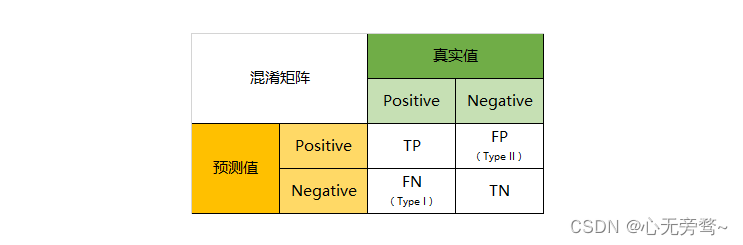
混淆矩阵(Confusion Matrix)是用于评估分类模型性能的一种表格形式。它显示了在分类问题中模型的预测结果与实际标签之间的各种组合情况。
混淆矩阵通常用于二分类问题,但也可以扩展到多分类问题。对于二分类问题,它由四个重要的指标组成:
真正例(True Positive, TP):模型预测为正例,并且实际上是正例的数量。
真反例(True Negative, TN):模型预测为反例,并且实际上是反例的数量。
假正例(False Positive, FP):模型预测为正例,但实际上是反例的数量。也称为"误报"。
假反例(False Negative, FN):模型预测为反例,但实际上是正例的数量。也称为"漏报"。
混淆矩阵的一般形式如下:
使用混淆矩阵可以计算多个衡量分类器性能的指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall,也称为敏感度或真正例率)和 F1 值等。这些指标可以通过混淆矩阵中的各个元素计算得出:
准确率(Accuracy):分类器预测正确的样本占总样本数的比例,计算公式为 (TP + TN) / (TP + TN + FP + FN) 。
精确率(Precision):正例预测正确的比例,计算公式为 TP / (TP + FP) 。
召回率(Recall):正例被正确预测为正例的比例,计算公式为 TP / (TP + FN) 。
F1 值:综合考虑了精确率和召回率的指标,计算公式为 2 (Precision Recall) / (Precision + Recall) 。
混淆矩阵提供了更详细和全面地评估分类模型性能的能力,帮助我们了解预测中的误报和漏报情况。通过分析混淆矩阵,我们可以获得对分类器在每个类别上的表现有关的宝贵见解,并对分类结果进行优化。
废话不多数,上代码:
def draw_confusion_matrix(label_true, label_pred, label_name, normlize, title="Confusion Matrix", pdf_save_path=None, dpi=100):"""@param label_true: 真实标签,比如[0,1,2,7,4,5,...]@param label_pred: 预测标签,比如[0,5,4,2,1,4,...]@param label_name: 标签名字,比如['cat','dog','flower',...]@param normlize: 是否设元素为百分比形式@param title: 图标题@param pdf_save_path: 是否保存,是则为保存路径pdf_save_path=xxx.png | xxx.pdf | ...等其他plt.savefig支持的保存格式@param dpi: 保存到文件的分辨率,论文一般要求至少300dpi@return:example:draw_confusion_matrix(label_true=y_gt,label_pred=y_pred,label_name=["Angry", "Disgust", "Fear", "Happy", "Sad", "Surprise", "Neutral"],normlize=True,title="Confusion Matrix on Fer2013",pdf_save_path="Confusion_Matrix_on_Fer2013.png",dpi=300)"""cm1=confusion_matrix(label_true, label_pred)cm = confusion_matrix(label_true, label_pred)if normlize:row_sums = np.sum(cm, axis=1)cm = cm / row_sums[:, np.newaxis]cm=cm.Tcm1=cm1.Tplt.imshow(cm, cmap='Blues')plt.title(title)plt.xlabel("Predict label")plt.ylabel("Truth label")plt.yticks(range(label_name.__len__()), label_name)plt.xticks(range(label_name.__len__()), label_name, rotation=45)plt.tight_layout()plt.colorbar()for i in range(label_name.__len__()):for j in range(label_name.__len__()):color = (1, 1, 1) if i == j else (0, 0, 0) # 对角线字体白色,其他黑色value = float(format('%.1f' % (cm[i, j]*100)))value1=str(value)+'%\n'+str(cm1[i, j])plt.text(i, j, value1, verticalalignment='center', horizontalalignment='center', color=color)# plt.show()if not pdf_save_path is None:plt.savefig(pdf_save_path, bbox_inches='tight',dpi=dpi)labels_name = ['bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']y_gt=[]
y_pred=[]model_weight_path = "./best_CBAM_model.pth"
models = Xception(num_classes = 4)
models.load_state_dict(torch.load(model_weight_path))models.eval()
for index, (imgs, labels) in enumerate(test_dl):labels_pd = models(imgs)predict_np = np.argmax(labels_pd.cpu().detach().numpy(), axis=-1).tolist()labels_np = labels.numpy().tolist()y_pred.extend(predict_np)y_gt.extend(labels_np)
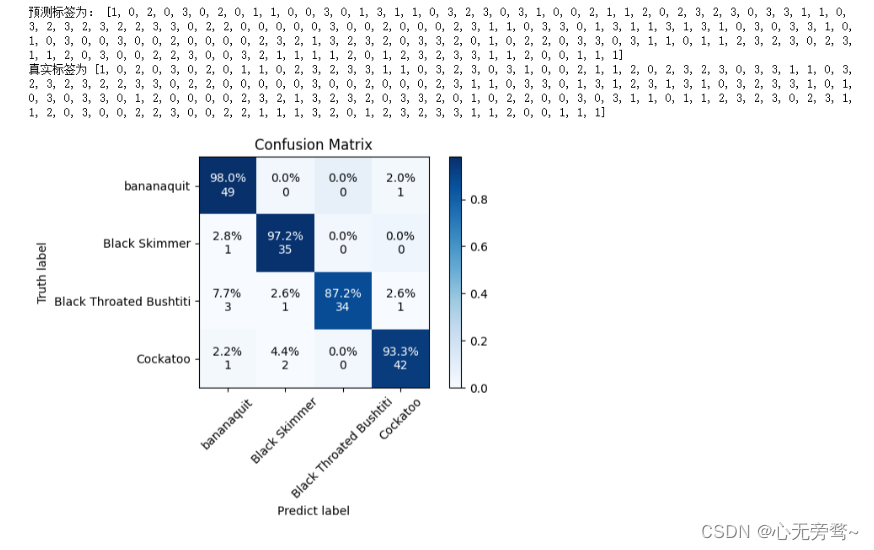
print("预测标签为:", y_pred)
print("真实标签为", y_gt)draw_confusion_matrix(label_true=y_gt,label_pred=y_pred,label_name=labels_name,normlize=True,title="Confusion Matrix",pdf_save_path="Confusion_Matrix.jpg",dpi=300)
结果如下: