本文介绍的是一篇明为"A convolutional neural network-based conditional random field model for structured multi-focus image fusion robust to noise."的文献,主要包括文献的摘要、前言摘选、主要贡献、网络结构、实验结果及结论等方面。
- 文献名称
- 摘要
- 前言摘选
- 主要贡献
- 主要模块(策略)
- A. 一元项与一元网络
- B.光滑项与光滑网络
- 网络结构
- 实验
- 结论
文献名称

一种基于卷积神经网络的抗噪声结构多焦点图像融合条件随机场模型
Bouzos, Odysseas, Ioannis Andreadis, and Nikolaos Mitianoudis. “A convolutional neural network-based conditional random field model for structured multi-focus image fusion robust to noise.” IEEE Transactions on Image Processing (2023).
摘要

不标准翻译
摘要——光学透镜有限的景深,使得多焦点图像融合(MFIF)算法至关重要。最近,卷积神经网络(CNN)已被广泛用于MFIF方法,但它们的预测大多缺乏结构,并且受到感受野大小的限制。此外,由于图像具有由各种来源引起的噪声,因此需要开发对图像噪声具有鲁棒性的MFIF方法。本文介绍了一种新的基于条件随机场的抗噪声卷积神经网络(mf-CNNCRF)模型。该模型利用了CNN网络的输入和输出之间的强大映射以及CRF模型的长距离交互,以实现结构化推理。一元项和光滑项的丰富先验都是通过训练CNN网络来学习的。这个𝛼-扩展图切割算法用于实现MFIF的结构化推理。引入了一个新的数据集,其中包括干净和有噪声的图像对,并用于训练两个CRF项的网络。还开发了微光MFIF数据集,以演示相机传感器引入的真实噪声。定性和定量评估证明,对于干净和有噪声的输入图像,mf-CNNCRF优于最先进的MFIF方法,同时在不需要噪声先验知识的情况下对不同的噪声类型更具鲁棒性。
前言摘选

多焦点图像融合(MFIF)算法可用于通过将以不同焦点设置捕获的多个输入图像合并到具有扩展景深的单个融合图像中来处理光学透镜的有限景深问题。融合的图像应当具有比每个输入图像更高的视觉质量,而不会在融合期间引入伪影。此外,由于真实世界的图像包含噪声,例如传感器噪声和量化噪声,因此对不同噪声类型具有鲁棒性的MFIF方法是重要的。
现有方法主要可分为四大类:可变换域方法、空间域方法、组合方法和深度学习方法。

基于变换域的MFIF方法使用前向变换以将输入图像分解为各自的图像转换域表示,然后将其与定制的手工制作和预定义的融合规则进行融合。最后,对融合后的变换系数进行逆变换,得到最终的融合图像。由于融合图像的质量在很大程度上受到变换域选择和融合规则手动设计的影响,因此引入了大量基于变换域的MFIF算法。

最后,由于大多数基于变换域的MFIF方法都不是移位不变的,因此在输入图像中可能会发现由于动态场景而导致的配准错误或相机抖动,将导致融合中的可见伪影图像。

在空间域MFIF方法中,融合图像被估计为输入图像的加权平均值。基于所采用的活动水平估计,构建权重图并用于融合输入图像。空间域方法,可以根据用于活动水平估计的方法分类为基于块、基于区域和基于像素。在基于块的方法中,将输入图像分解为固定大小的块,并使用整个块的活动水平估计来构建权重图。块的大小在很大程度上影响融合图像的质量。

基于空间域的MFIF方法的一个主要缺点是它们对图像噪声的敏感性。
为了保持变换域和空间域的优势,出现了基于组合的MFIF方法。组合方法可能比变换域和空间域方法执行得更好。

传统MFIF方法的性能受到手工制作的特征和人工设计的融合规则的限制,无法完全模拟MFIF问题的复杂性。这导致基于深度学习的MFIF方法越来越受欢迎。基于深度学习的方法不需要手工设计用于焦点测量的特征,也不需要手动设计融合规则,这使得它们可能产生比传统MFIF方法更高质量的融合图像

对MFIF的深度学习方法进行了广泛的研究,并将其分为两大类:基于决策图的方法和端到端方法。
- 基于决策图的方法:在基于决策图方法中,网络根据输入图像的活动水平预测决策图。然后,通常应用后处理方法来细化预测的决策图。最后,使用最终决策图来指导输入图像的融合。

