文章目录
- 声明
- 实现流程给你
- 主播列表页面分析
- 登录遮罩层处理
- 解析直播列表的数据
- 分页处理
- 完整的代码
声明
前面有了 selenium的基础,这里就拿虎牙直播页面来做一个实战测试,这是作为学习,测试使用,并不用作为商业用途,不刻意损害他人利益
实现流程给你
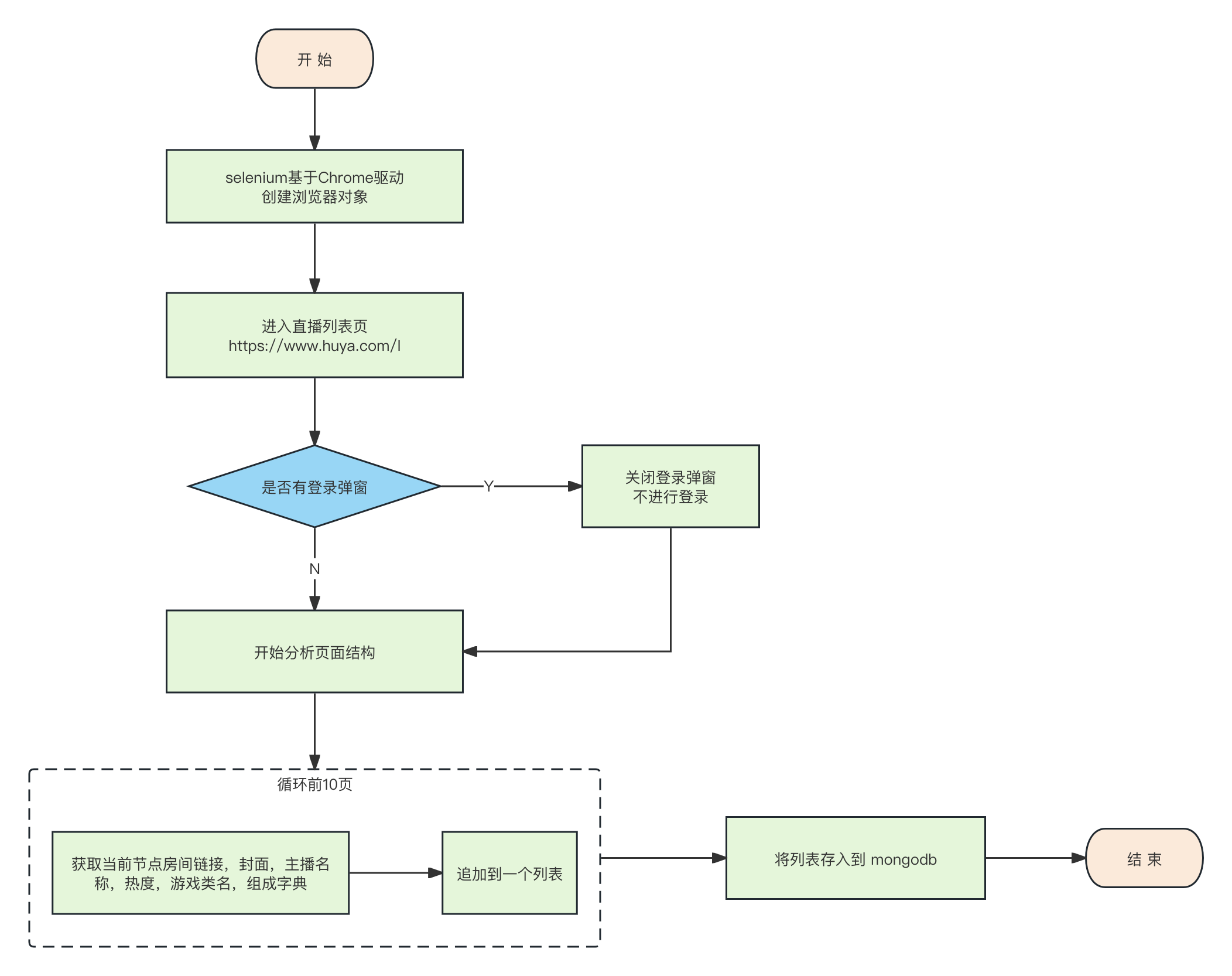
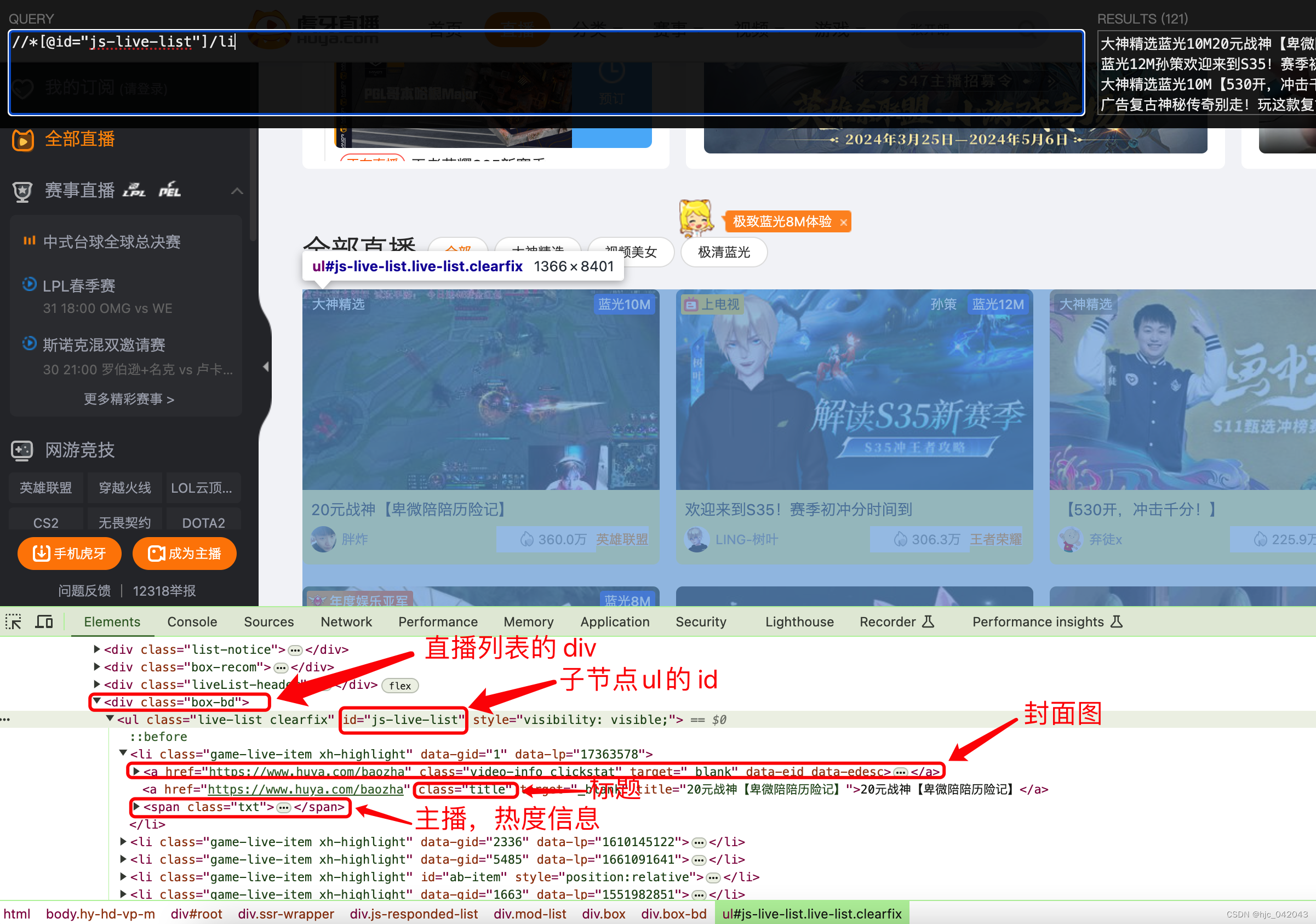
主播列表页面分析
我们需要把中间部分的列表页面内容给爬取下来,包括直播间封面,名称,主播昵称,头像,热度,游戏类别等。
从他的页面结构可以看出,其 xpath就是:
