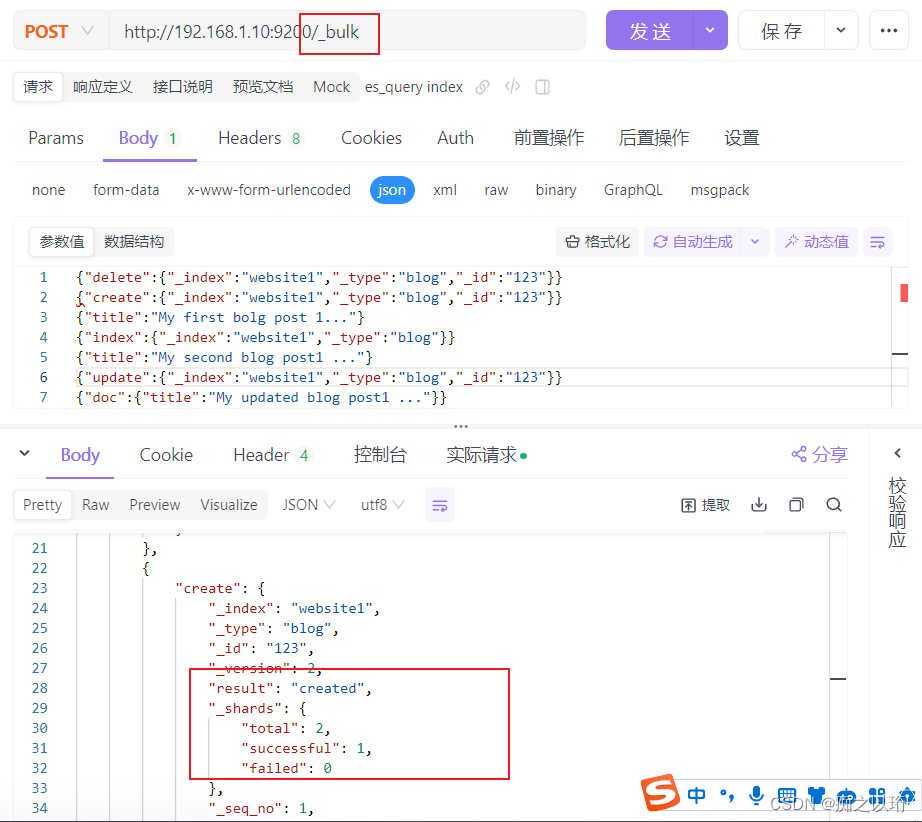
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
与计算机一样的古老历史
神经网络的出现可追溯到20世纪40年代,因此,其有相当长的发展历史。
咱们将介绍神经网络的发展历史,因为你需要了解一些术语。
激活函数是其中一个很好的例子,它可以缩放神经网络中神经元的值。
阈值激活函数是研究人员引入了神经网络时的早期选择,而后S型激活函数、双曲正切激活函数、修正线性单元(Rectified Linear Unit,ReLU)激活函数等相继被提出。
虽然目前大多数文献都建议仅使用ReLU激活函数,但你需要了解S型激活函数和双曲正切激活函数,才能理解ReLU激活函数的优势。
在神经网络的发展历程中,神经网络曾几次从灰烬中重生。
McCulloch W.和Pitts W.(1943)首先提出了神经网络的概念。但是,他们没有方法来训练这些神经网络。程序员必须手工制作这些早期神经网络的权重矩阵。由于这个过程很烦琐,因此神经网络首次被弃用了。
Rosenblatt F.(1958)提出了一种训练算法,即反向传播算法,该算法可自动创建神经网络的权重矩阵。实际上,反向传播算法有许多神经元层,可模拟动物大脑的结构,但是,反向传播算法的速度很慢,并且会随着层数的增加变得更慢。从20世纪80年代到20世纪90年代初期计算能力的增加似乎有助于神经网络执行任务,但这个时代的硬件和训练算法无法有效地训练多层神经网络,神经网络又一次被弃用了。
神经网络的再次兴起,是因为Hinton G.(2006)提出了一种全新的深度神经网络训练算法。高速图形处理单元(Graphics Processing Unit,GPU)的最新进展,使程序员可以训练具有三层或更多层的神经网络。程序员逐步意识到深层神经网络的好处,从而促使该技术重新流行。
咱们这个系列的文章将从分析经典的神经网络开始,这些经典的神经网络对各种任务仍然有用。
我们的分析包括一些概念,如自组织映射(Self-Organizing Map,SOM)、霍普菲尔德神经网络(Hopfield neural network)和玻尔兹曼机(Boltzmann machine)。
咱们应该还会涉及前馈神经网络(FeedForward Neural Network,FFNN),展示几种训练它的方法。当然,您已经猜到了,具有许多层的前馈神经网络变成了深度神经网络。其它还有如如随机Dropout、正则化和卷积等。

知识背景
大多数行业外的人都认为神经网络是一种人工大脑。根据这种观点,神经网络可以驱动机器人,或与人类进行智能对话,但是,与神经网络相比,这个概念更接近AI的定义。尽管AI致力于创建真正的智能机器,但计算机的当前状态远低于这一目标。人类的智能仍然胜过计算机的智能。
神经网络只是AI的一小部分。正如神经网络目前的样子,它们执行的是微小的、高度特定的任务。与人脑不同,基于计算机的神经网络不是通用的计算设备。此外,术语“神经网络”可能会给人造成困惑,因为由大脑神经元构成的网络,也被称为神经网络。为了避免这个问题,我们必须做出重要的区分。
实际上,我们应该将人脑称为生物神经网络(Biological Neural Network,BNN)。大多数文章都不会特别区分BNN和人工神经网络(Artificial Neural Network,ANN),咱们也会这样。当我们提到“神经网络”这个术语时,指的是ANN而不是BNN。
