文章目录
- 一. BlobServer架构
- 1.BlobClient
- 2. BlobServer
- 3. BlobCache
- 4. LibraryCacheManager
- 二、BLOB的生命周期
- 1. 分阶段清理
- 2. BlobCache的生命周期
- 3. BlobServer
- 三、文件上下载流程
- 1. BlobCache 下载
- 2. BlobServer 上传
- 3. BlobServer 下载
- 四. Flink中支持的BLOB文件类型
- 1. BLOB文件类型
- 2. 按存储特性又分为两类
- 五. Use Cases Details
- 1. Jar 文件
- 2. RPC 消息
- 3. 日志
- 六、相关参数
一. BlobServer架构
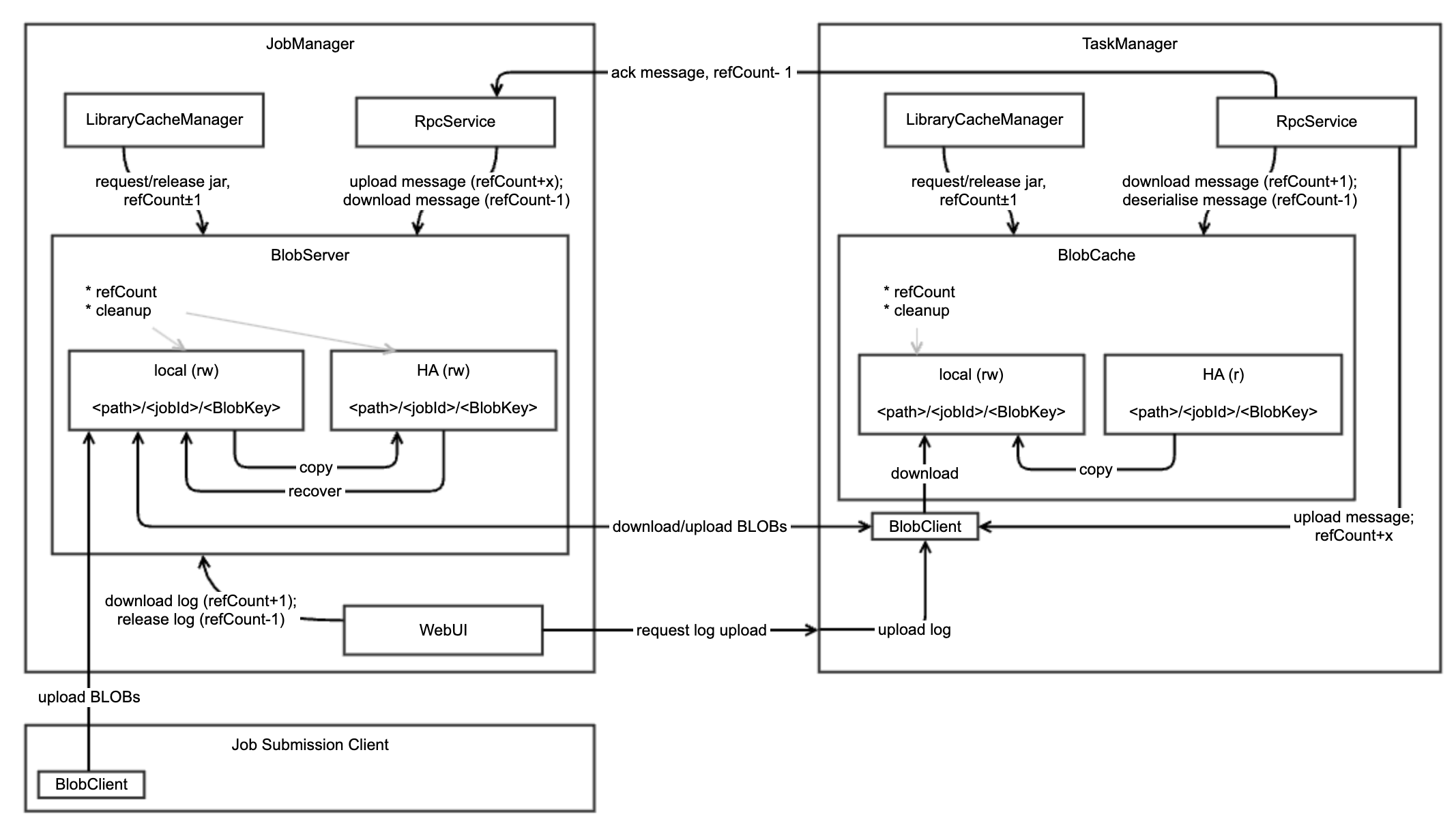
BlobServer是jobmanager的组件, 是一个用来管理二进制大文件的服务,比如保存用户上传的jar文件,该服务会将其写到磁盘上。还有一些相关的类,如BlobCache,用于TaskManager向JobManager下载用户的jar文件。
如下blob-store-architecture:
1.BlobClient
- 提供上传和下载的接口
- 与BlobServer进行通讯
2. BlobServer
- 提供了基于jobId和BlobKey进行文件上传和下载的方法;
- 本地、HA 分布式文件系统的读写:基于
<path>/<jobId>/<BlobKey>目录结构,进行HA恢复中,下载分布式系统中的文件到本地文件系统中;- 负责本地和HA系统的清理工作
- 先存到本地,然后(如有需要)上传到HA(可能并行进行,确认之前等待两者完成)
- 文件下载只能通过本地文件系统中
- 恢复时,从HA下载所需文件到本地,并负责清理此路径下所有问题。
3. BlobCache
- 提供BlobServer文件(基于jobId和BlobKey)的缓存
- 提供(基于
<path>/<jobId>/<BlobKey>目录结构 )本地文件的读写权限- HA store的读权限
- 能够从HA store or BlobServer下载文件
- 负责清除本地文件
4. LibraryCacheManager
桥接task的classloader和BlobCache中缓存的库BLOB(即 jar 文件),其registerJob,registerTask会构建并缓存job,task运行需要的classloader。