- 端到端:在端深度学习MFIF方法中,使用回归优化来训练网络,以学习输入图像和目标图像之间的映射,而不需要预测决策图的中间步骤。

为了结合基于深度学习的方法和CRF图的优点,同时克服它们各自的局限性,引入了基于CNN的CRF模型,命名为MFIF的mf-CNNCRF。
主要贡献

与上述CRF模型的应用相比,所提出的mf-CNNCRF框架非常不同。最重要的是,一元先验和平滑先验都是通过端到端训练的CNN架构来估计的。因此,开发了更适合MFIF的、更好地描述输入图像和目标图像之间的映射的丰富先验。预测的一元先验和平滑先验为CRF模型提供了补充信息,以便通过解决具有𝛼-扩展[50],它是基于图切割的。所提出的mf-CNNCRF方法是一种基于决策图的方法。

- 所提出的mf-CNNCRF模型结合了CNN网络的输入输出之间复杂映射和CRF模型的长距离交互的优点,从而在不需要进一步后处理的情况下实现MFIF的结构化推理。UnaryNet和SmoothnessNet都是使用低复杂度的CNN架构¬进行端到端训练的高效siamese网络,以便为MFIF学习丰富的复杂先验。这两种网络都为处理任意问题提供了相当大的速度𝑁 输入图像并支持输入图像的交换性。
- 所提出的mf-CNNCRF模型是在一个新的合成MFIF数据集上训练的,该数据集包含干净的图像和被高斯噪声、椒盐噪声和泊松噪声污染的图像。所提出的损失函数和所提出的数据集用于训练一元项和平滑项,使mf-CNNCRF对不同的噪声类型具有鲁棒性,而不需要关于¬输入图像的噪声特性的先验知识。因此,mf-CNNCRF对干净的输入图像和包含不同类型噪声的输入图像都具有很强的泛化能力。
3) 与之前的工作mf-CRF[24]相比,所提出的能量最小化方法的主要新颖之处在于使用CNN网络来对输入/输出的复杂关系进行建模,而之前的工作使用精心手工制作的先验来对一元和平滑项进行建模,以解决多焦点图像融合问题。
4)由于SmoothnessNet导致成对平滑先验,因此可以使用高效的成对解算器,而不是会增加复杂性的高阶CRF解算器。
不标准翻译
主要模块(策略)


不标准翻译
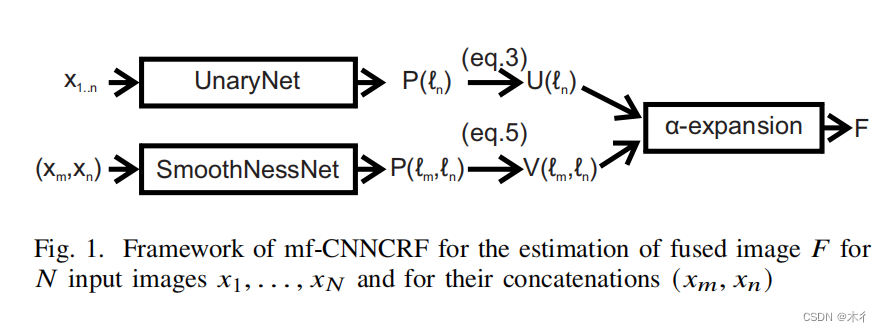
所提出的MFIF框架是基于决策图的,对于决策图D中的每个位置,我们在CRF图中创建一个节点。CRF图中的成对连接是通过将每个节点连接到位于N8邻域中的各个节点而形成的。一元势函数U和成对势函数V都是用端到端训练的CNN来估计的。更准确地说,学习一元势函数U的“UnaryNet”和学习成对势函数V的“SmoothnessNet”使用有效的siamese架构。这些网络允许并行处理任意数量的输入图像N,为MFIF的两个项的估计提供了高的计算效率和加速度。UnaryNet和SmoothnessNet支持输入图像到框架的交换性,因为每个网络的分支共享相同的架构和相同的权重。CNN网络的使用允许学习丰富的一元势和平滑势。所提出的能量最小化方法利用了通过CNN网络学习到的丰富潜力和CRF模型的长距离相互作用,以实现全局或接近全局MFIF解决方案。
为了估计决策图的标签,我们使用以下能量最小化:

A. 一元项与一元网络

CNN网络称为UnaryNet’通过数据进行训练,以便学习概率P(En),即每个输入图像En应在空间位置n处对最终融合图像做出贡献。2演示了用于N个输入图像的暹罗网络的体系结构,用于估计概率P(e)。UnaryNet’是一种高效的暹罗体系结构,使用N个分支等于N个输入图像的数量。每个分支以N个输入图像中的一个作为输入,而每个分支的输出被传递到决策层。一个N路softmax函数被用作决策层,以预测概率P(E,)。UnaryNet’的高效连体结构支持N个图像的估计计算效率。最后,并行处理的概率P(Ln)将一元势U(ln)估计为预测概率P(ln)的负对数似然。

UnaryNet的分支共享相同的架构和相同的权重。每个分支都是一个包含三个分支的ConvNet架构。ConvNet的第一个分支由滤波器大小【3x3x1x16】的卷积层和ReLu组成。接下来的两个卷积层有过滤器的大小[3x3x16x16],每一层都是被ReLu所轻视。ConvNet分支卷积层的最后一个具有过滤器大小【3x3x16x1】。在第二个分支中,第一个卷积层是水平轴上的Sobel梯度卷积滤波器3x3,然后是滤波器尺寸为【3x3】的卷积层第十六次然后是ReLu,2个具有滤波器尺寸3x3x16x16】的卷积层,然后是ReLu和一个具有滤波器尺寸【3x3x16x1】的卷积层。在第三分支中,第一卷积层是垂直轴上的Sobel梯度卷积滤波器3x3,接着是具有滤波器尺寸【3x3x1x16】的卷积层,接着是ReLu,具有滤波器尺寸【3x3x16x16】的2个卷积层,接着是ReLu和具有滤波器尺寸【三乘三乘十六乘一】。最后,深度拼接层用于收集所有三个分支的输出,带滤波器的卷积层【3x3x3x1】用于提取给定输入图像的最终输出。


通过数据训练UnaryNet,以学习的概率有效地通过损失函数最小化。UnaryNet的两个分支用于训练网络对输入图像的权重。这两个分支共享相同的架构和相同的权重。UnaryNet学习的概率依赖于输入图像和目标图像之间的像素强度的距离和像素特征的距离。对于与目标图像的像素和边缘相似的像素和边缘,学习较高的概率,而对于与各自的目标图像不同的像素和边缘,则学习较低的概率。UnaryNet的一个主要优势是概率不是手工生成的,而是由网络学习的,网络是端到端训练的。
所提出的损失函数允许网络学习与像素强度的距离和输入图像与目标图像之间的距离成正比的概率。损失函数是基于像素的,以便在聚焦和失焦像素的边界附近具有更好的精度。
B.光滑项与光滑网络