BNN和ANN具有一些非常基本的相似性。如BNN启发了ANN的数学构造。生物合理性描述了各种ANN算法。“神经网络”这个术语决定了ANN算法与BNN算法的高度相似性。
程序员设计神经网络来执行一项小任务。完整的应用程序可能会使用神经网络来完成应用程序的某些部分,但是,整个应用程序不会只实现一个神经网络。它可能由几个神经网络组成,每个神经网络都有特定的任务。
模式识别是神经网络可以轻松完成的任务。对于这种任务,你可以将一个模式传入神经网络,然后它将一个模式传回给你。在最高层面上,典型的神经网络只能执行这个功能。尽管某些神经网络可能会取得更大的成就,但绝大多数神经网络以这种方式工作。
下图展示了这个层面上的一个神经网络。

上述神经网络接收一个模式并返回一个模式。
神经网络是同步运行的,只有在输入后才会输出。这种行为不同于人脑,人脑不是同步运行的。人脑对输入做出响应,但是它会在任何它愿意的时候产生输出!(呵呵)
神经网络结构
神经网络由一些层组成,各层的神经元相似。
大多数神经网络都至少具有输入层和输出层,程序将输入模式交给输入层,然后,输出模式从输出层返回。在输入层和输出层之间是一个黑盒。黑盒是指你不完全了解神经网络为何输出它的结果。现在,我们还不关心神经网络或黑盒的内部结构。许多不同的架构定义了输入层和输出层之间的不同交互。
稍后,我们将研究其中一些架构。
输入和输出模式都是浮点数数组。用以下方式表示这些数组。
神经网络输入:[−0.245, 0.283, 0.0]。
神经网络输出:[0.782, 0.543]。
上面的神经网络在输入层中有三个神经元,在输出层中有两个神经元。即使重构神经网络的内部结构,输入层和输出层中神经元的数量也不会改变。
要利用该神经网络,你调整表达问题的方式,使得输入是浮点数数组。同样,问题的解也必须是浮点数数组。归根结底,这种表达是神经网络唯一可以执行的。换言之,它们接收一个数组,并将其转换为第二个数组。神经网络不会循环,不会调用子程序,或执行你在传统编程中可能想到的任何其他任务。神经网络只是识别模式。
你可以认为神经网络是传统编程中将键映射到值的哈希表。
它的作用有点像字典。你可以将以下内容视为一种类型的哈希表:
● “hear”→“以耳朵来感知或理解”;
● “run”→“比走路更快地前进”;
● “write”→“使用工具(作为笔)在表面上形成形状(作为字符或符号)”。
该表在单词和它们的定义之间创建了映射。编程语言通常称之为哈希映射或字典。
上述哈希表用字符串类型的键来引用另一个值,引用的值也是相同类型的字符串。
如果你以前从未使用过哈希表,那么可以将它们理解为将一个值映射到另一个值的一种索引形式。换言之,当你为字典提供一个键时,它会返回一个值。大多数神经网络都以这种方式工作。
一种名为“双向关联记忆”(Bidirectional Associative Memory,BAM)的神经网络可让你提供值并给出键。
编程时使用的哈希表包含键和值。可以将传入神经网络输入层的模式视为哈希表的键,将从神经网络输出层返回的模式视为哈希表返回的值。尽管类比哈希表和神经网络可以帮助你理解这个概念,但是你需要认识到神经网络不仅仅是哈希表。
如果你提供的单词不是映射中的键,那么前面的哈希表会发生什么呢?
