StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
2. 相关工作
4. 方法
4.1. 条件注意力模块
4.2. 外观保持模块
4.3. 自回归视频增强
5. 实验
5.2. 指标
0. 摘要
文本到视频扩散模型使得高质量视频的生成成为可能,这些视频遵循文本指令,从而轻松创建多样化和个性化的内容。然而,现有方法大多集中在生成高质量的短视频(通常为 16 或 24 帧),当简单地扩展到长视频合成时,会出现硬切换(hardcuts)。为了克服这些限制,我们引入了 StreamingT2V,这是一种用于生成 80、240、600、1200 帧或更多帧具有平滑过渡的长视频的自回归方法。关键组件包括:(i) 一种短期记忆块,称为条件注意力模块(conditional attention module,CAM),它通过注意机制将当前生成与从先前块(chunk)提取的特征相关联,从而实现一致的块过渡;(ii) 一种长期记忆块,称为外观保持模块(Appearance Preservation Module,APM),它从第一个视频块中提取高级场景和对象特征,以防止模型忘记初始场景;以及(iii) 一种随机混合(randomized blending)方法,使得将视频增强器自回归地应用于无限长视频时,不会出现块之间的不一致性。实验证明,StreamingT2V 生成了高运动量。相比之下,所有竞争的图像到视频方法在自回归方式下都容易出现视频停滞。因此,我们提出了StreamingT2V,这是一种高质量的无缝文本到长视频生成器,其在一致性和运动方面优于竞争对手。
项目页面:https://github.com/Picsart-AI-Research/StreamingT2V

2. 相关工作
文本引导视频扩散模型。使用扩散模型 [15, 33] 从文本指令生成视频是一个最近建立但非常活跃的研究领域,由视频扩散模型(VDM)[17] 引入。这种方法需要大量的训练资源,并且只能生成低分辨率视频(最高 128x128),生成的帧数最多为 16 帧(不包括自回归)。此外,文本到视频模型的训练通常是在诸如 WebVid-10M [3] 或 InternVid [41] 之类的大型数据集上进行的。几种方法 [5, 16, 17, 32] 采用在空间/时间上采样的形式进行视频增强,使用最多 7 个增强模块的级联 [16]。这种方法可以生成高分辨率和长视频。然而,生成的内容仍然受到关键帧的限制。
为了生成更长的视频(即更多的关键帧),
