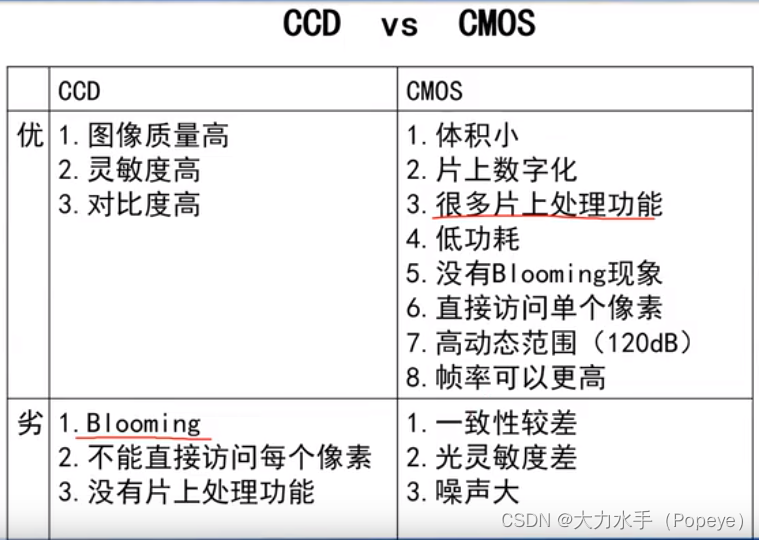
【八股】2024春招八股复习笔记2(大数据开发)
文章目录
- 1、大数据存储(Flume、Hive、HBase、HDFS)
- 2、大数据计算(MapReduce,Spark、Flink)
- 3、大数据集群(Yarn、ZooKeeper、kafka)
- 4、Java与408(CN+OS+DS,DB)
- 5、数仓与SQL(工作 & 项目实践)
- 6、面经真题
2023最新大数据开发面试笔记V4.0
大数据开发、Java、计算机基础、数仓理论、常考SQL、大数据开发场景题、大厂面经合集、大厂SQL真题、企业级调优手法、数据湖基础等十大模块。
【数据开发】大数据岗位,通用必备技术栈(数据分析、数据工程、数据科学)
- 离线数仓:Hadoop + Spark/Mapreduce + Hive/HDFS+ Impala + Sqoop/Kettle + Azkaban
- 实时数仓:Hadoop + Flink + Kafka + Hbase + Sqoop + Azkaban
- 大数据主流发展的都是实时方向,也有数据流,数据湖,以及湖仓一体。如果基于实时方向 Java/Scala 比SQL重要,而离线跑批 则是SQL,Shell,Perl/Python。
数据收集与存储
-
日志收集框架:Flume、Logstash、Filebeat
-
分布式文件存储系统:Hadoop HDFS
-
数据库系统:Mongodb、HBase
数据分析:
-
分布式计算框架: 批处理框架:Hadoop MapReduce 流处理框架:Storm 混合处理框架:Spark、Flink
-
查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
集群:高可用、任务调度、并发、迁移
- 集群资源管理器:Hadoop YARN
- 分布式协调服务:Zookeeper
- 任务调度框架:Azkaban、Oozie
- 集群部署和监控:Ambari、Cloudera Manager
- 数据迁移工具:Sqoop
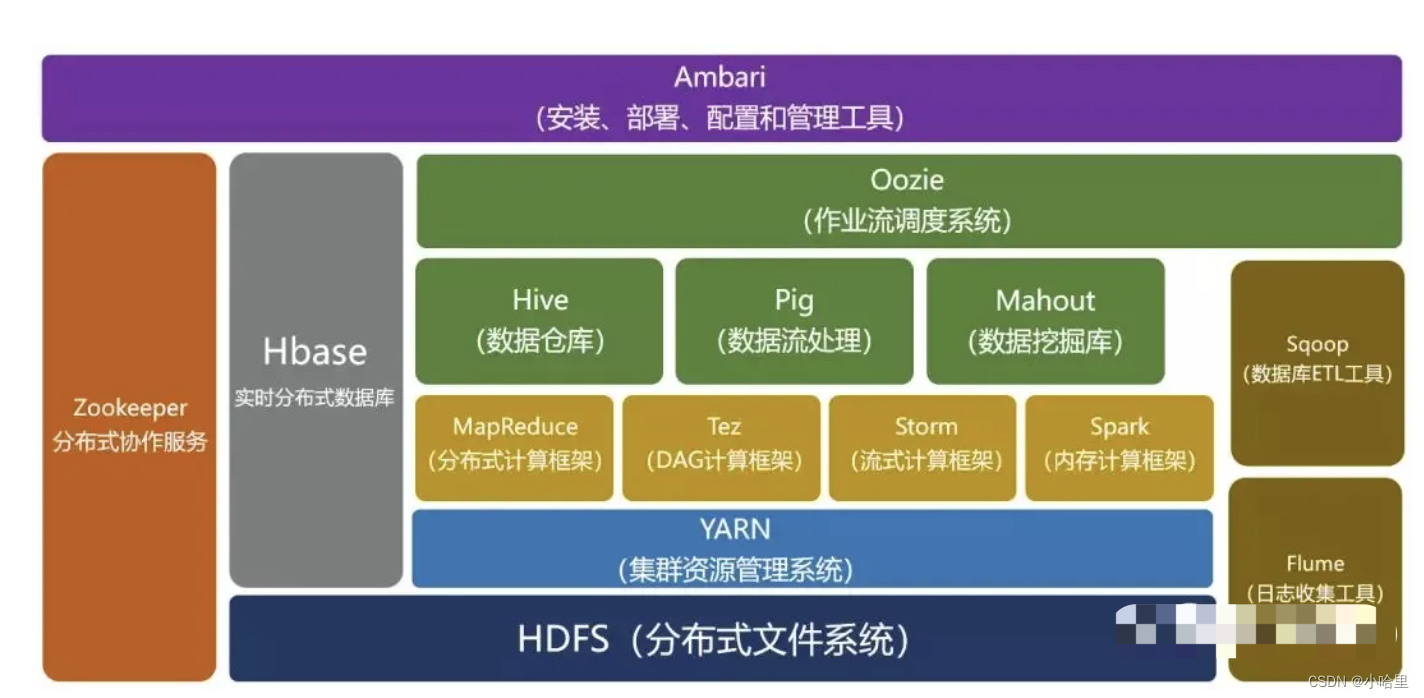
Hadoop是分布式框架的生态(是拥有20多个部件的生态系统,架构可参考)
1、大数据存储(Flume、Hive、HBase、HDFS)
Flume是收集数据
HDFS是文件系统(支持分布式,可对比NTFS)
Hive是数据仓库&批处理(SQL运行,对比MySQL)
Hbase是数据库管理(KV随机存储,对比redis)
———————————————Flume—————————————————————
Flume面试重点
看看这个图github
简述flume基础架构
- 外部数据源以特定格式向 Flume 发送
events(事件),当source接收到events时,它将其存储到一个或多个channel,channe会一直保存events直到它被sink所消费。sink的主要功能从channel中读取events,并将其存入外部存储系统或转发到下一个source,成功后再从channel中移除events。
请说一下你提到的几种source的不同点
- 数据收集组件,从外部数据源收集数据,并存储到 Channel 中。
简述flume的事务机制
Event是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个Event由标题和正文组成:前者是键/值映射,后者是任意字节数组。
Flume都有什么组件,
- 组件种类:Flume 中的每一个组件都提供了丰富的类型,适用于不同场景:
- Source 类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source; - Sink 类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等; - Channel 类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
channel的特性以及什么时候该用什么类型的channel,
Channel是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:Memory Channel: 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机);File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
除了Flume还有什么数据收集工具:
- DataX,Sqoop,它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。
———————————————HDFS—————————————————————
HDFS面试重点
1.HDFS的架构
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
- NameNode : 负责执行有关
文件系统命名空间的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。 - DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
2.HDFS的读写流程
- 数据复制:由于 Hadoop 被设计运行在廉价的机器上,这意味着硬件是不可靠的,为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)。
3.HDFS中,文件为什么以block块的方式存储
- 3.1 高容错:由于 HDFS 采用数据的多副本方案,所以部分硬件的损坏不会导致全部数据的丢失。
- 3.2 高吞吐量:HDFS 设计的重点是支持高吞吐量的数据访问,而不是低延迟的数据访问。
- 3.3 大文件支持:HDFS 适合于大文件的存储,文档的大小应该是是 GB 到 TB 级别的。
- 3.3 简单一致性模型:HDFS 更适合于一次写入多次读取 (write-once-read-many) 的访问模型。支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
- 3.4 跨平台移植性:HDFS 具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
———————————————HBase—————————————————————
HBase面试重点题
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
但是 Hadoop 的缺陷在于它只能执行批处理,并且只能以顺序方式访问数据,这意味着即使是最简单的工作,也必须搜索整个数据集,无法实现对数据的随机访问。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
简述HBase的数据模型
-
HBase 是一种类似于
Google’s Big Table的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。它具有以下特性:- 不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
- 由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
- 支持通过增加机器进行横向扩展;
- 支持数据分片;
- 支持 RegionServers 之间的自动故障转移;
- 易于使用的 Java 客户端 API;
- 支持 BlockCache 和布隆过滤器;
- 过滤器支持谓词下推。
-
HBase和hive的区别
-
Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
-
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
-
-
HBase的基本架构
- HBase 的核心架构由五部分组成,分别是 HBase Client、HMaster、Region Server、ZooKeeper 以及 HDFS。参考
…
HBase篇
1.Hbase的架构,读写缓存?
HBase架构详解及读写流程
2.blockcache的底层实现?你提到了LRU那除了LRU还可以有什么方案?
blockcache的底层实现?
3.Hbase重启后怎么重构blockcache?(不会 只知道hlog和memstore)
4.Hbase写入方式 bulkload 不同写入方式的应用场景
HBase数据写入方式 与 BulkLoad
———————————————HIVE—————————————————————
Hive性能调优
1.小文件问题
- 后面写了
2.JVM重用
- Hive性能调优之JVM重用(5)
3.count(distinct col)问题
- 【Hive】count(distinct column) 为何效率低?