为了回答这个问题,我们将输入键“wrote”。对于这个例子,哈希表将会返回null。它会以某种方式表明找不到指定的键。但是,神经网络不会返回null,而是找到最接近的匹配项。它们不仅会寻找最接近的匹配项,还会修改输出以估计缺失的值。因此,如果你对神经网络输入“wrote”,那么很可能会收到输入“write”时期望的结果。你也可能会收到其他键对应的输出,因为没有足够的数据供神经网络修改响应。数量有限的样本(在这个例子中是3个)会导致出现这种结果。
上面的映射提出了关于神经网络的重要观点。如前所述,神经网络接收一个浮点数数组并返回另一个数组。这个行为引发了一个问题,即如何将字符串或文本值放入神经网络。尽管存在解决方案,但对神经网络而言,处理数字数据比处理字符串要容易得多。
实际上,这个问题揭示了神经网络编程中最困难的一个方面。如何将问题转换为固定长度的浮点数数组?
在下面的示例中,你将看到神经网络的复杂性。
一个简单的例子
在计算机编程中,习惯提供一个“Hello World”应用程序,它只是显示文本“Hello World”。
如果你已经阅读过有关神经网络的文章,那么肯定会看到使用异或(XOR)运算符的示例,该运算符示例是神经网络编程的一种“Hello World”应用程序。
在后文,我们将描述比XOR更复杂的场景,但它是一个很好的示例。
我们将从XOR运算符开始,把它当作一个哈希表。如果你不熟悉XOR运算符,其工作原理类似于AND/OR运算符。
要使AND运算结果为真,双方都必须为真;
要使OR运算结果为真,必须有任何一方为真;
要使XOR运算结果为真,双方真假必须互不相同。
XOR的真值表如下:

用哈希表表示,则上述真值表表示如下:

这些映射展示了神经网络的输入和理想的预期输出。
训练:有监督和无监督
如果指定了理想的输出,你就在使用有监督训练;
如果没有指定理想的输出,你就在使用无监督训练。
有监督训练会让神经网络产生理想的输出,无监督训练通常会让神经网络将输入数据放入由输出神经元计数定义的多个组中。
有监督训练和无监督训练都是迭代过程。对于有监督训练,每次迭代都会计算实际输出与理想输出的接近程度,并将这种接近程度表示为错误百分比。每次迭代都会修改神经网络的内部权重矩阵,目的是将错误率降到可接受的低水平。
对于无监督训练,计算错误并不容易。由于没有预期的输出,因此无法测量无监督的神经网络与理想输出差多少。因为没有理想的输出,所以你只是进行固定次数的迭代,并尝试训练神经网络。如果神经网络需要更多训练,那么程序会提供。
上述训练数据的另一个重要方面在于,你可以按任何顺序进行训练。无论哪种训练方式,对两个0应用XOR(0 XOR 0)的结果将为0。并非所有神经网络都具有这种特性。对于XOR运算符,我们可能会使用一种名为“前馈神经网络”的神经网络,其中训练集的顺序无关紧要。咱们在以后的文章中将研究循环神经网络(Recurrent Neural Network,RNN),它确实需要考虑训练数据的顺序。顺序是简单循环神经网络的重要组成部分。
刚才,你看到简单的XOR运算符利用了训练数据。
现在,我们将分析一种情况,它使用了更复杂的训练数据。
每加仑的英里数
通常,神经网络问题涉及一些数据,你可以利用这些数据来预测后来的数据集的值。在训练了神经网络之后,就会得到后来的数据集。神经网络的功能是根据从过去的数据集中学到的知识,来预测全新数据集的结果。
考虑一个包含以下字段的汽车数据库:
● 车重(指车的质量);
● 发动机排量;
● 气缸数;
● 马力(指以马力为单位的功率);
● 混合动力或汽油动力;
● 每加仑的英里数[指每消耗1加仑(约3.8升)燃油可行驶的路程,以英里为单位]。