- Text-To-Video-Zero(T2V0)[18] 和 ART-V [42] 采用了文本到图像扩散模型。因此,它们只能生成简单的动画。T2V0 通过跨帧注意力以其第一帧为条件,而 ART-V 则以锚定帧为条件。由于缺乏全局推理,这导致了不自然或重复的动作。
- MTVG [23] 通过无需训练的方法将文本到视频模型转换为自回归方法。它在视频块之间采用强一致性先验,这导致运动量非常低,大部分是静态背景。
- FreeNoise [24] 对一小组噪声向量进行采样,并将它们用于所有帧的生成,同时在局部窗口上执行时间注意力。由于所使用的时间注意力对于这种帧重排是不变的,它导致帧之间的相似性很高,几乎总是静态的全局运动和近乎不变的视频。
- Gen-L [38] 生成重叠的短视频,并通过时间联合去噪进行聚合,这可能导致视频停滞而质量下降。
图像引导视频扩散模型作为长视频生成器。几项工作通过驱动图像或视频来调节视频生成 [4, 6–8, 10, 12, 21, 27, 40, 43, 44, 48]。它们因此可以通过以前一块的帧为条件,转变为自回归方法。
VideoDrafter [21] 使用文本到图像模型获取锚定帧。视频扩散以驱动锚(driving anchor)为条件,独立生成多个共享相同高级上下文的视频。然而,视频块之间没有一致性,导致场景剧烈切换。几项工作 [7, 8, 44] 将(编码的)条件与额外的掩码(指示提供了哪个帧)连接到视频扩散模型的输入中。
除了将条件连接到扩散模型的输入之外,几项工作 [4, 40, 48] 还通过将扩散模型的交叉注意力中的文本嵌入替换为条件帧的 CLIP [25] 图像嵌入。然而,根据我们的实验,它们在长视频生成方面的适用性有限。SVD [4] 显示随时间严重的质量下降(见图 7),而 I2VGen-XL[48] 和 SVD[4] 在块之间经常产生不一致性,仍然表明条件机制过于薄弱。
因此,一些工作 [6, 43],如 DynamiCrafter-XL [43],在每个文本交叉注意力中增加一个图像交叉注意力,这导致更好的质量,但仍然导致块之间频繁的不一致性。
同期工作 SparseCtrl [12] 向模型添加了一个类似 ControlNet [46] 的分支,它接受条件帧和一个指示帧的掩码作为输入。它设计上要求将由黑色像素组成的额外帧附加到条件帧上。这种不一致性对于模型来说难以补偿,导致帧之间频繁且严重的场景切换。 总的来说,目前只能一次生成少量关键帧,且质量较高。虽然可以对中间帧进行插值,但这并不会产生新内容。而且,虽然图像到视频的方法可以自回归使用,但它们所使用的条件机制要么导致不一致性,要么该方法会遭受视频停滞。我们得出结论,现有的工作不适用于高质量和一致性的长视频生成,而且不会出现视频停滞。