平滑项的目标Vpq是在属于聚焦-离焦像素边界的相邻像素p、q之间分配较低的成对代价,从而分配给可能属于同一输入图像的相邻像素p、q之间的更高的成对代价。为了预测决策图N8邻域中相邻像素p、q之间的标签兼容性,对“SmoothnessNet”进行了训练。训练“SmoothnessNet”以将高概率P(lp=l)分配给可能属于相同输入图像的相邻像素p,q并将高概率P(lp#l,)分配给可能属于不同输入图像的像素,从而分配给图割解决方案。
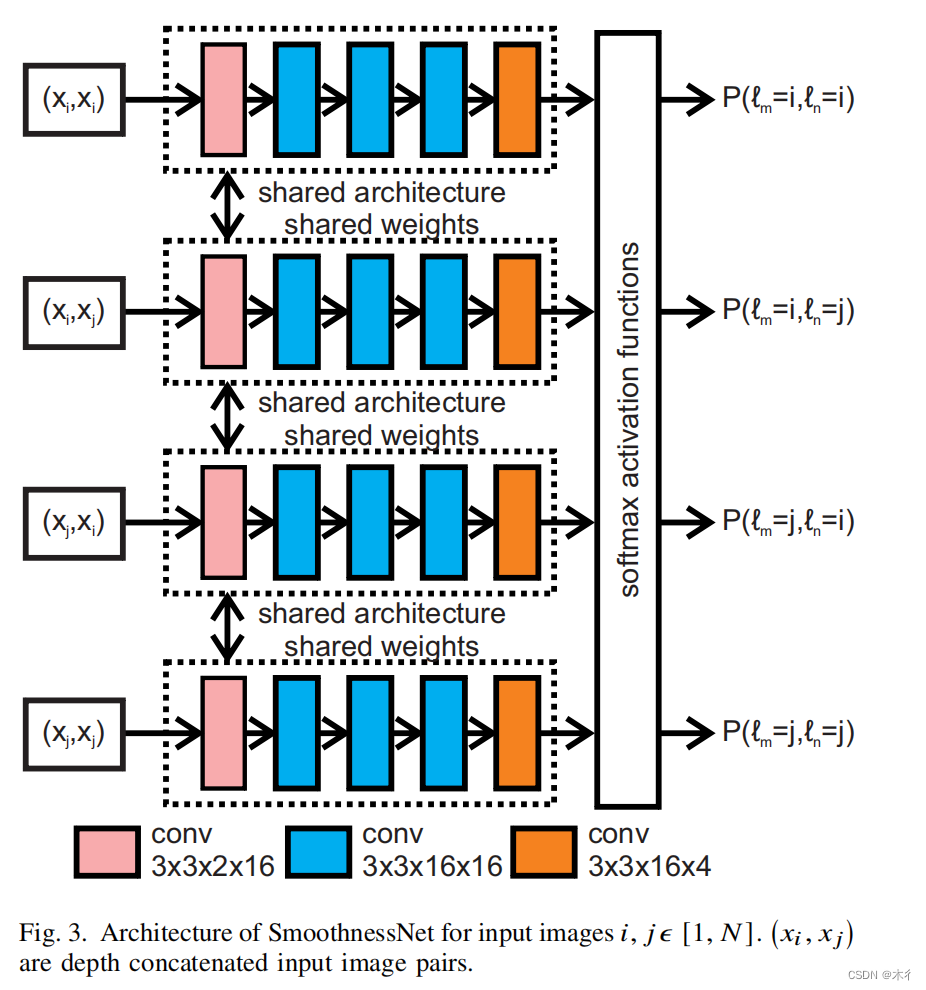
SmoothnessNet是一个有效的连体结构,允许任意N个图像的所有M输入图像组合,并行处理,以预测每个标签组合LP,lqe【1,N】相邻像素p,q之间的标签兼容性。
图3演示了用于预测两个输入图像和所有四个标签组合的标签兼容性概率的SmoothnessNet体系结构SmoothnessNet的每个分支以i,je1,N】的M个级联图像对组合中的一个作为输入,其中N是输入图像的总数。SmoothnessNet的分支共享相同的体系结构和权重。每个分支由五个卷积层组成。更精确地说,第一个卷积层有滤波器【3x3x2x16】,然后是tanh,接下来的三个卷积层有滤波器【3x3x16x16】,每个卷积层后面都是tanh


SmoothnessNet预测N8邻域内相邻像素之间的所有成对权值。两两权值是通过处理一个大邻域中的像素来估计的,这相当于光滑网络的接收域,然而,使用成对权值可以使带成对求解器的有效图解被用于代替高阶邻域的图割求解器建议的平滑网络架构的另一个主要优点是使用高效的连体结构,它允许许多输入图像同时进行处理,从而最终的平滑概率。
网络结构