尽管我们过度简化了数据,但并不影响本示例演示如何格式化数据。
假设你已经针对这些字段收集了一些数据,那么你应该能够构建一个神经网络,来根据其他字段的值来预测某个字段的值。对于这个示例,我们将尝试预测每加仑的英里数。
如前所述,我们需要将一个浮点数输入数组映射到浮点数输出数组,从而定义这个问题。但是,该问题还有一个附加要求,即这些数组元素中每一个数字的范围应为0~1或者−1~1。这个操作称为归一化。它获取现实世界的数据,并将其转换为神经网络可以处理的形式。
首先,我们需要确定如何归一化以上数据。请考虑神经网络的架构。
我们共有6个字段,要使用其中5个字段来预测剩余的1个字段。
因此,神经网络将具有5个输入神经元和1个输出神经元。
你的神经网络类似下面这样:
● 输入神经元1:车重。
● 输入神经元2:发动机排量。
● 输入神经元3:气缸数。
● 输入神经元4:马力。
● 输入神经元5:混合动力或汽油动力。
● 输出神经元1:每加仑的英里数。
接着我们还需要归一化数据。为了完成归一化,我们必须为这些字段的值都考虑一个合理的范围。然后,我们将输入数据转换为0~1的数字,代表该范围内实际值的位置。
考虑以下设置了合理范围的示例:
● 车重:100~5 000磅(约45~2 268千克)。
● 发动机排量:0.1~10升。
● 气缸数:2~12。
● 马力:1~1 000马力(约735.5~7 355 000瓦)。
● 混合动力或汽油动力:true或false。
● 每加仑的英里数:1~500英里(约1.6~804.5千米)。
考虑到当今的汽车,这些范围可能很大,但是,这个特征将使神经网络的重组最少。我们也希望避免在靠近范围的两端出现太多数据。
为了说明这一范围,我们将考虑归一化车重2 000磅(约907千克)的问题。这在上述车重范围中为1 900(即2 000−100),而范围的大小为4 900(即5000−100),范围大小的占比为0.38(即1 900/4 900)。因此,我们会将0.38提供给输入神经元,以表示该值。这个过程满足输入神经元0~1的范围要求。
混合动力或常规动力字段的值为true或false。为了表示该值,我们用1表示混合动力,用0表示常规动力。我们只需将true或false归一化为1或0两个值即可。
既然你已经了解了神经网络的一些用法,现在该确定如何为特定问题选择合适的神经网络了。
在随后的内容中,我们提供了各种可用的神经网络路线图。
神经网络路线指引
并不是所有神经网络都适用于每一个问题域。作为神经网络程序员,你需要知道针对特定问题使用哪个神经网络。
(神经网络类型和问题域)
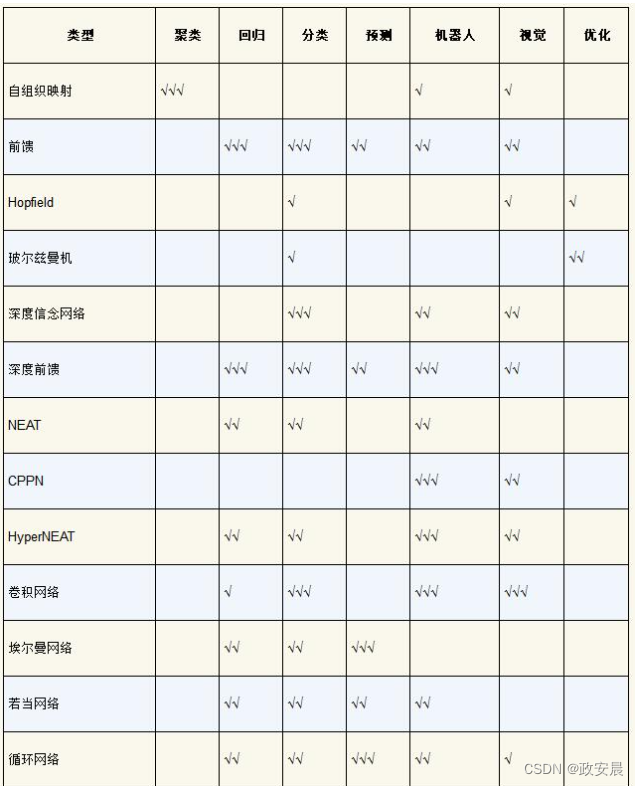
● 聚类:无监督的聚类问题。
● 回归:回归问题,神经网络必须根据输入,输出数字。
● 分类:分类问题,神经网络必须将数据点分为预定义的类别。
● 预测:神经网络必须及时预测事件,如金融应用程序的信号。
● 机器人:使用传感器和电机控制的机器人。
● 视觉:计算机视觉(Computer Vision,CV)问题,要求计算机理解图像。
● 优化:优化问题,要求神经网络找到最佳排序或一组值以实现目标。
勾选标记(√)的数量给出了每种神经网络类型对该特定问题的适用性。如果没有勾选,则说明无法将该神经网络类型应用于该问题域。
所有神经网络都有一些共同的特征,如神经元、权重、激活函数和层,它们是神经网络的构建块。
这就是您开启咱们这个系列文章的全部背景知识啦。


![每日一题--- 环形链表[力扣][Go]](https://img-blog.csdnimg.cn/img_convert/b1805b2c1266bcd940b15cce3e716f97.png)