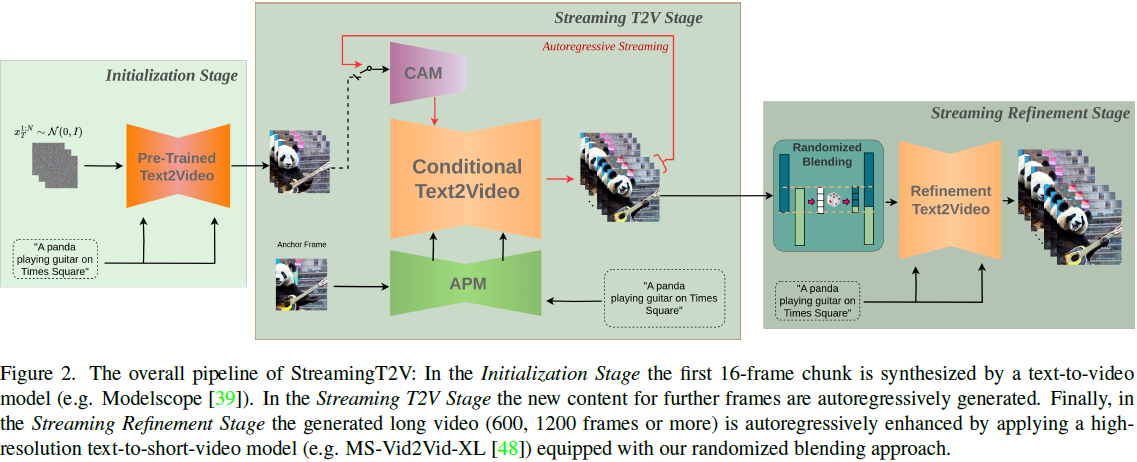
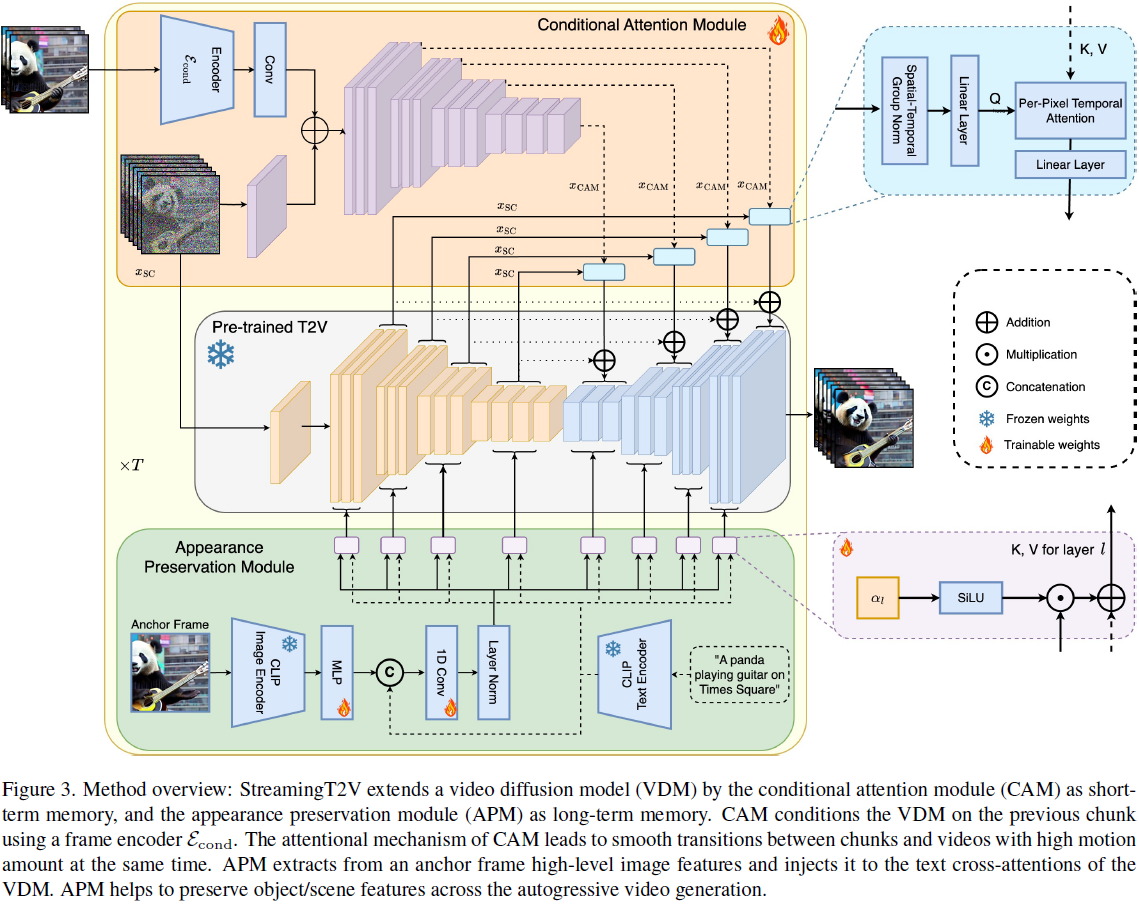
4. 方法
在本节中,我们介绍了用于高分辨率文本到长视频生成的方法。我们首先生成了 256 × 256 分辨率的长视频,时长为 5 秒(16fps),然后将它们提升到更高分辨率(720 × 720)。整个流程的概述如图 2 所示。长视频生成部分包括(初始化阶段)通过预先训练的文本到视频模型(例如可以使用 Modelscope [39])合成第一个 16 帧块(chunk),以及(Streaming T2V 阶段)通过自回归方式为后续帧生成新内容。对于自回归(见图 3),我们提出了条件注意力模块(CAM),利用前一块的最后 F_cond = 8 帧的短期信息,实现块之间的无缝过渡。此外,我们利用外观保持模块(APM),从一个固定的锚定帧中提取长期信息,使自回归过程在生成过程中能够稳健地保留对象外观或场景细节。
在生成了长视频(80、240、600、1200 帧或更多)之后,我们应用流式细化阶段(Streaming Refinement Stage),通过自回归方式应用高分辨率文本到短视频模型(例如可以使用 MS-Vid2Vid-XL [48]),并配备我们的随机混合方法进行无缝的块处理。后一步骤无需额外训练,因此使我们的方法在较低的计算成本下实现。
4.1. 条件注意力模块
为了训练我们 Streaming T2V 阶段的条件网络,我们利用了文本到视频模型的预训练能力(例如 Modelscope [39]),作为长视频生成的先验,以自回归的方式进行。在接下来的写作中,我们将这个预训练的文本到(短)视频模型称为 Video-LDM。为了通过前一块的一些短期信息(见图 2,中)自回归地调节 Video-LDM,受 ControlNet [46] 的启发,我们提出了条件注意力模块(CAM),它由特征提取器和一个注入到 Video-LDM UNet 中的特征注入器组成。特征提取器利用逐帧图像编码器 E_cond,后跟与 Video-LDM UNet 到其中间层相同编码器层(并使用 UNet 的权重进行初始化)。对于特征注入,我们让 UNet 中的每个长距离跳连接通过交叉注意力来关注由 CAM 生成的相应特征。