…
Hive面试重点
-
简述hive
-
简述hive读写文件机制
-
hive读取文件机制:
首先调用InputFormat(默认为TextInputFormat),返回一条条kv键值对记录(默认是一行对应一条键值对),然后调用SerDe(默认LazySimpleSerde)的Deserializer,将一行记录中的value根据分隔符切分成各个字段。
-
hive写文件机制:
将Row写入文件时,首先调用SerDe(默认LazySimpleSerde)的Serializer将对象转化为字节序列,然后调用OutputFormat将数据写HDFS文件系统中。
- hive和传统数据库之间的区别
…
1.如何理解Hive,为什么使用Hive
- Hive是Hadoop生态系统中比不可少的一个工具,它提供了一种SQL(结构化查询语言)方言,可以查询存储在Hadoop分布式文件系统(HDFS)中的数据或其他和Hadoop集成的文件系统,如MapR-FS、Amazon的S3和像HBase(Hadoop数据仓库)和Cassandra这样的数据库中的数据。
- 大多数数据仓库应用程序都是使用关系数据库进行实现的,并使用SQL作为查询语言。Hive降低了将这些应用程序转移到Hadoop系统上的难度。凡是会使用SQL语言的开发人员都可以很轻松的学习并使用Hive。如果没有Hive,那么这些用户就必须学习新的语言和工具,然后才能应用到生产环境中。另外,相比其他工具,Hive更便于开发人员将基于SQL的应用程序转移到Hadoop中。如果没有Hive,那么开发者将面临一个艰巨的挑战,如何将他们的SQL应用程序移植到Hadoop上。
- 参考-说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么
2.Hive的实现逻辑,为什么处理小表延迟比较高
- 因为其计算是通过MapReduce,MapReduce是批处理,高延迟的。小文件也要执行MapReduce。
- Hive的优势在于处理大数据,对于处理小数据没有优势。
———————————————Hadoop—————————————————————
第九部分 企业级调优手法
Hadoop
1.job执行三原则
Hadoop, Yarn, 资源调度, AH源码分析, 3.x 新特性概述, Job三原则, 调优(Shuffle, Job, YARN, NN Full GC), 二次开发环境搭建
2.shuffle调优
3.yarn调优
…
**Hadoop **
-
1.介绍一下Hadoop hadoop是什么
2.谷歌的三篇论文是否了解,三驾马车GFS,BigTable,MapReduce
3.hdfs源码你知道的话,讲讲元数据怎么管理的?
4.hdfs 你知道namenode的问题吗?怎么解决?应该就是联邦机制
5.hdfs写数据流程
6.namenode如果挂掉了怎么办 【HA配置】
7.说一下mapredeuce
8.哪个阶段最费时间,环形缓冲区的调优以及什么时候需要调
shuffle:排序和溢写磁盘 原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快】 -
9.环形缓冲区了不了解?说一下他的那个阈值高低的影响
10.写一个wordcount
11.WordCount在MapReduce中键值对变化
<偏移量, 一行数据> -> <单词1, 1> <单词2, 1> … -> <单词1,10> <单词2,15> -
12.map端为什么要排序?
13.map端输出的文件组织形式是什么样的?
14.reduce怎么知道从哪里下载map输出的文件
通过MRAPPMaster获取哪些节点有map输出,当map执行结束后,会汇报给MRAPPMaster。reduce中的一个线程会定期询问MRAPPMaster以便获取map输出的位置 -
15.如果map输出太多小文件怎么办
开启combiner合并,但是在求平均值的时候是不能使用的 -
16.MapReduce优化的case
输入端:合并小文件 combineinputformat map端:提高环形缓冲区的大小,减少IO次数 开启combiner
2、大数据计算(MapReduce,Spark、Flink)
MapReduce是Hive的底层原理,将所有计算抽象成 Map 和 Reduce 两个阶段,实现最早的分布式计算。
Spark提出了内存计算的概念,核心思想就是中间结果尽量不落盘,对MapReduce进行了千倍性能提升。
Flink & Storm,批计算的特点是输入数据集是事先知晓且有限的,而流计算的世界观认为输入数据集是无限的消息流,通过产生数据流的源头和消费数据流的管道来抽象流计算。Flink 最大的优势是它拥有内置的状态管理和精确一次送达语义的容错机制。
分布式计算—MapReduce、Spark、Storm、Flink分别适用什么场景
使用场景:
-
Spark 作为批计算的王者存在,基本处理所有分布式批处理的场景。有的时候会使用 Hadoop MapReduce 是因为存量业务没有明显的性能瓶颈,不需要故意开发迁移。另一种情况是在没有严格性能要求的情况下,减少 Spark 的部署运维成本,简单使用 HDFS 集群直接支持的 MapReduce 计算任务。还有一种情况是早年某些 MapReduce 作业的 DSL 的存量,传递依赖 MapReduce 且同样没有升级的强需求,例如 Pig 程序。 -
Flink 作为流计算的标杆,基本覆盖了阿里巴巴内部的流计算场景。但是,在阿里强推之前,或者从技术上说被双十一磨砺之前,大部分公司的伪实时需求可以通过 Spark Streaming 或者 Storm 乃至订阅 Kafka 加消费者任务来解决。因此市面上非 Flink 的流计算大抵是过时或者有局限性技术的存量。Flink 的核心优势在于内置状态管理以及先发优势带来的较为完善的功能支持,这方面解决了流计算开箱即用的问题,以及双十一磨砺的性能优势,目前仍然是流计算框架的跑分榜第一。 -
当然,这些项目都还有其他内容。例如 Hadoop 的 YARN 资源管理框架,Spark 跟高迭代的机器学习的整合等等。同时,外围还有数据湖技术和 HTAP 以及其他流计算框架在争夺这四款软件的业务场景,那就不是这里一两句话能说完的了。
———————————————MapReduce—————————————————————
第一部分 大数据开发
MapReduce面试重点
-
简述MapReduce整个流程
-
手写wordcount
-
join原理
…
面经1
MapReduce的原理
- map阶段:首先通过InputFormat把输入目录下的文件进行逻辑切片,默认大小等于block大小,并且每一个切片由一个maptask来处理,同时将切片中的数据解析成<key,value>的键值对,k表示偏移量,v表示一行内容;紧接着调用Mapper类中的map方法。将每一行内容进行处理,解析为<k,v>的键值对,在wordCount案例中,k表示单词,v表示数字1 ;
- shuffle阶段:map端shuffle:将map后的<k,v>写入环形缓冲区【默认100m】,一半写元数据信息(key的起始位置,value的起始位置,value的长度,partition号),一半写<k,v>数据,等到达80%的时候,就要进行spill溢写操作,溢写之前需要对key按照分区进行快速排序【分区算法默认是HashPartitioner,分区号是根据key的hashcode对reduce task个数取模得到的。这时候有一个优化方法可选,combiner合并,就是预聚合的操作,将有相同Key 的Value 合并起来, 减少溢写到磁盘的数据量,只能用来累加、最大值使用,不能在求平均值的时候使用】;然后溢写到文件中,并且进行merge归并排序(多个溢写文件);reduce端shuffle:reduce会拉取copy同一分区的各个maptask的结果到内存中,如果放不下,就会溢写到磁盘上;然后对内存和磁盘上的数据进行merge归并排序(这样就可以满足将key相同的数据聚在一起);【Merge有3种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下第一种形式不启用,第二种Merge方式一直在运行(spill阶段)直到结束,然后启用第三种磁盘到磁盘的Merge方式生成最终的文件。】
- reduce阶段:key相同的数据会调用一次reduce方法,每次调用产生一个键值对,最后将这些键值对写入到HDFS文件中。
见过数据倾斜吗?
-
是什么?
- 绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败(通过spark ui可以看见,特别明显)
-
为什么?
-
一个任务通常来说分为map操作和reduce操作(shuffle归在reduce中了),如图所示,这里举了一个wordcount案例,便于辅助理解
-
那么这两个部分就都有可能发生数据倾斜
map端:比如交由每个map task处理的文件大小不一致
reduce端:key值分布不均匀+shuffle(这两个条件缺一不可)
我们也应该进一步思考,key值为什么会分布不均匀数据可能会存在大量的空值业务存在热点数据
-
-
- 怎么办?
-
- 知道了为什么之后,对症下药就可以了
- map端:在任务之前,我们手动让每个数据文件大小一致如果过滤空值不会对业务产生影响,那么我们应该过滤空值
- reduce端:我们不好直接对key下手,显然就是对shuffle进行下手了
- 最好的手法:干掉shuffle
- 开启map端join
- 适用场景:大表join小表(虽然说小表的阈值可以自己设置,但是设置太大,那么就会占用过多的计算资源,显然是不合适的,通常最多设置在500m以下)
- 万能手法:
- 加盐为数据量特别大的key增加随机前缀或后缀,使得这些key分散到不同的task中;那么此时数据倾斜的key变了,如何join呢?于是可以将另外一份对应相同key的数据与随机前缀或者后缀作笛卡尔积,保证两个表可以join上(当然这是join的场景,对于group by计算也是一样的)
- 知道了为什么之后,对症下药就可以了
MapReduce详细流程:
1、准备待处理文件(200M)
2、submit()对原始文件进行切片分析(128M一块,这里0-128M为第一块,128-200位第二块)
3、提交信息
客户端会准备三样东西(Job的切片:Job.split,jar包:wc.jar,xml:Job.xml),对这个集群进行提交。
如果是本地模式,则没有jar包,正常生产模式下,都是用的YARN集群模式,所以jar包是一定有的。
4、计算出MapTask数量
客户端向YARN提交后,YARN会开启一个Mrappmaster(整个任务运行的老大),Mrappmaster会读取客户端对应的信息,最主要的就是读取切片信息(Job.split),Mrappmaster会根据切片个数,开启对应数量的MapTask,这里是两个切片,则对应开启两个MapTask。
5、MapTask工作
MapTask一启动后,就会开始工作,MapTask通过InputFormat来读取输入的文件,默认使用TextInputFormat,TextInputFormat源码里面有两个方法:1)RecorderReader(按行进行读取)和 2)isSplitable(判断这个文件是否可以切割),通过RecorderReader对文件数据按行进行读取,读完后,返回K(整个文件中的起始字节偏移量)和V(这行的内容)。
6、逻辑运算
数据读取完成后,将数据给到Mapper,Mapper里面是用户根据实际需求自己写的业务逻辑代码。数据处理完成后,通过outputCollector向环形缓冲器写入<k,v>数据。
7、向环形缓冲器写入<k,v>数据
环形缓存区默认大小为100M,左侧存索引,右侧存数据。当环形缓冲区数据写到80%时,进行反向写,将数据写入到磁盘。
这里可能会有一个小问题:为什么不存到100%才开始反向写?
主要是为了不影响Mapper处理完的数据写入环形缓冲区,如果写到100%环形缓冲区再反向写,就会导致Mapper处理后的数据无法再接着写入环形缓冲区,需要等环形缓冲区的数据反写到磁盘,才能继续写入环形缓冲区,影响处理进度,所以当环形缓冲区数据写到80%时,则开始进行反写,留下20%空间可以进行写入Mapper处理完的数据。
这里可能又有一个问题:如果当环形缓冲区数据到80%后反写,但是Mapper处理完的数据写入速度大于反写到磁盘的速度,导致环形缓冲区存储100%怎么办?