二、BLOB的生命周期
BlobCache 对其所有 BLOB 进行引用计数,并在 “blob.retention.interval” 秒后开始删除未被引用的文件。每个子目录与其各自的 BLOB 一起进行引用计数,并将以类似的方式进行删除。请注意,BlobCache 目前没有关于作业进入最终状态的信息,因此只能依靠引用计数来删除作业的 BLOB。
在 TaskManager 关闭时,我们可以清理子目录 <jobId>中的任何剩余文件。
BlobServer 将使用相同的引用计数技术,并适当地从本地和 HA 存储中删除文件。此外,它将通过了解作业何时进入最终状态来增加安全保障。在这种情况下,将删除作业的 BLOB 存储目录(本地和 HA),即 “/”,包括其所有的 BLOB 文件。
1. 分阶段清理
场景描述
直到 Flink 1.3,在 LibraryCacheManager 中,我们每小时运行一次定期清理任务(参见
library-cache-manager.cleanup.interval参数),删除任何未被引用的 jar 文件。如果作业的任务在清理开始之前失败,后续的恢复可能无法再访问缓存的文件。我们希望通过 “分阶段清理” 来改变这一点。
分阶段清理逻辑
- 在分阶段清理中,只有当(周期性的)清理任务第二次遇到此 BLOB 时,才会删除 BLOB 文件,例如通过拥有两个清理列表:一个用于实际清理,即 “立即删除”,一个用于分阶段文件,即 “下次删除”。
- 每次清理任务运行时,将删除实际清理列表(和文件),并将分阶段列表变为实际列表。这比为每个未被引用的 jar 设置存活时间的花销要小,并且对于当前的清理任务来说足够了。因此,(目前)未被引用的 BLOB 将至少保留 “blob.retention.interval” 秒,最多两倍于此数量。
2. BlobCache的生命周期
- 所有的 BLOB 都是引用计数的,从第一次检索/传递 BLOB 开始计数。
- 特定于作业的 BLOB子目录也会随着每个与作业相关的文件一起进行引用计数。
- 如果引用计数为 0,则该 BLOB 将进入分阶段清理(见上文)。
- 如果任务成功、失败或被取消,其所有 BLOB 的引用计数将适当地递减(如果可能)。 当 BlobCache 关闭时,即 TaskManager 退出时,应删除所有的 BLOB。
请注意,运行在同一 TaskManager 上的多个任务可能使用同一作业的BLOB 文件!