令 x 表示在零卷积后的 E_cond 的输出。我们使用加法,将 x 与 CAM 的第一个时间 transformer 块的输出融合。对于将 CAM 的特征注入到 Video-LDM Unet 中,我们考虑 UNet 的跳跃连接特征 x_SC ∈ R^(b×F×h×w×c)(见图3),其中 batch 大小为 b。我们对 x_SC 应用时空分组归一化(spatio-temporal group norm),并在 x_SC 上应用线性投影 P_in。让 x′_SC ∈ R^((b·w·h)×F×c) 表示重塑后的张量。我们通过时间多头注意力(T-MHA)[36],即对每个空间位置(和 batch)独立地,令 x′_SC 以相应的 CAM 特征 x_CAM ∈ R^((b·w·h)×F_cond×c) 为条件(见图3),其中 F_cond 是条件帧的数量。对于查询、键和值,使用可学习的线性映射 P_Q、P_K、P_V,我们应用 TMHA,其中键和值来自 x_CAM,而查询来自 x′_SC,即
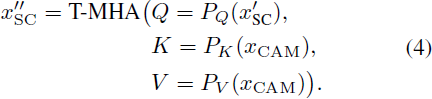
最后,我们使用线性投影 P_out。通过使用适当的重塑操作 R,将 CAM 的输出添加到跳跃连接中(与 ControlNet [46] 中的方式相同):
![]()
因此,x′′′ 在 UNet 的解码器层中使用。投影 P_out 是零初始化的,因此在训练开始时,CAM 不会影响基础模型的输出,这有助于提高训练的收敛性。
CAM 利用前一块的最后 F_cond 个条件帧作为输入。交叉注意力使得 CAM 能够以基础模型的 F 帧为条件。相反,稀疏编码器 [12] 使用卷积进行特征注入,因此需要额外的 F − F_cond 个零值帧(和一个掩码)作为输入,以便将输出添加到基础模型的 F 帧中。这给 SparseCtrl 的输入带来了不一致性,在生成的视频中导致严重的不一致性(见第 5.3 节和第 5.4 节)。
4.2. 外观保持模块
自回归视频生成器通常会忘记初始对象和场景特征,导致外观变化严重。为了解决这个问题,我们利用提出的外观保持模块(APM)来结合长期记忆,利用第一个块的固定锚定帧中包含的信息。这有助于在视频块生成过程中保持场景和对象特征(见图 6)。 为了使 APM 能够平衡锚定帧和文本指令的引导,我们提出(见图 3):
- 我们将锚定帧的 CLIP [25] 图像 token 与文本指令中的 CLIP 文本 token 混合,通过使用线性层将 clip 图像 token 扩展为 k = 8 个 token,并在 token 维度上连接文本和图像编码,然后使用投影块,得到 x_mixed ∈ R^(b×77×1024);
- 对于每个交叉注意力层 l,我们引入一个权重 α_l ∈ R(初始化为 0),通过对 x_mixed 和文本指令的常规 CLIP 文本编码的加权和来执行交叉注意力:
![]()
第 5.3 节的实验表明,轻量级的 APM 模块有助于在自回归过程中保持场景和身份特征(见图 6)。
4.3. 自回归视频增强
为了进一步提高我们文本到视频结果的质量和分辨率,我们利用一个高分辨率(1280x720)的文本到(短)视频模型(Refiner Video-LDM,见图 3),自回归地增强生成视频的 24 帧块。使用文本到视频模型作为 24 帧块的精化器/增强器是通过将大量噪声添加到输入视频块中,并使用文本到视频扩散模型(SDEdit [22] 方法)进行去噪来实现的。更具体地说,我们采用高分辨率文本到视频模型(例如 MS-Vid2Vid-XL [40, 48]),以及首先通过双线性上采样 [2] 将 24 帧的低分辨率视频块上采样到目标高分辨率。然后我们使用图像编码器 E 对帧进行编码,以获得潜在代码 x0。然后,我们应用 T′ < T 个前向扩散步骤,以便 x_T′ 仍包含信号信息(主要是关于视频结构),并使用高分辨率视频扩散模型进行去噪。

然而,独立增强每个块的简单方法会导致不一致的过渡(见图 4 (a))。我们通过在连续块之间使用共享噪声并利用我们的随机混合方法来解决这个问题。给定我们的低分辨率长视频,我们将其分割成 m 个长度为 F = 24 帧的块 V1,...,Vm,以便每两个连续的块具有 O = 8 帧的重叠。对于从步骤 t 开始的反向扩散,从 T′ 开始,我们必须采样噪声来执行一个去噪步骤。我们从第一个块 V1 开始,并采样噪声 ϵ_1 ∼ N(0, I),其中 ϵ_1 ∈ R^(F×h×w×c)。对于每个后续块 V_i,i > 1,我们采样噪声 ˆϵi ∼ N(0, I),其中 ˆϵi ∈ R^((F−O)×h×w×c),并沿帧维度将其与前一个块的 O 个重叠帧的噪声
![]()
连接,即
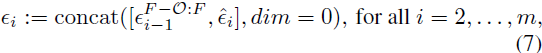
为了获得重叠帧的共享噪声,我们使用 ϵi 执行一个去噪步骤,并得到块 Vi 的潜在编码
![]()
然而,这种方法并不足以消除过渡不一致(见图 4 (b))。 为了显著提高一致性,我们提出了随机混合方法。考虑到连续两个块 V_(i−1)、Vi 在去噪步骤 t−1 时的潜在编码
