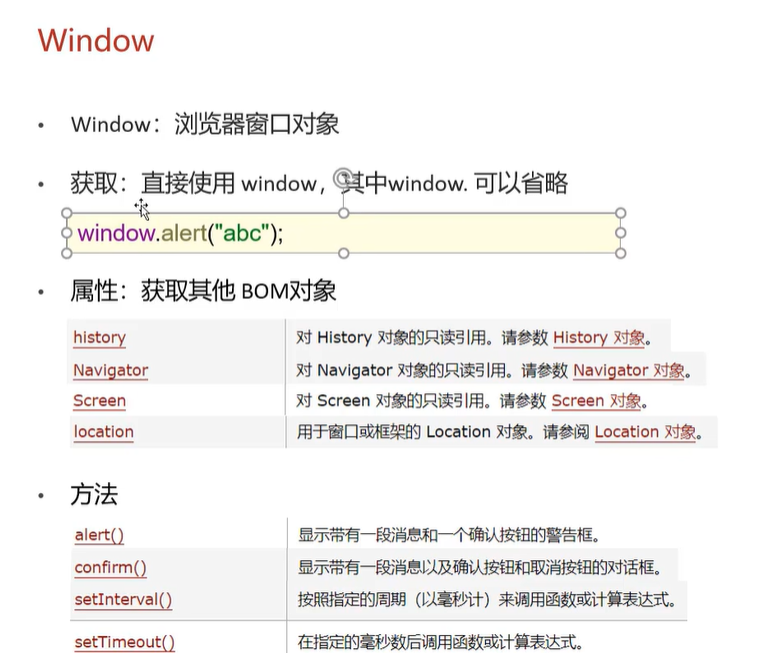
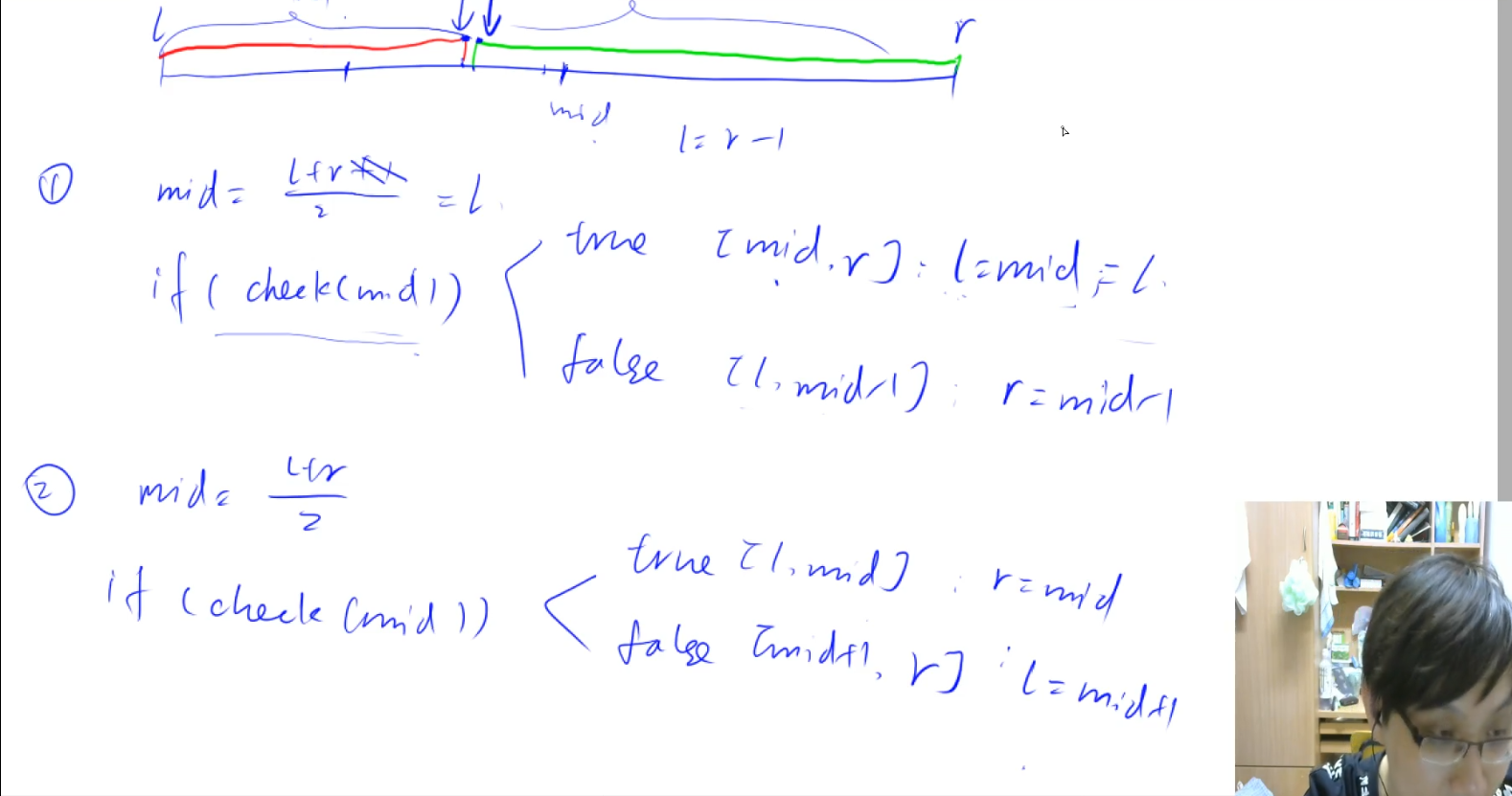
BGE(BAAI General Embedding)系列模型是智源研究院开发的高性能语义表征工具,其中bge-large-zh-v1.5和bge-reranker-large是两类不同功能的模型。它们的区别和联系如下:
核心区别
-
功能定位
- bge-large-zh-v1.5:属于Embedding模型,主要用于将文本(如句子或段落)转换为高维向量,以便通过向量相似度进行语义检索。它通过生成文本的向量表示,实现初步的语义匹配。
- bge-reranker-large:属于Reranker模型(重排序模型),用于对Embedding模型检索出的候选结果进行精细化排序。它通过分析查询与候选文本的深层语义关系,优化结果的排序,提升最终检索的准确性。
-
模型结构与输入输出
- Embedding模型(如
bge-large-zh-v1.5):接收单段文本,输出固定维度的向量(如1024维)。其核心是语义编码能力,适用于构建向量数据库和初步检索。 - Reranker模型:需要同时输入查询文本和候选文本,输出两者的相关性分数。其结构通常基于交叉编码(Cross-Encoder),通过联合编码查询和候选文本,计算细粒度匹配得分。
- Embedding模型(如
-
应用场景
- Embedding模型:适用于大规模数据的快速检索,例如构建知识库索引或实时搜索,但可能因语义分布偏差导致排序不够精确。
- Reranker模型:用于对少量候选结果(如Top-100)进行二次优化,解决Embedding模型的排序偏差问题,显著提升RAG(检索增强生成)系统的最终效果。
联系与协同
-
技术栈互补
- 在RAG系统中,通常联合使用两种模型:先用