这个问题底层已经做过处理,如果Mapper处理完的数据写入速度大于反写到磁盘的速度,导致环形缓冲区存储100%,此时数据写入会暂定,直到有一定空间后,才会继续往环形缓冲区中写入数据,避免处理误差。
8、分区、排序
当数据写入到环形缓冲区时,也就是写入之前已经进行了分区,后续会根据分区,数据分别进入到对应的Reduce中独立进行处理。当数据溢写到磁盘时,会在溢写前进行排序,对数据索引进行排序,此时使用快排方式进行排序。
9、溢出文件到磁盘(分区且区内有序)
当环形缓冲区中数据达到80%时,数据就会溢写到磁盘上,溢写文件可以是多个。
10、Merge归并排序
通过归并排序对所有溢写文件根据分区进行排序,保证每一个分区内数据有序。归并排序后数据就会存储到磁盘上。
11、Combiner合并
这个环节是发生在归并排序前面,Combiner合并会将每个分区中k相同的数据进行预聚合,比如一个分区存在<a,1>和<a,1>两个数据,则会合并成<a,2>,提高传输效率。
12、启动ReduceTask
当所有的MapTask任务完成后,则启动相对应数量的ReduceTask,并告知ReduceTask处理数据范围(数据分区)。注意,并不一定是当所有的MapTask任务完成后才会开启ReduceTask,当我们MapTask数量比较多的时候,可以设置当完成多少个MapTask任务后就开启ReduceTask任务,处理完的数据再跟后面MapTask处理好的数据一起处理,提升处理效率。
13、下载数据到ReduceTask
ReduceTask主动从MapTask对应指定的分区拉取数据,再对来自不同分区的数据进行合并、归并排序。
14、分组(可选流程)
此时可根据实际情况,是否选择进行一次分组。
15、Reduce读取数据
Reduce方法中每次对一组数据(相同key)进行处理,数据处理完成后,则往外写数据。
16、往外写数据
通过OutputFormat往外写数据,OutPutFormat中包含RecordWriter方法,通过RecordWriter方法往外写数据,从而形成输出文件。其它的Reduce也是一样的流程。
上面的流程是整个MapReduce最全工作流程,Shuffle过程是从第7步开始到第16步结束,Shuffle大概过程如下:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
———————————————Spark—————————————————————
绝密100个Spark面试题,熟背100遍
【数据开发】pyspark入门与RDD编程
Spark面试重点
-
简述hadoop 和 spark 的不同点(为什么spark更快)
-
DAG有向无环图更精致的MR实现。
-
参考
-
-
谈谈你对RDD的理解
-
也可以看pyspark那章,转化(Transformation)操作和行动(Action)
-
参考
-
-
简述spark的shuffle过程
Shuffle 的本意是扑克的“洗牌,打乱次序”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发。
Spark Shuffle 分为两种:一种是基于Hash 的Shuffle;另一种是基于Sort 的Shuffle。
Spark的两种核心Shuffle详解
…
Spark
1.JVM调优
2.shuffle调优
3.数据倾斜
…
sparksql有几种join方式
- 包括 broadcast hash join,shuffle hash join,sort merge join,前两种都是基于hash join;broadcast 适合一张很小的表和一张大表进行join,shuffle适合一张较大的小表和一张大表进行join,sort适合两张较大的表进行join。
- 先说一下hash join吧,这个算法主要分为三步,首先确定哪张表是build table和哪张表是probe table,这个是由spark决定的,通常情况下,小表会作为build table,大表会作为probe table;然后构建hash table,遍历build table中的数据,对于每一条数据,根据join的字段进行hash,存放到hashtable中;最后遍历probe table中的数据,使用同样的hash函数,在hashtable中寻找join字段相同的数据,如果匹配成功就join到一起。这就是hash join的过程
- broadcast hash join分为broadcast阶段和hash join阶段,broadcast阶段就是 将小表广播到所有的executor上,hash join阶段就是在每个executor上执行hash join,小表构建为hash table,大表作为probe table
- shuffle hash join分为shuffle阶段和hash join阶段,shuffle阶段就是 对两张表分别按照join字段进行重分区,让相同key的数据进入同一个分区中;hash join阶段就是 对每个分区中的数据执行hash join
- sort merge join分为shuffle阶段,sort阶段和merge阶段,shuffle阶段就是 将两张表按照join字段进行重分区,让相同key的数据进入同一个分区中;sort阶段就是 对每个分区内的数据进行排序;merge阶段就是 对排好序的分区表进行join,分别遍历两张表,key相同就join输出,如果不同,左边小,就继续遍历左边的表,反之,遍历右边的表
Spark和MapReduce之间的区别?
-
可回答**:1)spark和maprecude的对比;2)mapreduce与spark优劣好处**
问过的一些公司:阿里云(2022.10),银联(2022.10),携程(2022.09),vivo(2022.09),滴滴(2022.09)(2020.09),网易云音乐(2022.09),快手(2022.08),字节(2022.08)x2(2022.05)(2020.09)(2020.06)(2019.11)x4,快手(2022.08),星环科技(2022.07),海康威视(2022.06),字节日常实习(2022.03),思科cisco(2021.11),腾讯PCG(2021.10),腾讯云(2021.10),阿里(2021.10),蔚来(2021.09),重庆富民银行(2021.09),网易杭研院(2021.09),网易严选(2021.08),小米(2021.08)(2020.09)(2019.09),华为精英计划(2021.07),触宝(2021.07),有道(2021.03),作业帮社招(2020.09),58(2020.09),一点资讯(2020.08),多益(2020.08),360实习(2020.04),阿里菜鸟(2020.04),腾讯互娱(2020.03),蘑菇街实习(2020.03)x2,阿里淘系(2019.11),美团大众点评(2019.10),微众银行(2019.09),网易有道(2019.08),招商银行信用卡中心(2019.04),光大银行(2019.03),头条(2018.11)
Spark和MapReduce之间的区别, 参考答案1、Spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的
MapReduce是将中间结果保存到磁盘中,减少了内存占用,牺牲了计算性能。
Spark是将计算的中间结果保存到内存中,可以反复利用,提高了处理数据的性能。2、Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数
Spark计算比MapReduce快的根本原因在于DAG计算模型。一般而言,DAG相比MapReduce在大多数情况下可以减少shuffle次数。Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。但是,如果计算过程中涉及数据交换,Spark也是会把shuffle的数据写磁盘的。3、Spark比MapReduce快
有一个误区,Spark是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop也是如此,只不过Spark支持将需要反复用到的数据Cache到内存中,减少数据加载耗时,所以Spark跑机器学习算法比较在行(需要对数据进行反复迭代)。4、Spark是粗粒度资源申请,而MapReduce是细粒度资源申请
粗粒度申请资源指的是在提交资源时,Spark会提前向资源管理器(YARN,Mess)将资源申请完毕,如果申请不到资源就等待,如果申请到就运行task任务,而不需要task再去申请资源。
MapReduce是细粒度申请资源,提交任务,task自己申请资源自己运行程序,自己释放资源,虽然资源能够充分利用,但是这样任务运行的很慢。5、MapReduce的Task的执行单元是进程,Spark的Task执行单元是线程
进程的创建销毁的开销较大,线程开销较小。6、Spark优缺点
优点:
1)Spark把中间数据放到内存中,迭代运算效率高。
Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
2)Spark 容错性高
Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
3)Spark更加通用
Spark提供的数据集操作类型分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。缺点:
1)内存问题JVM的内存overhead太大,1G的数据通常需要消耗5G的内存。
2)性能问题
由于大量数据抄被缓存在RAM中,Java回收垃圾缓慢的情况严重,导致Spark性能不稳定。7、MapReduce优缺点
优点:
1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行, 不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合 PB 级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。缺点:
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3)不擅长 DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘, 会造成大量的磁盘 IO,导致性能非常的低下。Spark篇1
1.Spark on yarn的流程,分部署模式答
5.讲讲Spark为什么比Hadoop快 。
6.RDD是什么,有什么特点。
7.RDD的血缘。
8.宽窄依赖。
13.Spark内存管理。
10.Transform和Action算子分别有什么常用的,他们的区别是什么。
11.Spark 能产生shuffle的算子。
17.Spark 数据倾斜。
18.用Spark遇到了哪些问题。
20.背压机制应用场景 底层实现。
Spark篇2
2.怎样提高并行度 相关参数 ?spark并行度设置及submit参数
3.client和cluster模式的区别 ?Spark Client和Cluster两种运行模式的工作流程区别
4.Spark shuffle以及为什么要丢弃hashshuffle ?Spark shuffle 过程 抛弃hashShuffle 基于新版本
9.stage划分? Spark Stage划分依据:Spark中的Stage调度算法
12.Spark里的reduce by key和group by key两个算子在实现上的区别并且说一下性能?
14.Spark数据落盘?
15.看过Spark底层源码没有?
16.Spark程序故障重启,checkpoint检查点? Checkpoint 检查点机制
19.Spark join的有几种实现? SparkSQL的3种Join实现
———————————————Flink—————————————————————
Flink面试重点题
-
简单介绍一下Flink
Flink面试八股文(上万字面试必备宝典)
Flink是一个面向流处理和批处理的分布式数据计算引擎,能够基于同一个Flink运行,可以提供流处理和批处理两种类型的功能。 在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流。
-
Flink和SparkStreaming区别 ,见下面
-
Flink的重启策略你了解吗
对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰一次处理语义。
Flink 则使用两阶段提交协议来解决这个问题。
…
Flink篇
1.Flink的组成
- Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
- Flink任务的组成由基本的“流”和“算子”构成,“流”中的数据在“算子”间进行计算和转换时,会被放入分布式的阻塞队列中。当消费者的阻塞队列满时,则会降低生产者的数据生产速度
2.Flink流批一体解释一下
- 当我们谈论批流一体,我们在谈论什么?
3.聊聊Sparkstreaming和Flink?为什么你觉得Flink比Sparkstreaming好?
- 干货 | Spark Streaming 和 Flink 详细对比
4.那Flink shuffle呢?你了解吗?
5.watermark用过吗 flink watermark机制
6.checkpoint Chandy-Lamport算法
7.如何用checkpoint和watermark防止读到乱序数据。
- Flink 解决乱序问题之WaterMarker
8.Kafka和Flink分别怎么实现exactly once,问的比较深入,我只回答了一些用法,二阶段提交说了流程,没说出来机制。
9.流式框架
1)节点挂了,怎么保证任务正常执行
2)有状态怎么维护之前的状态
3)checkpoint数据重用前提
3、大数据集群(Yarn、ZooKeeper、kafka)
———————————————Yarn—————————————————————
Yarn面试重点
简述yarn 集群的架构
-
Yarn集群架构和工作原理
-
Yarn(Yet Another Resource Negotiator,另一个资源协调器)是Hadoop生态系统中的一个重要组件,用于管理和协调分布式计算任务。它可以有效地利用集群中的资源,为用户提交的应用程序分配适当的计算资源。
-
Yarn的集群架构包含以下几个关键组件:
-
ResourceManager(RM):RM是集群上的主节点,负责整个集群资源的管理和调度。它接收来自客户端和ApplicationMaster(AM)的请求,并为每个应用程序分配容器资源。
-
NodeManager(NM):NM是集群上的工作节点,负责对本地资源进行管理和监控。它与RM通信以报告可用资源,并按照RM的指示启动、停止或移动容器。每个节点可以运行一个或多个NM。
-
ApplicationMaster(AM):AM是由提交到集群的应用程序创建的进程,负责协调应用程序的执行。它向RM注册并获取资源,然后与NM交互以启动任务。AM还负责监控任务的进度和容错。每个应用程序都有自己¥¥的AM。
-
Container:Container是Yarn中的资源单位,表示在集群节点上分配给应用程序的一组资源,包括CPU、内存和网络等。
yarn 的任务提交流程是怎样的
- Yarn的工作原理可以简要概括为以下几个步骤:
-
用户提交应用程序:用户将应用程序提交给RM。提交的应用程序包括代码和所需资源的描述,如应用程序类型、需要资源的数量和优先级等。
-
RM接受并分配资源:RM接收到应用程序的请求后,将根据可用资源和调度策略为该应用程序分配资源。它会考虑集群中每个节点的资源情况,以及其他正在运行的应用程序的资源需求。
-
应用程序获取资源:一旦RM分配了资源,应用程序的AM将与NM通信,并请求启动容器。NM会为应用程序分配一个或多个容器,每个容器都包含所需的资源。
-
容器中运行任务:一旦容器分配成功,应用程序的AM将向NM发送任务的代码和其他必要的信息。NM会根据指令来启动任务,并在容器中执行。
-
监测和调度:RM和NM会定期交换信息,以保持对集群资源使用情况的更新。RM会监控应用程序的进度,并可以根据需要重分配资源。
-
完成和释放资源:一旦应用程序的任务完成,AM会向RM注册其完成状态。之后,RM会释放已分配给该应用程序的资源,以便其他应用程序使用。
yarn的资源调度的三种模型
- FIFO调度器(FIFO Scheduler) Hadoop最初设计时的调度器,为单队列调度器,无法充分利用硬件资源。先进先出队列,先为第一个应用请求资源,第一个满足后再依次为队列下一个提供服务,不适合共享集群。
- 容器调度器(Capacity Scheduler) Capacity Schedulere是Yahoo!开发的多用户调度器,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
- 公平调度器(Fair Scheduler) Fair Scheduler是Facebook开发的多用户调度器,同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
- 总结YARN中的三种资源调度器(Resource manager中)
…
———————————————Zookeeper—————————————————————
Zookeeper面试重点
简述leader选举机制
- Zookeeper系列——一文带你了解Zookeeper的选举机制
简述什么是CAP理论,zookeeper满足CAP的哪两个
-
CAP理论(帽子理论)是指,在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)三者不可兼得,最多只能同时满足两个。
-
ZooKeeper 保证的是CP
(1)ZooKeeper 不能保证每次服务请求的可用性。(注:在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
(2)进行Leader 选举时集群都是不可用。
zookeeper集群的节点数为什么建议奇数台
-
zookeeper集群部署节点为奇数的原因(最少3个)
-
zookeeper集群节点数推荐为奇数(2n+1)个,因为如果为偶数个节点,当有一半节点发生故障时,由于没有足够的节点数来选举新的leader节点(要求半数以上节点选举,不包含半数),会导致整个集群无法工作。如果只能部署两个节点,则不如使用单节点,因为两个节点的集群,只要任意一个节点发生故障,则集群无法工作。
-
最少3个的原因:
集群规则为:2N + 1 台,N > 0,即最少需要 3 台。
因为 ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。
只有在 ZK 节点挂的太多,只剩一半或不到一半节点能工作,集群才失效。
如:
3 个节点的 cluster 可以挂掉一个节点(leader 可以得到 2 票 > 1.5)
2 个节点的 cluster 就不能挂掉任何一个节点了(leader 可以得到 1 票 <= 1)
…
Zookeeper, 引用
-
1.zookeeper简单介绍一下,为什么要用zk?zk的架构?
-
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目(文件系统+通知机制)
zk的应用场景:
- 统一命名服务:在分布式环境下,经常需要对服务进行统一命名,便于识别,例如ip地址
- 统一配置管理:在一个集群中,要求所有节点的配置信息是一致的
- 统一集群管理:在一个集群中,需要实时监控每个节点的状态变化
- 负载均衡:在zookeeper中记录每台服务器的访问数,再次请求的时候,让访问最少的服务器去处理当前请求
-
-
2.zk的数据存储,当重启后怎么重构zk的数据模型
-
zk中的数据是保存在节点上的,节点就是znode,多个znode之间构成一棵树的目录结构
zk的数据是运行在内存中,zk提供了两种持久化机制:
- 事务日志:zk把执行的命令以日志形式保存在dataLogDir指定的路径中的文件中(如果没有指定dataLogDir,则按照 dataDir指定的路径)。
- 数据快照:zk会在一定的时间间隔内做一次内存数据快照,把时刻的内存数据保存在快照文件中。
-
-
3.zk的原理,基于什么协议,follower和observer的区别,zk怎么扩容
-
zookeeper基于zab协议
zab和raft主要有四点区别:
一致性模型:ZAB协议和Raft协议都采用Leader-Follower模型,但ZAB协议只能保证强一致性,而Raft协议可以根据需要保证强一致性或弱一致性。
选主过程:ZAB协议的选主过程中只有当前Leader节点参与,而Raft协议的选主过程中所有节点都参与,更容易实现节点间的负载均衡。
日志复制机制:ZAB协议将每个节点的事务日志存储在Leader节点中,然后通过Leader节点进行复制,而Raft协议将每个节点的日志直接复制到其他节点,降低了中心化的压力。
可扩展性:ZAB协议的可扩展性受限于Leader节点的性能,而Raft协议可以通过水平扩展来增加整个系统的容量和性能。
-
-
4.zab和raft的区别 引申到paxos和raft
-
5.zk机房扩容有什么要注意的吗?(我只知道过半所以奇数个,其他的不知道
- zookeeper集群的数量应为奇数:因为根据paxos理论,只有集群中超过半数的节点还存活才能保证集群的一致性。
-
6.cap原则
———————————————Kafka—————————————————————
Kafka面试重点
为什么要使用kafka
- 缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
- 解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
- 冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
- 健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
- 异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
简述kafka的架构
- Kafka 的基础架构是围绕几个关键术语组织的:topics(主题), producers(生产者), consumers(消费者), 和brokers(代理)。 所有的Kafka 消息都按照主题进行组织。 如果你想发送一条消息,你就把它发送到一个特定的主题,如果你想读取一条消息,你得从特定的主题中进行读取。
Kafka与其他消息队列对比
- RabbitMQ与Kafka一样都是开源消息队列,但它更注重消息的处理,支持多种消息协议,如AMQP、STOMP等,具有广泛的可靠性和灵活性;而Kafka更注重数据的处理,支持流式数据处理,适合大数据处理、日志收集等应用。
Kafka在大多数情况下满足了CA理论,即一致性和可用性。
- 一致性(Consistency):在Kafka中,任何一台机器写入的数据,其他节点也可以读取到。
- 可用性(Availability):如果一个节点故障,其他节点可以正常提供数据服务。
Kafka在项目中起到的作用,如果挂掉怎么保证数据不丢失,不使用Kafka会怎样
Kafka呢 怎么保证数据一致性 引申到exactly once
参考
Kafka通过哪些机制实现了高吞吐量?
- 综上所述,Kafka 的高吞吐量得益于其分布式架构、零拷贝机制、批量处理、高效的磁盘存储、基于文件的存储结构和数据压缩等优化措施。 这些设计和技术手段共同作用,使得Kafka 能够处理大规模的消息流并提供高吞吐量的性能表现
4、Java与408(CN+OS+DS,DB)
JAVA基础、JAVA集合、并发编程、JVM、IO
Java补充一些,408详见2023秋招后端部分
———————————————408—————————————————————
第三部分 计算机基础
计算机网络
-
OSI七层模型
-
TCP连接管理
-
TCP连接建立为什么需要三次握手
…
操作系统
-
什么是操作系统
-
什么是系统调用
-
进程和线程的区别
…
数据库
-
索引是什么
-
mysql中索引的分类有哪些
-
B+树和B树的区别
…
数据结构
-
链表和数组的区别
-
静态链表和动态链表的区别
-
栈和队列的区别
…
———————————————JAVA基础—————————————————————
JAVAGUIDE,, 部分厂面试风格 ,技术方案-美团, 技术方案-B站
第二部分 Java开发
java基础
-
JDK、JRE、JVM三者区别和联系
-
基本数据类型和引用数据类型的区别
-
8种基本数据类型、字节大小
…
java基础篇
1.java限定词(private那些)
2.ArrayList原理,为什么初始是10,为什么扩容1.5倍
3.hashmap的实现原理
4.怎么解决hash碰撞+ 时间复杂度+优化+改成红黑树了时间复杂度+继续优化
5.实现单例模式
6.多路复用,NIO这些了解过吗?
7.100M的数组 随机查快还是顺序查快 解释为什么?
• 基础概念与常识
• • Java 语言有哪些特点?
• Java SE vs Java EE
• JVM vs JDK vs JRE
• 什么是字节码?采用字节码的好处是什么?
• 为什么说 Java 语言“编译与解释并存”?
• AOT 有什么优点?为什么不全部使用 AOT 呢?
• Oracle JDK vs OpenJDK
• Java 和 C++ 的区别?
• 基本语法
• • 注释有哪几种形式?
• 标识符和关键字的区别是什么?
• Java 语言关键字有哪些?
• 自增自减运算符
• 移位运算符
• continue、break 和 return 的区别是什么?
• 基本数据类型
• • Java 中的几种基本数据类型了解么?
• 基本类型和包装类型的区别?
• 包装类型的缓存机制了解么?
• 自动装箱与拆箱了解吗?原理是什么?
• 为什么浮点数运算的时候会有精度丢失的风险?
• 如何解决浮点数运算的精度丢失问题?
• 超过 long 整型的数据应该如何表示?
• 变量
• • 成员变量与局部变量的区别?
• 静态变量有什么作用?
• 字符型常量和字符串常量的区别?
• 方法
• • 什么是方法的返回值?方法有哪几种类型?
• 静态方法为什么不能调用非静态成员?
• 静态方法和实例方法有何不同?
• 重载和重写有什么区别?
• 什么是可变长参数?
• 参考
• 面向对象基础
• • 面向对象和面向过程的区别
• 创建一个对象用什么运算符?对象实体与对象引用有何不同?
• 对象的相等和引用相等的区别
• 如果一个类没有声明构造方法,该程序能正确执行吗?
• 构造方法有哪些特点?是否可被 override?
• 面向对象三大特征
• 接口和抽象类有什么共同点和区别?
• 深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
• Object
• • Object 类的常见方法有哪些?
• == 和 equals() 的区别
• hashCode() 有什么用?
• 为什么要有 hashCode?
• 为什么重写 equals() 时必须重写 hashCode() 方法?
• String
• • String、StringBuffer、StringBuilder 的区别?
• String 为什么是不可变的?
• 字符串拼接用“+” 还是 StringBuilder?
• String#equals() 和 Object#equals() 有何区别?
• 字符串常量池的作用了解吗?
• String s1 = new String(“abc”);这句话创建了几个字符串对象?
• String#intern 方法有什么作用?
• String 类型的变量和常量做“+”运算时发生了什么?
• 参考
• 异常
• • Exception 和 Error 有什么区别?
• Checked Exception 和 Unchecked Exception 有什么区别?
• Throwable 类常用方法有哪些?
• try-catch-finally 如何使用?
• finally 中的代码一定会执行吗?
• 如何使用 try-with-resources 代替try-catch-finally?
• 异常使用有哪些需要注意的地方?
• 泛型
• • 什么是泛型?有什么作用?
• 泛型的使用方式有哪几种?
• 项目中哪里用到了泛型?
• 反射
• • 何谓反射?
• 反射的优缺点?
• 反射的应用场景?
• 注解
• • 何谓注解?
• 注解的解析方法有哪几种?
• SPI
• • 何谓 SPI?
• SPI 和 API 有什么区别?
• SPI 的优缺点?
• 序列化和反序列化
• • 什么是序列化?什么是反序列化?
• 如果有些字段不想进行序列化怎么办?
• 常见序列化协议有哪些?
• 为什么不推荐使用 JDK 自带的序列化?
• I/O
• • Java IO 流了解吗?
• I/O 流为什么要分为字节流和字符流呢?
• Java IO 中的设计模式有哪些?
• BIO、NIO 和 AIO 的区别?
• 语法糖
• • 什么是语法糖?
• Java 中有哪些常见的语法糖
• Java 值传递详解
• Java 序列化详解
• 什么是序列化和反序列化?
• 常见序列化协议有哪些?
o JDK 自带的序列化方式
o Kryo
o Protobuf
o ProtoStuff
o Hessian
o 总结
• 泛型&通配符详解
• Java 反射机制详解
• Java 代理模式详解
• BigDecimal 详解
• Java 魔法类 Unsafe 详解
• Java SPI 机制详解
• Java 语法糖详解
• 集合概述
• • Java 集合概览
• 说说 List, Set, Queue, Map 四者的区别?
• 集合框架底层数据结构总结
• 如何选用集合?
• 为什么要使用集合?
• List
• • ArrayList 和 Array(数组)的区别?
• ArrayList 和 Vector 的区别?(了解即可)
• Vector 和 Stack 的区别?(了解即可)
• ArrayList 可以添加 null 值吗?
• ArrayList 插入和删除元素的时间复杂度?
• LinkedList 插入和删除元素的时间复杂度?
• LinkedList 为什么不能实现 RandomAccess 接口?
• ArrayList 与 LinkedList 区别?
• 说一说 ArrayList 的扩容机制吧
• Set
• • Comparable 和 Comparator 的区别
• 无序性和不可重复性的含义是什么
• 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
• Queue
• • Queue 与 Deque 的区别
• ArrayDeque 与 LinkedList 的区别
• 说一说 PriorityQueue
• 什么是 BlockingQueue?
• BlockingQueue 的实现类有哪些?
• ArrayBlockingQueue 和 Lin
• Map(重要)
• • HashMap 和 Hashtable 的区别
• HashMap 和 HashSet 区别
• HashMap 和 TreeMap 区别
• HashSet 如何检查重复?
• HashMap 的底层实现
• HashMap 的长度为什么是 2 的幂次方
• HashMap 多线程操作导致死循环问题
• HashMap 为什么线程不安全?
• HashMap 常见的遍历方式?
• ConcurrentHashMap 和 Hashtable 的区别
• ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
• JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
• ConcurrentHashMap 为什么 key 和 value 不能为 null?
• ConcurrentHashMap 能保证复合操作的原子性吗?
• Collections 工具类(不重要)
• • 排序操作
• 查找,替换操作
• 同步控制
• 集合判空
• 集合转 Map
• 集合遍历
• 集合去重
• 集合转数组
• 数组转集合
• ArrayList 源码分析
• LinkedList 源码分析
• HashMap 源码分析
• ConcurrentHashMap 源码分析
• LinkedHashMap 源码分析
• CopyOnWriteArrayList 源码分析
• ArrayBlockingQueue 源码分析
• PriorityQueue 源码分析
• DelayQueue 源码分析
什么是序列化?
- 序列化:将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
什么是字节码?采用字节码的好处是什么?
- 在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。
- 所以, Java 程序运行时相对来说还是高效的(不过,和 C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java SE vs Java EE
- Java SE(Java Platform,Standard Edition): Java 平台标准版,Java 编程语言的基础,它包含了支持 Java 应用程序开发和运行的核心类库以及虚拟机等核心组件。Java SE 可以用于构建桌面应用程序或简单的服务器应用程序。
- Java EE(Java Platform, Enterprise Edition ):Java 平台企业版,建立在 Java SE 的基础上,包含了支持企业级应用程序开发和部署的标准和规范(比如 Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS)。 Java EE 可以用于构建分布式、可移植、健壮、可伸缩和安全的服务端 Java 应用程序,例如 Web 应用程序。
JDK 和 JRE
-
JDK(Java Development Kit),它是功能齐全的 Java SDK,是提供给开发者使用,能够创建和编译 Java 程序的开发套件。它包含了 JRE,同时还包含了编译 java 源码的编译器 javac 以及一些其他工具比如 javadoc(文档注释工具)、jdb(调试器)、jconsole(基于 JMX 的可视化监控⼯具)、javap(反编译工具)等等。
-
JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,主要包括 Java 虚拟机(JVM)、Java 基础类库(Class Library)。
-
也就是说,JRE 是 Java 运行时环境,仅包含 Java 应用程序的运行时环境和必要的类库。而 JDK 则包含了 JRE,同时还包括了 javac、javadoc、jdb、jconsole、javap 等工具,可以用于 Java 应用程序的开发和调试。如果需要进行 Java 编程工作,比如编写和编译 Java 程序、使用 Java API 文档等,就需要安装 JDK。而对于某些需要使用 Java 特性的应用程序,如 JSP 转换为 Java Servlet、使用反射等,也需要 JDK 来编译和运行 Java 代码。因此,即使不打算进行 Java 应用程序的开发工作,也有可能需要安装 JDK。
———————————————JVM与IO—————————————————————
1、
• Java内存区域详解(重点)
• 前言
• 运行时数据区域
o 程序计数器
o Java 虚拟机栈
o 本地方法栈
o 堆
o 方法区
o 运行时常量池
o 字符串常量池
o 直接内存
• HotSpot 虚拟机对象探秘
o 对象的创建
o 对象的内存布局
o 对象的访问定位
• 参考
2、
• JVM垃圾回收详解(重点)
• 前言
• 堆空间的基本结构
• 内存分配和回收原则
• • 对象优先在 Eden 区分配
• 大对象直接进入老年代
• 长期存活的对象将进入老年代
• 主要进行 gc 的区域
• 空间分配担保
• 死亡对象判断方法
• • 引用计数法
• 可达性分析算法
• 引用类型总结
• 如何判断一个常量是废弃常量?
• 如何判断一个类是无用的类?
• 垃圾收集算法
• • 标记-清除算法
• 复制算法
• 标记-整理算法
• 分代收集算法
• 垃圾收集器
• • Serial 收集器
• ParNew 收集器
• Parallel Scavenge 收集器
• Serial Old 收集器
• Parallel Old 收集器
• CMS 收集器
• G1 收集器
• ZGC 收集器
3、
• 类文件结构详解
• 回顾一下字节码
• Class 文件结构总结
• • 魔数(Magic Number)
• Class 文件版本号(Minor&Major Version)
• 常量池(Constant Pool)
• 访问标志(Access Flags)
• 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
• 字段表集合(Fields)
• 方法表集合(Methods)
• 属性表集合(Attributes)
4、
• 类加载过程详解
• 类加载器详解(重点)
• 最重要的JVM参数总结
• JDK监控和故障处理工具总结
• JVM线上问题排查和性能调优案例
• 1.概述
• 2.堆内存相关
• • 2.1.显式指定堆内存–Xms和-Xmx
• 2.2.显式新生代内存(Young Generation)
• 2.3.显式指定永久代/元空间的大小
• 3.垃圾收集相关
• • 3.1.垃圾回收器
• 3.2.GC 日志记录
• 4.处理 OOM
• 5.其他
• 文章推荐
JDK 命令行工具
• • jps:查看所有 Java 进程
• jstat: 监视虚拟机各种运行状态信息
• jinfo: 实时地查看和调整虚拟机各项参数
• jmap:生成堆转储快照
• jhat: 分析 heapdump 文件
• jstack :生成虚拟机当前时刻的线程快照
• JDK 可视化分析工具
• • JConsole:Java 监视与管理控制台
• Visual VM:多合一故障处理工具
5、
• IO 流简介
• 字节流
• • InputStream(字节输入流)
• OutputStream(字节输出流)
• 字符流
• • Reader(字符输入流)
• Writer(字符输出流)
• 字节缓冲流
• • BufferedInputStream(字节缓冲输入流)
• BufferedOutputStream(字节缓冲输出流)
• 字符缓冲流
• 打印流
• 随机访问流
• 装饰器模式
• 适配器模式
• 工厂模式
• 观察者模式
• 前言
• I/O
• • 何为 I/O?
• 有哪些常见的 IO 模型?
• Java 中 3 种常见 IO 模型
• • BIO (Blocking I/O)
• NIO (Non-blocking/New I/O)
• AIO (Asynchronous I/O)
NIO 简介
NIO 核心组件
Buffer(缓冲区)
Channel(通道)
Selector(选择器)
NIO 零拷贝
JVM
-
java运行时一个类是什么时候加载的
-
JVM一个类的加载过程
-
继承时父子类的初始化顺序是怎样的
…
Java 虚拟机(JVM)
- 运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
- JVM 并不是只有一种!只要满足 JVM 规范,每个公司、组织或者个人都可以开发自己的专属 JVM。 也就是说我们平时接触到的 HotSpot VM 仅仅是是 JVM 规范的一种实现而已。
———————————————并发编程—————————————————————
1、
• 什么是线程和进程?
• • 何为进程?
• 何为线程?
• Java 线程和操作系统的线程有啥区别?
• 请简要描述线程与进程的关系,区别及优缺点?
• • 图解进程和线程的关系
• 程序计数器为什么是私有的?
• 虚拟机栈和本地方法栈为什么是私有的?
• 一句话简单了解堆和方法区
• 并发与并行的区别
• 同步和异步的区别
• 为什么要使用多线程?
• 使用多线程可能带来什么问题?
• 如何理解线程安全和不安全?
• 单核 CPU 上运行多个线程效率一定会高吗?
• 如何创建线程?
• 说说线程的生命周期和状态?
• 什么是线程上下文切换?
• 什么是线程死锁?如何避免死锁?
• • 认识线程死锁
• 如何预防和避免线程死锁?
• sleep() 方法和 wait() 方法对比
• 为什么 wait() 方法不定义在 Thread 中?
• 可以直接调用 Thread 类的 run
2、
• JMM(Java 内存模型)
• volatile 关键字
• • 如何保证变量的可见性?
• 如何禁止指令重排序?
• volatile 可以保证原子性么?
• 乐观锁和悲观锁
• • 什么是悲观锁?
• 什么是乐观锁?
• 如何实现乐观锁?
• CAS 算法存在哪些问题?
• synchronized 关键字
• • synchronized 是什么?有什么用?
• 如何使用 synchronized?
• 构造方法可以用 synchronized 修饰么?
• synchronized 底层原理了解吗?
• JDK1.6 之后的 synchronized 底层做了哪些优化?锁升级原理了解吗?
• synchronized 和 volatile 有什么区别?
• ReentrantLock
• • ReentrantLock 是什么?
• 公平锁和非公平锁有什么区别?
• synchronized 和 ReentrantLock 有什么区别?
• 可中断锁和不可中断锁有什么区别?
• ReentrantReadWriteLock
• • ReentrantReadWriteLock 是什么?
• ReentrantReadWriteLock 适合什么场景?
• 共享锁和独占锁有什么区别?
• 线程持有读锁还能获取写锁吗?
• 读锁为什么不能升级为写锁?
• StampedLock
• • StampedLock 是什么?
• StampedLock 的性能为什么更好?
• StampedLock 适合什么场景?
• StampedLock 的底层原理了解吗?
• Atomic 原子类
3、
• ThreadLocal
• • ThreadLocal 有什么用?
• 如何使用 ThreadLocal?
• ThreadLocal 原理了解吗?
• ThreadLocal 内存泄露问题是怎么导致的?
• 线程池
• • 什么是线程池?
• 为什么要用线程池?
• 如何创建线程池?
• 为什么不推荐使用内置线程池?
• 线程池常见参数有哪些?如何解释?
• 线程池的饱和策略有哪些?
• 线程池常用的阻塞队列有哪些?
• 线程池处理任务的流程了解吗?
• 如何给线程池命名?
• 如何设定线程池的大小?
• 如何动态修改线程池的参数?
• 如何设计一个能够根据任务的优先级来执行的线程池?
• Future
• • Future 类有什么用?
• Callable 和 Future 有什么关系?
• CompletableFuture 类有什么用?
• AQS
• • AQS 是什么?
• AQS 的原理是什么?
• Semaphore 有什么用?
• Semaphore 的原理是什么?
• CountDownLatch 有什么用?
• CountDownLatch 的原理是什么?
• 用过 CountDownLatch 么?什么场景下用的?
• CyclicBarrier 有什么用?
• CyclicBarrier 的原理是什么?
• 虚拟线程
重点:
• 乐观锁和悲观锁详解
• JMM(Java 内存模型)详解
• Java 线程池详解
• Java 线程池最佳实践
• Java 常见并发容器总结
• AQS 详解
• Atomic 原子类总结
• ThreadLocal 详解
• CompletableFuture 详解
• 虚拟线程极简入门
并发编程
-
java实现多线程有几种方式
-
线程池相关内容
-
线程有哪几种状态
并发编程篇
1.如何实现多线程 写过多线程吗
2.4种线程池功能
3.java内存模型
4.java内存模型中,线程和进程会如何分配这些资源
5.volatile的作用
6.synchronized和volited的区别
7.synchronized与lock的区别
8.公平锁与非公锁的区别
9.java锁都有什么,JUC包
10.lock是公平的还是非公平的(答案是可以根据逻辑去自己实现是否公平)
11.怎么保证线程同步?
12.sychornized讲一下 和其他的区别
13.sychornized怎么优化
14.volatile可以保证原子性吗?
15.cas呢?我讲了cas的原理 结果怼我 我不是问你原理 我是问你怎么保证原子性的?
16.reentrantlock底层原理
17.除了reentrantlock,你还知道什么锁
18.读写锁底层实现原理和应用场合
19.synchronize底层实现 锁升级 公平?
20.多线程(线程间的通信,锁,volatile,CAS)
5、数仓与SQL(工作 & 项目实践)
———————————————数仓基础—————————————————————
第四部分 数仓基础
1.数据仓库是什么
2.数据仓库和数据库有什么区别
3.为什么要对数据仓库分层
…
第十部分 数据湖基础
1.你觉得数据仓库有哪些优点和缺点
2.数据湖是什么
3.聊聊数据湖和数仓之间的区别
…
数据仓库数据湖对比
那么我们来看一下数据仓库的问题:
- 我们只能增加字段,很难去下线一个字段,真的要下线某一个字段,风险非常高
- 数据更新的底层是把整个表的数据重新生成一遍,再覆盖掉历史数据,成本非常高
- 增删改没有事务性保障,而在传统的数据库中有成熟的一致性解决方案
- 索引功能是有限的,一般很少建立索引,3.0版本已经没有索引了
- 无法满足算法人员对数据的所有诉求,比如在机器学习场景中,需要一些文本、语音、视频等非结构化数据
- 流批一体开发周期长,当下最流行的流批一体开发模式是基于lambda架构的,这种模式需要同时进行离线和实时的单独开发。
数据湖的提出正好解决了上述大部分问题,数据湖主要有以下特性
- 能够存储海量的原始数据
- 能够支持任意数据格式的数据
- 有较好的分析和处理能力
目前数据湖的相关产品主要有 Delta Lake、Apache Iceberg和Apache Hudi
———————————————SQL与数据开发—————————————————————
第五部分 常考SQL
1.连续问题
2.分组问题
3.间隔连续问题
SQL笔试题(1):求连续时间问题
…
第六部分 场景题
…
第八部分 大厂SQL真题
短视频业务
用户增长业务
电商业务
打车业务
教育业务
内容业务
数据开发防踩坑指南
+ 如何找到我想要使用的数据表?
数仓主题视图中找到相关计算任务,并得到对应计算结果表
数据字典按关键字搜索相关的主干表
找到当前主题负责人当面对齐使用场景,由对方提供使用建议+ 上下游依赖阻断如何设置?
某些场景下如果上游数据质量出现问题我们不希望下游继续执行可以参考以下步骤操作。注意:该功能在上游数据异常时会导致下游任务全部阻塞,谨慎使用
搜索依赖关系并添加,为下游任务添加依赖+ 平台中is null筛选不出为NULL的数据
"\\N","NaN","", NULL 会统一显示为NULL,需要用
test <> "\\N" and test <> "NaN" and test <> "" and test is not null进行筛选+ double类型计算错误
首先检查字段类型是否为double,如果是string可以先用double1()进行类型转换。
然后注意null值,null值会导致sum()计算出错,要是用nvl(number, 0.0)进行替换,否则加和不正确+ string类型计算错误
bigint类型不能用 (a= "")进行判定,如果判定是null要用is null,或者使用string1()进行数据格式转换+ 不等于无法筛选出Null值
count(distinct ) as total 写法不会统计null值
例:
principal_name
a
null
null
count(distinct principal_name) 为1,并不会计算null作为一个记录+ 大表关联耗时长如何优化
采用map join优化性能,具体写法如下
原理可参考csdn.net/qq_35744460/article/details/89401536+ 存量+增量表获取全量数据场景
方式一:每个全量表用存量表和所有的全量表。禁止使用
该方式随着时间的推移,增量分区数大量增多(导致扫描大量小文件)、增量表总行数增多会严重拖慢计算效率、且增量表分区无限膨胀会超出限制
方式二:通过自依赖方式,通过全量表和增量表生成下一分区增量表。选用该方案
SELECT${YYYYMMDD} AS ds,{ 字 段 列 表 }
FROM(SELECT{ 字 段 列 表 },ROW_NUMBER() OVER (PARTITION BY { 去 重 字 段 列 表 }ORDER BY{ 排 序 字 段 } DESC) AS rnFROM(SELECT{ 字 段 列 表 }FROM{ 全 量 表 }WHEREds = date_sub(${YYYYMMDD},1)UNION ALL-- 每日增量SELECT{ 字 段 列 表 }FROM{ 增 量 表 }WHEREdb_date >= ${YYYYMMDD}00AND db_date <= ${YYYYMMDD}23AND ctrl_ctrlinfo NOT IN (';0-BEGIN',';0-END',';0-FILL')UNION ALL-- 存量SELECT{ 字 段 列 表 }FROM{ 存 量 表 }WHERE${YYYYMMDD} <= { 首 次 执 行 的 日 期 } -- 建议用任务第一次执行时间往后延迟1个周期AND ctrl_ctrlinfo NOT IN (';0-BEGIN',';0-END',';0-FILL')UNION ALL-- 历史增量SELECT{ 字 段 列 表 }FROM{ 增 量 表 }WHERE${YYYYMMDD} <= { 首 次 执 行 的 日 期 }AND db_date < ${YYYYMMDD}00AND ctrl_ctrlinfo NOT IN (';0-BEGIN',';0-END',';0-FILL')))
WHERErn = 1+ 注意过滤条件放在where和放在on中的区别
where是在join出笛卡尔积后进行过滤,而on是在进行笛卡尔积前过滤
特别的,如果left join时,on中针对左表的筛选都是不生效的+ 注意规避DM层间的循环依赖
以往的团队认知中认为DM层应该尽可能多扩充信息,因此在跨主题关联(DM层)构造时倾向于使用对方的DM层,这样非常容易造成循环依赖如下数仓迭代场景。
因此在数仓设计时,我们应该尽量减少DM层间的互相依赖,DM层尽量是依赖DW层并不要过多扩充信息。+ 注意设置父子任务间合理的依赖关系
无论是数据入库、计算还是应用,任务之间势必存在依赖关系;合理的依赖关系能够帮助我们及时正确的走完数据链路的全流程,建议按照如下策略编写计算任务并配置依赖关系。
0依赖场景 父子任务样例 任务依赖方式 sql脚本写法 解释说明
1父子任务周期一致 天->天 依赖同周期 partition (p_${YYYYMMDD})
2父任务周期大于子任务 天->小时 依赖前一个周期实例 partition (p_${YYYYMMDD-1}) 小时任务传入的日期为当天,此时父任务只生成了前一天的分区数据因此需要YYYYMMDD-1
3父任务周期小于子任务 小时->天 依赖最后一个周期实例 partition (p_${YYYYMMDD}23) 天任务传入的日期为前一天,此时父任务的小时表已产生了当天小时分区的数据。为了保证数据时区一致,采用前一天23点的数据最为合适+ 报表接入数据源的方式
如果要使用最新分区的数据,不要直接使用数据库作为数据源并保留一个分区的方式,因为如果老的分区被删除,新的分区还未插入数据的时候,会存在一小段时间没数据的情况
应该使用SQL建表的方式接入数据,先查出最新分区,再查询数据+ 【列转行】explode函数的使用在Hive和Thive上有所区别
作用
explode函数接收一个array作为参数,用于将一列转换为多行数据
例如:
转换前
1 A;B;C;D
转换后
1. A
2. B
3. C
4. D
explode函数单独使用只能对拆分字段进行访问,即select的时候只能出现explode作用的字段,不能在表中选择其他的字段,否则会报错。
但是实际需求中经常需要拆某个字段,然后和其他字段一起读出来,这时候就要用到lateral view侧视图一起使用
lateral view会将explode生成的结果放到一个虚拟表里头,然后这个虚拟表会和输入行进行join来达到连接UDTF外的select字段的目的。
易错点
在网上直接搜索explode函数的用法,给的是Hive版本,用Hive版本写完SQL之后在idex里头是可以执行的(原因是idex中有supersql的优化,支持Hive的语法)。但是在Xdata任务中校验SQL会报错,报错,报错提示也不清晰,排查会花比较长时间。
-- 适配所有情况的版本
selectserver,client_name
fromxxx::t_ods_xxx_hour PARTITION (p_2023041310)t_serverLATERAL VIEW explode(split(clients,';')) t_server AS client_name
-- Hive版本
selectserver,client_name
fromxxx::t_ods_xxxx_hour PARTITION (p_2023041310) xxxlateral view explode (split (clients,';')) as client_name+ 【行转列】
SELECTprincipal,dimension,sum(IF (type = 'change成功', cnt, 0)) AS change_success_cnt,sum(IF (type = 'change失败', cnt, 0)) AS change_failure_cnt,sum( IF (type IN ('change失败', 'change成功'), cnt, 0)) AS change_cnt,
FROMXXXX+ 使用<>或者!=判断字符串类型可能不符合预期
原理:
使用<>或者!=的时候,命中隐式类型转换,左边是string右边是bigint会都转换为double,人名会被转换为NULL,做!=的筛选时,NULL值不会命中
使用not in的时候,也命中隐式类型转换,左边是string右边是bigint会都转换为string来做比较,于是符合预期
写SQL筛选条件之前要先判断左右两边类型是否一致
实现!=的筛选条件的时候,尽量使用Not in替代,避免类似踩坑+ 注意json.dumps的编码问题
Python 3中的json在做dumps操作时,会将中文转换成unicode编码,并以16进制方式存储,这会导致中文被json.dumps以后,写入数仓后变样。
处理方式是使用json.dumps(dict_param, ensure_ascii=False),手动取消unicode编码+ PySpark任务卡住
大概率是内存不足、full gc过多,且此时spark会将数据溢写到磁盘,导致运行十分缓慢,可以看情况调高driver、executor内存大小+ 数组类JSON解析选用原生hivesql函数
select hive_get_json_object('xxx')+ pyspark任务写入数据时将字符串自动转为NULL
扩展参数里添加 spark.tdw.orc.ignore.empty.str=false 避免NULL和空字符串互转。部分SQL语法:
1、分区
xxx::t_dwd_xxx_hour partition ( p_${YYYYMMDDHH} ) item_detail2、统计
CASEWHEN xxx.status = '9' THEN 1 ELSE 0
END AS is_ignore,
SUM(xxx.is_ignore) AS ignore_cnt
sum(case when xxx then 1 else 0 end) as xxx
COUNT(DISTINCT xxx.id) AS id_cnt
if(xxx in ('1', '2'), 0, 1) as xxx,3、类型
CAST(xxx AS String) as xxx
TO_DATE(xxx.date, "yyyy-mm-dd")
TO_DATE(CONCAT('',${YYYYMMDD-7}),"yyyymmdd")更多sql题目
有一张tmp表,字段分别是 开始时间start_date,结束时间end_date,欠费金额amount
2015-03-02 2015-03-05 10
2015-03-04 2015-03-06 20
输出描述:用户每天需要还的金额
2015-03-02 10
2015-03-03 10
2015-03-04 30
2015-03-05 30
2015-03-06 20
分析:根据题目描述的输入输出,很容易知道思路哈,就是想要把从开始时间到结束时间的每一条数据都拆开存储,然后根据日期去聚合就可以得到每天的欠费金额了,所以难点就在于如何根据一个起始时间来进行拆分呢?
一行转多行,让我们可以想到的就是使用炸裂函数explode/posexplode,显然我们想要的是 生成开始时间到结束时间的长度,然后遍历这个长度,在开始时间上进行累加就可以得到所有日期了,因此使用posexplode才可以完成这个目标。
总结:posexplode可以用于生成动态日期序列
select date,sum(amount) as total_amount
from (selectdate_add(start_date,id) as date, amountfrom tmplateral view posexplode(split(space(datediff(end_date,start_date)),' ')) t as id,t_date
) t
group by date6、面经真题
第七部分 大厂面经合集
美团、蚂蚁、阿里、字节跳动、百度、滴滴、网易、快手、微众、京东、携程
1、研二大数据开发寒假找实习总结
只学了离线部分的技术栈,没学flink,做了一个离线数仓。
1.同程旅行。雪花模型和星型模型区别,窗口函数举例,mr和spark比较,数据倾斜怎么解决。总体来说问的很简单很基础,没有当场写sql题。
2.爱奇艺。八股几乎没问,问我了解hive优化吗?我说了解,然后就没了。出了三个sql题,至少连续登录三天的用户,炸裂函数的简单题,每个电影观看数量前三的用户。
3.蔚来汽车。一个sql题,十二月份登录次数最多的用户的id和登录次数。八股问的hadoop写过程,shuffle过程,对数仓整体的理解。
4.快手。面的是电商方向的,我正好做的也是电商数仓,问我为什么做电商数仓,对于数仓的理解。然后是一个sql题,场景是打车,一共三小问,不算难,第二小问涉及到表中的数据倾斜问题,问怎么解决的。
5.网易。问了一些宽泛的比较深入的关于数仓业务的问题,答的不好。出了个sql题,题目和表的字段都是面试官口述的,自己都讲不清,脑缠玩意一个,呵呵。
6.百度。面了快一个小时。八股问的很多,我写的技术栈几乎每个都问了一两个问题。项目也问的多,包括每层都干了啥,怎么构建的。最后出了一个中等难度的sql题。题目和表的字段同样是口述的,我还需要先打开记事本记一下题目和表的字段。
总结:八股的话背了某谷的面试题总结足够应付了。做sql题一定不要紧张,sql做对,面试就稳了。2、字节跳动 商业化产品与技术-大数据开发岗 日常实习 已oc
一面
简单介绍一下自己
你的这些知识都是课程有教的吗
问了些计网和操作系统(没想到数仓岗还会问计网和操作系统)
进程和线程的区别
tcp和udp有什么不同
arraylist和linkedlist有什么区别
jvm的内存区域有什么
java面向对象的特性是什么
Threadlocal是怎么实现的(当时没答出来)
十大排序有哪些,时间复杂度为nlogn的有什么
说一下常见的数据结构
数仓数仓分层的意义
如果一条sql执行的很慢你会怎么排查原因
数仓对业务侧的影响是什么
hive遇到什么算子会进行shuffle
内部表和外部表的区别
什么时候用内部表什么时候用外部表
hive提交sql后续会发生什么
如何设置MRmap端和reduce端的大小
你有数据治理的经验嘛
算法题:sql:查找首次消费首月大于1000的集团 oc
先找到集团首次消费的日期,再拼接到表中筛选日期计算sum即可二面
然后就拷打了20分钟以前的实习经历
问了一些数仓的知识
你觉得数仓和业务的关系是什么
dm集市的作用
你有用过大模型嘛
离线和实时计算的区别是什么
既然你说到了lambda架构,能否说一下kappa架构
你有接触过什么olap引擎嘛
clickhouse为什么快
hbase适用于哪些场景
hbase为什么实时性能好
你有数据治理的经历嘛(在货拉拉做过一点,但不多,答的非常少)
sql题:去掉最高工资和最低工资的所有员工的平均工资(用两个窗口函数再union去重再算平均值即可)蚂蚁集团数据开发面经
一面(技术面)1小时
自我介绍;
介绍一下实习;
Flink数据倾斜的原因?
Flink如何保证数据不丢失?
介绍一下数据流和数仓架构?
解释一下被压?
介绍一下CheckPoint机制?
团队的工作和你的工作?
什么是AB测试?
现在的架构是什么?
如何保证实验层之间的正交?
产出的核心指标是什么?
实验的显著性如何计算?
实验的合规问题?
合规改造问题的设计思路?来源:nowcoder.com/discuss/353154551064764416
腾讯IEG(offer)
一面(全程问基础):
1、介绍项目
2、String、StringBuffer、StringBuilder的区别,怎么理解String不变性
3、==和equals的区别,如果重写了equals()不重写hashCode()会发生什么
4、volatile怎么保证可见性,synchronized和lock的区别,synchronized的底层实现
5、sleep和wait的区别,sleep会不会释放锁,notify和notifyAll的区别
6、了不了解线程的局部变量,讲讲线程池参数
7、什么情况会发生死锁,死锁的处理方法
8、Cookie和Session的区别,怎么防止Cookie欺骗
9、从用户在浏览器输入域名,到浏览器显示出页面的过程
二面(全程怼项目,压力面):
1、看你写过UDF,谈谈对UDF的理解,写UDF的目的,代码怎么写的
2、改造hive表后怎么进行数据一致性校验的,有没有自动化流程
3、看你读过kafka源码,讲讲kafka broker的源码里面你最熟悉的类,以及这个类的主要方法,用的什么设计模式
4、项目里面从数据采集到最终的数据可视化,每个环节都有可能丢数据,怎么判断数据有没有丢,如果丢了如何定位到在哪一个环节丢的
5、项目里面为什么要用kafka stream做实时计算,而不是用spark或者flink,kafka sql和spark sql了解过吗
6、项目里面用到了时序数据库opentsdb,为什么要用这个,有没有跟其它的时序数据库对比过
7、平时逛不逛社区,有没有参与过开源项目
三面(接着怼项目):
1、看你写了实时计算的程序,你怎么保证计算的结果肯定是对的
2、数据接入的时候,怎么往kafka topic里面发的,用的什么方式,起了几个线程,producer是线程安全的吗
3、kafka集群有几台机器,怎么确定你们项目需要用几台机器,有评估过吗,吞吐量测过吗
4、spark streaming是怎么跟kafka交互的,具体代码怎么写的,程序执行流程是怎样的,这个过程中怎么确保数据不丢
5、kafka监控是怎么做的,kafka中能彻底删除数据吗,怎么做的
面委会(全程聊天):
平时是怎么学习的,爱看哪些博客,怎么看待加班,有没有成为leader的潜力网易考拉(offer)
一面:
1、sql题:学生成绩表,把每科最高分前三名统计出来
2、算法题:二维数组中的查找
3、kafka如何保证高吞吐的,了不了解kafka零拷贝,具体怎么做的
4、sql有几种join,map join了解过没
5、hbase中row key该怎么设计
6、hdfs文件上传流程,hdfs的容错机制
7、怎么解决hive数据倾斜问题
二面(全程写写写):
1、算法题:二维矩阵相乘
2、算法题:链表中环的入口
3、写一下mysql binlog的数据格式,怎么进行数据清洗的
4、写一个正则表达式进行手机号匹配
5、讲一下数据仓库层级的划分,每层的作用美团新到店(offer)
去了北京美团公司里面试,一上午面完,第二天通知高分通过
一面(简单的聊了聊,10min):
1、介绍项目,以及滴滴的实习经历
2、JVM内存的划分
3、垃圾收集算法
4、数据建模,星型模型和雪花模型
5、数仓层级的划分,怎么对接到mysql拿数据
二面:
1、sql题:写一条sql删除订单表中重复的记录
2、sql题:一张网页浏览信息表,有两列,一列是网页ip,一列是浏览网页的用户(比如a或者b、c、d直到z),求这些网页被a和b或者a和c或者b和c两两组合访问的次数
3、hive数据倾斜产生的原因,怎么解决
4、设计学生成绩管理系统,符合第三范式要求,并绘出UML图
5、算法题:斐波那契数列
6、spark程序的运行流程
7、spark streaming从kafka中读数据的两种方式
8、讲讲数据库索引,B树和B+树
9、Elasticsearch的索引,单field索引和多field的联合索引
10、linux查看某文件的大小,vim中怎么替换内容
11、海量数据的Count问题(单机),如果把大文件hash成不同的小文件,此时小文件装不下某个key对应的数据,该怎么办
12、智力题:8升水,有一个5L的杯子和3L的杯子,怎么得到4升水
三面:
1、osi七层模型,三次握手和四次挥手,为什么两次握手不行
2、kafka怎么保证高吞吐量,项目中有测过吞吐量吗,相比于其它MQ,为什么会选择kafka,kafka怎么保证exactly once语义
3、了解hbase吗,hbase为什么查询速度快
4、hive sql怎么转换成底层的MapReduce程序,以及shuffle的过程
5、算法题:被围绕的区域,leetcode第130题原题
6、智力题:一头母牛每年生一头小母牛,每头小母牛从第四年开始,每年也会生一头小母牛,写个公式求第n年会有多少头牛小米(offer)
一面:
1、java和python的区别,对面向对象的理解,和面向过程相比有什么区别
2、java为什么不能多继承
3、讲一下java抽象类和接口
4、java中为什么要写非static方法
5、volatile和synchronized的区别
6、算法题:跳台阶问题
7、算法题:树的非递归后序遍历
8、设计题:一个停车场有一些大车位和小车位,大车只能停大车位,小车既能停大车位又能停小车位,实现这种场景下的调度系统
二面:
1、算法题:输入一个字符串,输出该字符串中字符的所有排列贝壳(offer)
一面:
1、synchronized的底层实现
2、线程等待时位于哪个区域,具体讲一下
3、谈谈对kafka的理解,能讲多少讲多少
4、算法题:二分查找
5、快排的时间复杂度和空间复杂度,最优情况和最差情况分别是多少,是稳定排序吗,快排为什么快
二面:
1、介绍项目,项目中涉及到了一些算法,介绍一下
2、两道算法题:路径问题,leetcode上63题和64题原题
3、写正则表达式匹配电话号码
4、智力题:一张圆桌子,我和面试官轮流往桌子上放硬币(随便放),直到桌子放不下为止,最后一个放硬币的人赢,如果我先放,怎么保证我肯定赢华为(offer)
一轮玄学面:
面试官是做安卓的,瞧不起大数据,觉得大数据很虚,我跟他bb了一堆。然后问我有没有女朋友,我说以前有,现在分了;问我什么时候谈的,什么时候分的,我说本科谈的,毕业分了;问我为什么要分,此处省略一万字......问我现在想没想过再谈,我说毕竟转专业过来的,想趁在校期间利用好短暂的时光提升自己的技术水平(其实因为找不到);然后面试官说以后工作了就不好找咯,我说您说的有道理............快手(offer)
一面:
1、jvm类加载机制,类加载器,双亲委派模型
2、java实现多线程的方式
3、spark怎么划分stage,宽窄依赖,各包括哪些***作
4、zookeeper怎么保证原子性,怎么实现分布式锁
5、写个快排,为什么要用三数取中法,好处是什么
二面:
1、sql题:找出单科成绩高于该科平均成绩的同学名单(无论该学生有多少科,只要有一科满足即可)
2、sql题:找出单科成绩高于该科平均成绩的同学名单(该学生所有科都必须满足)
3、算法题:求数组中连续子数组的最大和
4、算法题:使用最小花费爬楼梯,leetcode746题原题
三面:
1、讲一下java IO
2、算法题:输入n个整数,找出其中最大的k个数
3、算法题:给一个整数数组和一个目标值,找出数组中和为目标值的两个数完美世界(offer)京东广告部(四面完没了消息)阿里菜鸟(三面完已回绝)
阿里的面试还是比较重视基础的,应该是bat里面问基础问的最多的
一面:
1、HashMap和HashTable的区别,HashMap怎么解决hash冲突,jdk1.8后对HashMap的改进
2、讲讲ConcurrentHashMap,ConcurrentHashMap怎么保证线程安全,HashTable怎么保证线程安全
3、HashSet的底层实现,是不是线程安全的
4、ArrayList和LinkedList的区别,是不是线程安全的
5、讲讲设计模式,最常用哪种设计模式,单例模式的实现方式
6、进程和线程,Java实现多线程的方式,什么是线程安全,怎么保证多线程线程安全
7、可重入锁的可重入性是什么意思,哪些是可重入锁
8、为什么要用线程池,线程池的好处
9、JVM垃圾处理方法,对象什么时候进入老年代,什么时候进行FullGC
10、Java堆溢出问题怎么处理,内存泄漏和内存溢出的区别
11、智力题:50个红球和50个黑球往两个桶里放,然后自己去抽,怎么样才能使抽到红球的概率最高
二面:
1、讲讲数据库存储引擎
2、介绍一下索引,索引设置的规则,聚簇索引和非聚簇索引的区别,索引的最左前缀原则
3、用过redis吗,redis支持哪些数据类型,redis与mysql的区别
4、了解垃圾收集器吗,分别介绍介绍
5、jvm调优做过没,-Xms和-Xmx分别指什么
6、算法题:输入两个字符串,输出它们合并排序后的结果
三面:
1、讲讲数据库的范式
2、Linux进程通信和线程通信
3、线程池的参数
4、什么是内部类,什么是匿名内部类
5、设计题:一个市有9个消防站,现在要新增3个消防站,这3个消防站应该放在哪里nowcoder.com/creation/subject/5f73b0bd419a4cada3dfb12e50aa869a
携程 大数据底层框架开发 面经回顾
携程-大数据底层框架开发岗位的offer,
这个岗位是做大数据组件底层二次开发的,我面试的是偏向离线方面,因此面试都是围绕hadoop、spark、hbase、hive这几个组件的底层原理去问,因为是偏向底层,所以也会注重java语言和多线程并发的知识。
HDFS的写入流程?如果一台机器宕机,HDFS怎么保证数据的一致性?如果只存活一台机器又会发生什么情况?
NameNode HA的实现原理?如何避免NameNode脑裂的情况?
如果数据量比较大,如何解决NameNode 的内存瓶颈?
MapReduce Shuffle中Reduce是怎么获得Map输出的分区文件,Map主动推还是Reduce主动拉?
Kafka如何实现顺序消费?
Spark Streaming消费Kafka的两种方式比较。如何提高Spark Streaming消费Kafka的并行度?
如何保证Spark Streaming的精准一次性消费?
项目中Spark Streaming消费Kakfa的offset保存在哪里?为什么不采用checkpoint保存offset,有什么缺点?
对Spark RDD的理解。
Spark作业运行流程?(从standalone和yarn两种模式进行阐述)
项目中Spark采用的那种模式搭建的?为什么采用standalone而不采用yarn模式?
为什么Spark Shuffle比MapReduce Shuffle快(至少说出4个理由)?
Spark3新特性
Java中保证线程安全的方法有哪些?
一个volatile修饰的变量,如果两个线程同时去写这个变量,线程安全吗?如果不安全该怎么使他变得安全?
Linux中怎么查看一个进程打开了哪些文件?
算法题:二叉树非递归中序遍历—————————————————————————
截止春招3月份,八股系列一共是八篇。感觉是一个很巧的数字,后续大概就不再更新了。
-
之前主要是突击应对每次突如其来的面试,提供的八股目录索引。
-
更专业具体的知识和详细的内容,并不是几篇文章可以讲清楚的,重复详细可以见专栏的分类目录(如后端部分,数据部分等等),而且Redis,MySQL这种更新过了,重复梳理又用数字递增的方式编排感觉不太合理。
-
目录里无限制的知识细节更新,寓意知识学无止境,面试和offer也最好是无止尽的,而不是被限制在有限的数字更新上。
1、秋招五篇,对应当时某厂的后端五面。
2、春招三篇,对应算法、JAVA后端(或大数据开发)、客户端(或测试、运维)的三次面试。
最后完结前,给本文补个JAVA后端开发的JD:
JD:
美团-软件开发工程师-后端方向-1小时左右
金融服务平台 技术平台岗位职责
1.负责各类后台服务和业务系统的需求分析、系统设计、开发实现;
2.参与后端模块、数据平台、基础服务等的开发工作;
3.分析并优化业务流程,参与系统长期架构设计与规划,探索合理、可扩展的系统模型,通过自动化等手段提升研发效率,提升需求迭代速度与系统能力;
4.保证系统稳定性,提升系统的容灾、降级及应急能力,提升系统的可用性和可维护性,协同QA保证高质量开发交付,优化系统性能、及时排查线上故障,保证系统稳定;
5.积极主动协调相关团队完成项目,促进团队合作,积极影响其它成员。任职要求
1.本科及以上学历;
2.掌握一种以上的开发语言,包括但不限于Java、C、C++、Python、Golang等,了解MySQL等基本使用,熟练使用SQL语句,会常用的shell命令;
3.具有扎实的数据结构、操作系统、数据库、算法、网络等计算机基础知识;
4.优秀的学习能力和自驱力,对新技术有强烈的求知精神,能深入代码研究,能通过英文论文等第一手资料了解业界新技术,积极学习新技术提升自我、提升团队;
5.优秀的逻辑思维能力,特别是流程梳理能力和建模能力,善于从复杂系统表象中分析问题。具有较强的解决问题能力,对解决复杂问题充满激情;
6.善于交流,有良好的团队合作精神和协调沟通能力,有一定推动能力。具备以下经验者优先:
1.有参与各级计算机竞赛并获奖经历;
2.有原创的技术博客或者开源项目或者参与过知名的开源项目。岗位亮点:
1.美团业务场景复杂,能够接触商家、销售、广告营运、骑手等的各种需求,流量超大,且仍在高速发展中,相关的后台系统建设非常具有挑战性;
2.公司技术氛围浓厚,对外有知名的技术博客,对内有技术学院和技术委员会,大牛众多,各层级的技术交流和培训机制非常完善。