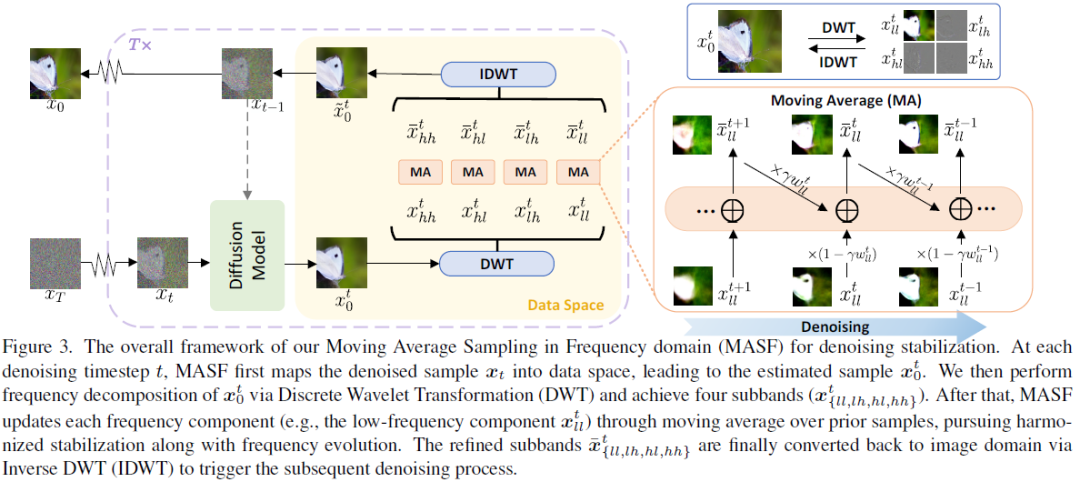
Diffusion models have recently brought a powerful revolution in image generation. Despite showing impressive generative capabilities, most of these models rely on the current sample to denoise the next one, possibly resulting in denoising instability. In this paper, we reinterpret the iterative denoising process as model optimization and leverage a moving average mechanism to ensemble all the prior samples. Instead of simply applying moving average to the denoised samples at different timesteps, we first map the denoised samples to data space and then perform moving average to avoid distribution shift across timesteps. In view that diffusion models evolve the recovery from low-frequency components to high-frequency details, we further decompose the samples into different frequency components and execute moving average separately on each component. We name the complete approach "Moving Average Sampling in Frequency domain (MASF)". MASF could be seamlessly integrated into mainstream pre-trained diffusion models and sampling schedules. Extensive experiments on both unconditional and conditional diffusion models demonstrate that our MASF leads to superior performances compared to the baselines, with almost negligible additional complexity cost.
Superior and Pragmatic Talking Face Generation with Teacher-Student Framework

Talking face generation technology creates talking videos from arbitrary appearance and motion signal, with the "arbitrary" offering ease of use but also introducing challenges in practical applications. Existing methods work well with standard inputs but suffer serious performance degradation with intricate real-world ones. Moreover, efficiency is also an important concern in deployment. To comprehensively address these issues, we introduce SuperFace, a teacher-student framework that balances quality, robustness, cost and editability. We first propose a simple but effective teacher model capable of handling inputs of varying qualities to generate high-quality results. Building on this, we devise an efficient distillation strategy to acquire an identity-specific student model that maintains quality with significantly reduced computational load. Our experiments validate that SuperFace offers a more comprehensive solution than existing methods for the four mentioned objectives, especially in reducing FLOPs by 99\% with the student model. SuperFace can be driven by both video and audio and allows for localized facial attributes editing.