3. BlobServer
BlobServer 中存储的所有未使用的 BLOB 文件也应定期清理,而不仅仅是在 BlobServer 关闭时(自 Flink 1.3 起)。
- 所有的 BLOB 都是引用计数的,从初始上传开始计数。
- 特定于作业的 BLOB 子目录 (
<path>/<jobId>)不进行引用计数。- 两种类型的 BLOB 生命周期保证:HA(用于恢复保留)和非-HA(可重新创建文件,不用于恢复)。
- 如果作业失败,则所有非-HA 文件的引用计数将重置为 0;所有 HA 文件的引用计数保持不变,并且在恢复时不会再次增加。
- 如果作业进入最终状态,即完成或取消,作业特定的 BLOB 子目录 (
<path>/<jobId>) 及其所有的 BLOB 将立即被删除,并从引用计数中移除(尽管实际的引用计数可能不为 0)。- 如果引用计数为 0,则该 BLOB 将进入分阶段清理(见上文)。
- 当BlobServer 退出时,应删除所有的 BLOB。
注意,与特定于作业的 BLOB 目录一起,jar 文件通常会被删除,而短期存在的BLOB,如 RPC 消息或日志,主要基于引用计数进行删除。作业目录删除充当了它们的安全保障,以防引用计数出错。
三、文件上下载流程
1. BlobCache 下载
BlobCache的下载流程
当请求特定于作业 ID 和 BlobKey 的文件时,
- BlobCache 首先会尝试从其本地存储中提供该文件(在成功的校验和验证后)。
- 如果在本地存储中找不到文件或者校验和不匹配,文件将从 HA 存储复制到本地存储(如果可用)。
- 如果这种方法不起作用或者不可用,将使用通过 BlobClient 建立和管理的连接,从 BlobServer 直接下载到本地存储中。
在传输过程中,这些文件将被放入临时目录,并且只有在完全传输和校验和验证后才会提交到特定于作业的路径。
HOW:这可能会为同一文件触发多个(并发)下载,但确保在提供 BLOB 时不会使用不完整的文件。我们可以通过 BlobCache 阻止这样的多次下载作为优化。
2. BlobServer 上传
注意:
在上传用户 jar 文件时,相应的作业尚未提交,因此我们无法将 jar 文件绑定到不存在的作业生命周期。
这里可以提供思路:为什么flink本地临时jar不会被删除。
确保在上传和作业提交之间的客户端中止/崩溃期间的正确清理。
我们不能一次性上传每个文件并使用引用计数器为 0,因为在启动作业时,某些文件可能已经被删除。相反,我们将一起上传所有 jar 文件,并仅在收到最后一个文件后,将它们全部放入分阶段清理的分阶段列表中。然后作业需要在 “blob.retention.interval” 秒内提交,否则我们无法保证 jar 文件仍然存在。
3. BlobServer 下载
与 BlobCache 类似,我们首先尝试从本地存储中提供文件(经过校验和验证),如果文件不存在,则从 HA 存储中创建本地副本(如果可用) 。
四. Flink中支持的BLOB文件类型
1. BLOB文件类型
- jar包: 被user classloader使用的jar包
- 高负荷RPC消息
- RPC消息长度超出了akka.framesize的大小
- 在HA摸式中,利用底层分布式文件系统分发单个高负荷RPC消息,比如:TaskDeploymentDescriptor。
- 失败导致重新部署过程中复用RPC消息
- TaskManager的日志文件: 为了在web ui上展示taskmanager的日志
2. 按存储特性又分为两类
- PERMANENT_BLOB: 生命周期和job的生命周期一致,并且是可恢复的。会上传到BlobStore分布式文件系统中。
- TRANSIENT_BLOB:生命周期由用户自行管理,并且是不可恢复的。不会上传到BlobStore分布式文件系统中。
五. Use Cases Details
1. Jar 文件
在作业提交客户端提交作业之前,用户代码的 jar 文件会被上传。成功上传所有 jar 文件后,作业将被提交,JobManager/Dispatcher 将 BlobServer 上的引用计数增加 1。当作业进入最终状态时,引用计数将减少,此时将删除 目录。BlobCache 只需要在其本地存储中引用计数 jar 文件,不需要进一步交互。
2. RPC 消息
ing
3. 日志
目前日志文件仅由 Web 用户界面(Web-UI)用于显示 TaskManager 日志。它们在请求后下载并提供服务。每次下载应该将先前日志的引用计数减少 1,并将新日志的引用计数增加 1。日志具有非 HA 生命周期保证,甚至可以立即删除,而不是将它们放入分阶段清理中。
作为优化,我们可以支持将日志文件分区(即字节 xxxx-yyyy)作为 BLOB 上传,并在 WebUI 中使用它们,而不是一遍又一遍地传输相同的日志部分。然而,这与 BLOB 存储无关,并且受到上述体系结构的支持。
六、相关参数
| 参数 | 默认值 | 描述 |
|---|---|---|
| high-availability.storageDir | 无 | HA BlobStore根目录 |
| blob.storage.directory | <java.io.tmpdir> | BlobServer 本地文件根目录 |
| blob.fetch.num-concurrent | 50 | BlobServer fetch文件的最大并行度 |
| blob.fetch.backlog | 1000 | 允许最大的排队等待链接数 |
| blob.service.cleanup.interval | 3600 | BlobServer cleanup 线程运行的间隔 |
| blob.fetch.retries | 5 | 从BlobServer下载文件错误重试次数 |
| blob.server.port | 0 | BlobServer端口范围 |
| blob.offload.minsize | 1024 * 1024 | 运行通过BlobServer传递的最小消息大小 |
| classloader.resolve-order | child-first | classloader类加载顺序 |
参考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-19:+Improved+BLOB+storage+architecture