bge-large-zh-v1.5进行粗粒度检索,再用bge-reranker-large对结果精排。这种两阶段流程结合了Embedding的高效性和Reranker的精准性,显著提升整体检索质量。
- 在RAG系统中,通常联合使用两种模型:先用
-
模型训练与优化
- 两者均基于BAAI的通用语义表征框架开发,共享部分预训练技术(如对比学习)。例如,BGE系列模型通过多语言、跨领域的预训练数据增强语义理解能力,而Reranker模型则在此基础上进一步优化交互式语义匹配。
-
性能指标
- 在评测中,
bge-large-zh-v1.5在中文Embedding模型中表现优异(如MTEB评测平均分54.21),而bge-reranker-large在重排任务中(如中文Reranking评测平均分67.89)显著优于其他模型,两者结合可达到SOTA(State-of-the-Art)效果。
- 在评测中,
实际应用案例
- QAnything系统:网易有道的开源项目QAnything采用
bge-large-zh-v1.5进行向量化检索,并通过bge-reranker-large优化排序。这种组合解决了大规模数据检索中的“退化问题”,实现了数据量越大、效果越好的特性。 - 安全领域微调:用户可通过领域数据(如安全论坛内容)对两种模型进行微调,进一步提升特定场景下的性能。例如,使用Triplet Loss优化Embedding模型,并结合Reranker的交叉编码能力增强排序效果。
总结
- 区别:Embedding模型负责生成向量,用于快速检索;Reranker模型负责精细化排序,提升结果相关性。
- 联系:两者均属BGE技术生态,协同使用可最大化RAG系统的检索精度。在实际应用中,推荐采用两阶段流程(Embedding检索 + Reranker排序)以平衡效率与效果。
注:以上内容由DeepSeek官方AI联网生成