TC4D: Trajectory-Conditioned Text-to-4D Generation
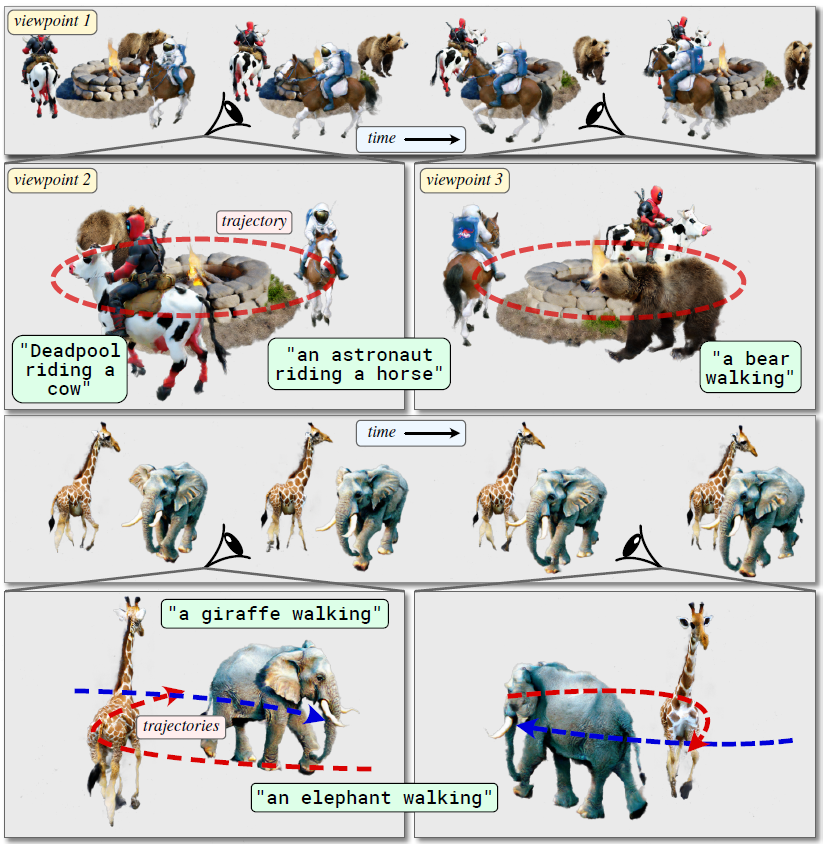
Recent techniques for text-to-4D generation synthesize dynamic 3D scenes using supervision from pre-trained text-to-video models. However, existing representations for motion, such as deformation models or time-dependent neural representations, are limited in the amount of motion they can generate-they cannot synthesize motion extending far beyond the bounding box used for volume rendering. The lack of a more flexible motion model contributes to the gap in realism between 4D generation methods and recent, near-photorealistic video generation models. Here, we propose TC4D: trajectory-conditioned text-to-4D generation, which factors motion into global and local components. We represent the global motion of a scene's bounding box using rigid transformation along a trajectory parameterized by a spline. We learn local deformations that conform to the global trajectory using supervision from a text-to-video model. Our approach enables the synthesis of scenes animated along arbitrary trajectories, compositional scene generation, and significant improvements to the realism and amount of generated motion, which we evaluate qualitatively and through a user study. Video results can be viewed on our website: https://sherwinbahmani.github.io/tc4d.
ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
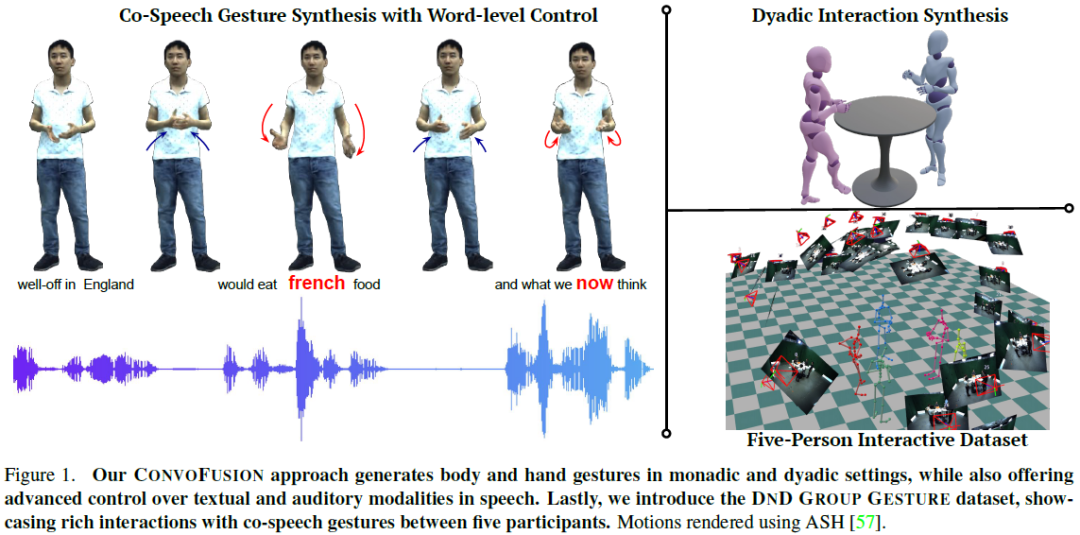
Gestures play a key role in human communication. Recent methods for co-speech gesture generation, while managing to generate beat-aligned motions, struggle generating gestures that are semantically aligned with the utterance. Compared to beat gestures that align naturally to the audio signal, semantically coherent gestures require modeling the complex interactions between the language and human motion, and can be controlled by focusing on certain words. Therefore, we present ConvoFusion, a diffusion-based approach for multi-modal gesture synthesis, which can not only generate gestures based on multi-modal speech inputs, but can also facilitate controllability in gesture synthesis. Our method proposes two guidance objectives that allow the users to modulate the impact of different conditioning modalities (e.g. audio vs text) as well as to choose certain words to be emphasized during gesturing. Our method is versatile in that it can be trained either for generating monologue gestures or even the conversational gestures. To further advance the research on multi-party interactive gestures, the DnD Group Gesture dataset is released, which contains 6 hours of gesture data showing 5 people interacting with one another. We compare our method with several recent works and demonstrate effectiveness of our method on a variety of tasks. We urge the reader to watch our supplementary video at our website.
Efficient Video Object Segmentation via Modulated Cross-Attention Memory

Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.