![]()
块 V_(i−1) 的潜在编码 x_(t−1) (i−1) 在其前几帧到重叠帧之间具有平滑过渡,而块 Vi 的潜在编码 x_(t−1) (i) 在重叠帧到其后续帧之间具有平滑过渡。因此,我们通过串联两个潜在编码来组合它们:随机从 {0, . . . ,O} 中采样一个帧索引 f_thr,然后从
![]()
中取前 f_thr 帧的潜在编码,从
![]()
中取从 fthr + 1 开始的帧的潜在编码。然后,我们更新整个长视频的潜在编码 x_(t−1) 上的重叠帧,并执行下一个去噪步骤。因此,对于重叠区域和扩散步骤 t 中的帧 f ∈ {1, . . . ,O},块 V_(i−1) 的潜在编码被使用的概率为 1 − f / (O+1)。 通过在重叠区域中使用潜在编码的概率混合,我们成功地减少了块之间的不一致性(见图 4(c))。
5. 实验
5.2. 指标
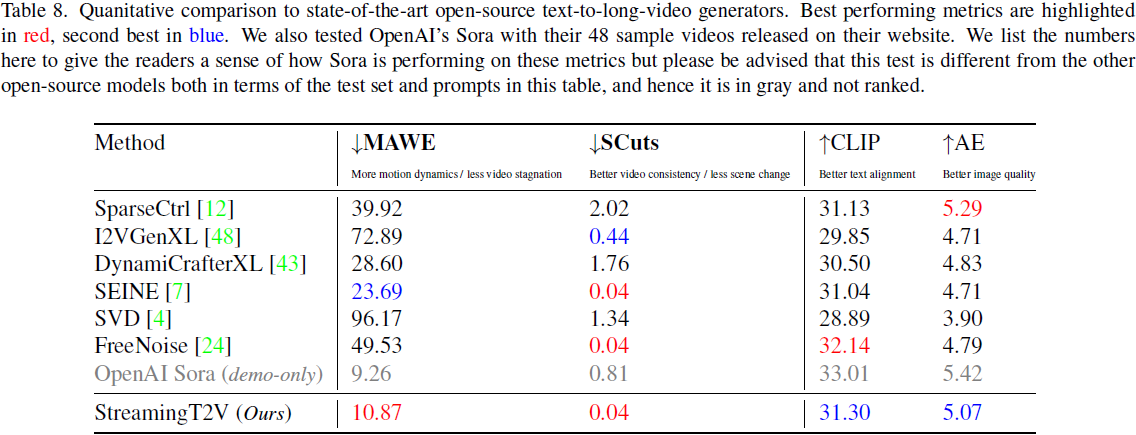
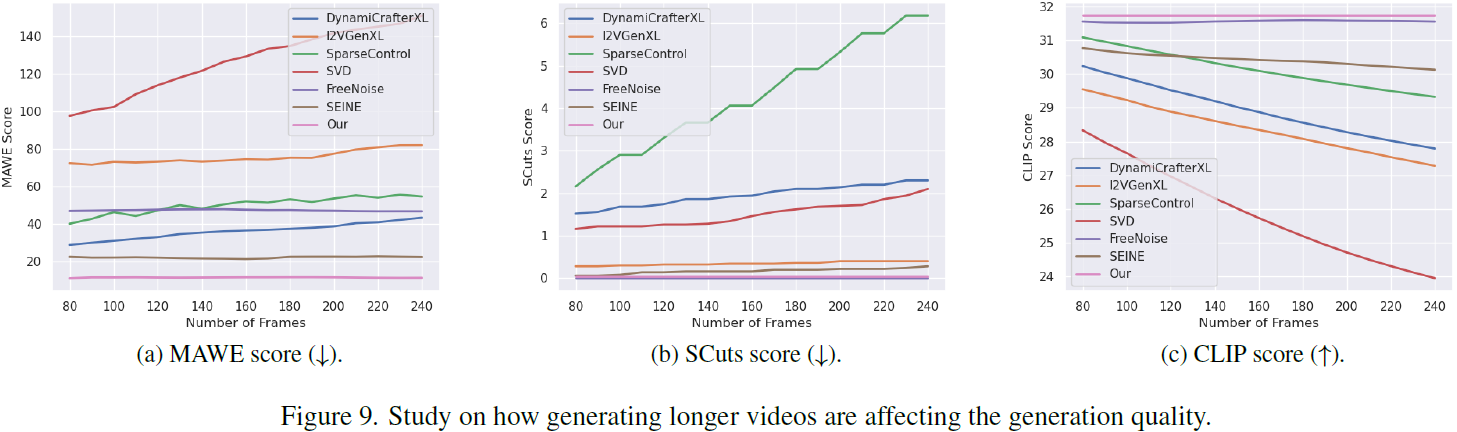
为了定量评估,我们采用了衡量我们方法的时间一致性、文本对齐和每帧质量的指标。
对于时间一致性,我们引入了 SCuts,它使用 PySceneDetect [1] 包的 AdaptiveDetector 算法,并使用默认参数,计算了视频中检测到的场景切换的数量。
此外,我们提出了一个新的指标称为运动感知变形误差(motion aware warp error,MAWE),它可以一致地评估运动量(motion amount)和变形误差(warp error),并且在视频表现出一致性和大量运动时产生较低的值。为此,我们使用 OFS(optical flow score,光流得分)来衡量运动量,它计算了视频中任意两个连续帧之间所有光流向量的平均幅值。此外,对于视频 V,我们考虑了平均变形误差 W(V) [19],它衡量了帧到其变形后帧的平均平方 L2 像素距离,排除了被遮挡的区域。最后,MAWE 定义为:
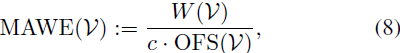
其中 c 对齐了两个指标的不同尺度。为此,我们对数据集验证视频的子集进行了回归分析,并获得了 c = 9.5(有关如何得出 c 的详细信息请参见附录)。MAWE 需要高运动量和低变形误差才能获得较低的指标值。对于涉及光流的指标,我们通过将所有视频调整为 720×720 分辨率进行计算。