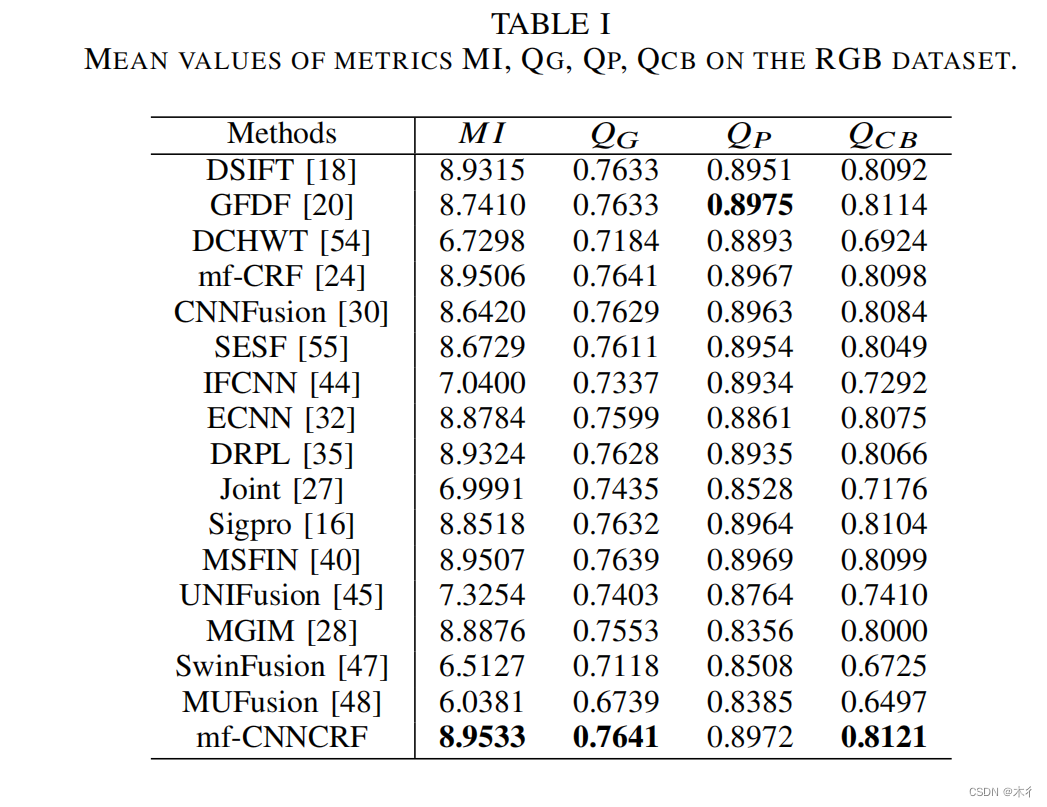
实验


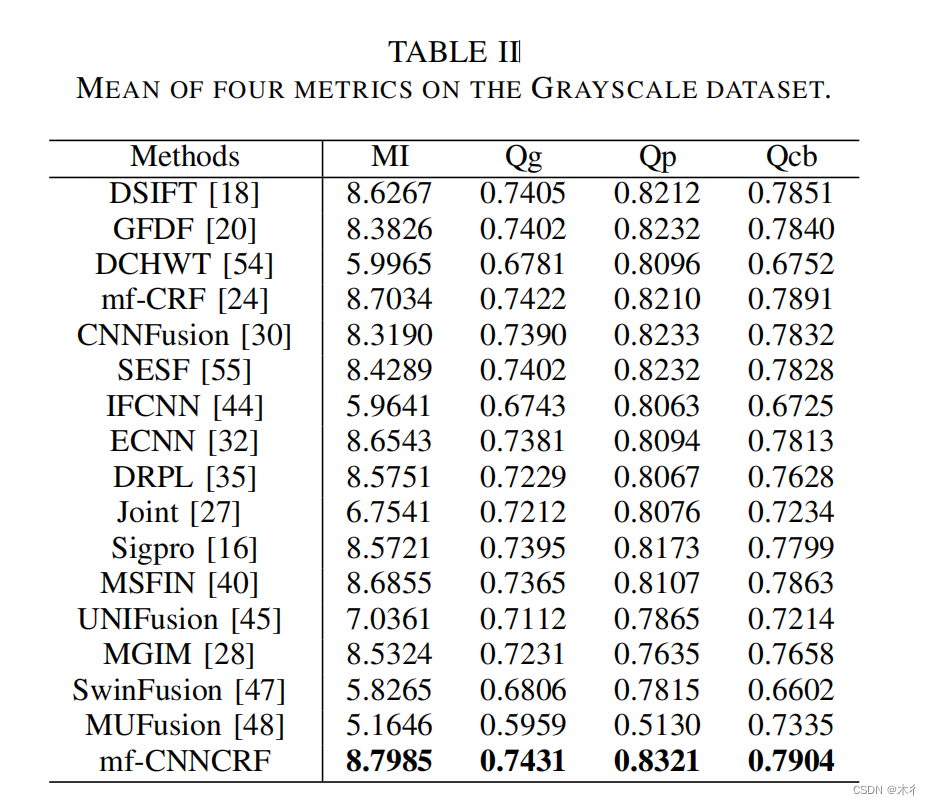



结论

提出了一种基于cnn的多聚焦图像融合crf模型mf-cnn crf。该方法利用CNN训练得到的丰富的先验势和CRF模型的长距离相互作用,实现了多聚焦图像融合的全局或接近全局的结构化推理。建议的框架使用高效的连体结构,以支持任意数量的输入图像,可以并行处理使mf-CNNCRF计算效率很高。开发的数据集包括干净的训练图像和训练图像与高斯噪声,盐和胡椒噪声和泊松噪声。实验结果表明,所提出的MF-CNNCRF方法在定性和定量评价高斯噪声、盐分噪声和泊松噪声图像方面均优于现有的MFIF方法,具有较高的泛化能力。需要注意的是,该算法不需要噪声类型或统计信息的知识。据我们所知,这是第一个使用CNN架构来学习丰富的CRF先验的工作。我们未来的工作将专注于优化UnaryNet和SmoothnessNet的网络架构,并使用基于深度学习的网络替换a-expansion算法。