//div[@class="box-bd"]//ul[@id="js-live-list"]/li
登录遮罩层处理
从页面结构来看,登录弹窗是在一个 id="UDBSdkLgn_iframe"的iframe中,所以我们在这里在进来时候,需要先切换到 iframe中,然后将窗口关闭
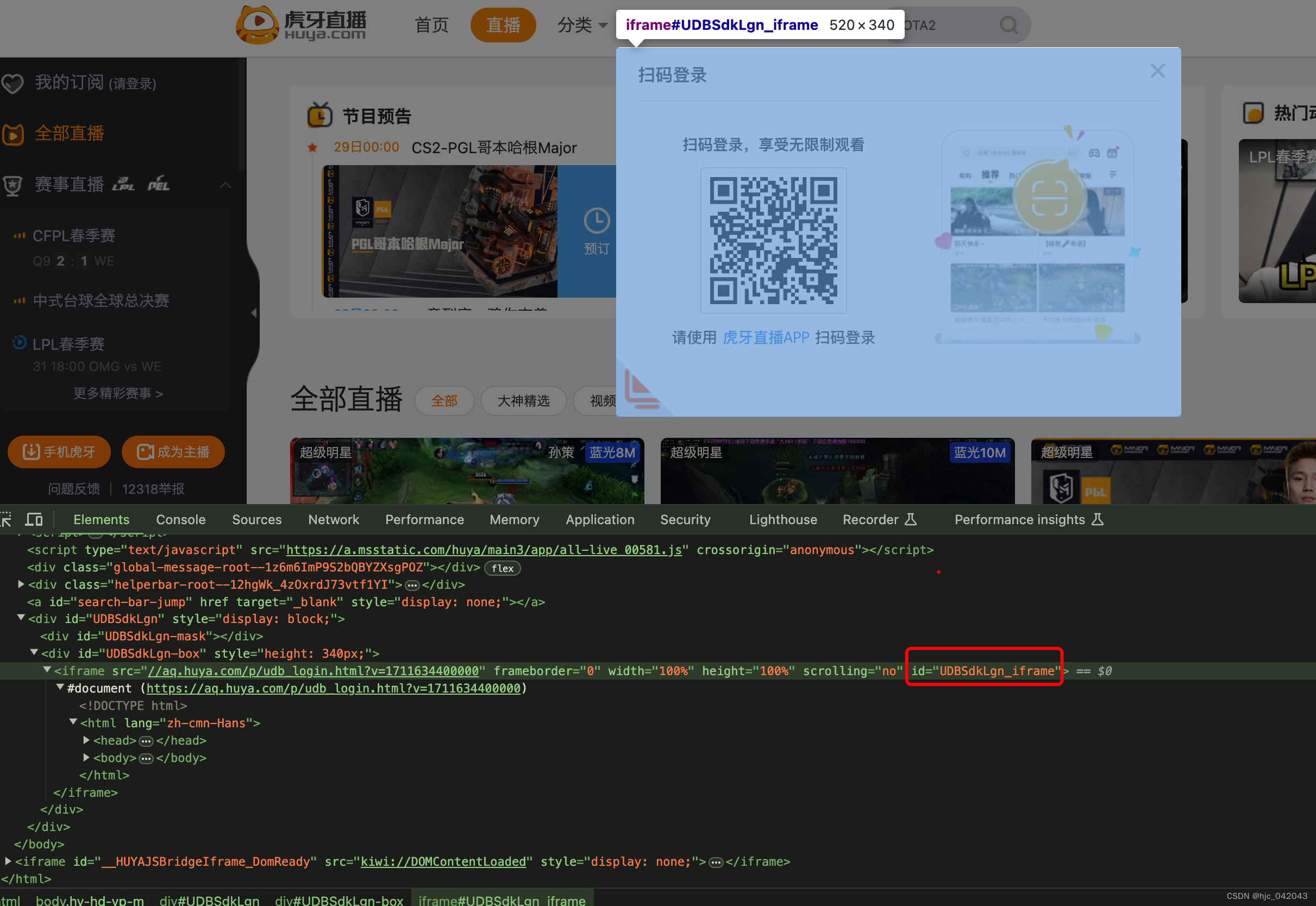
- 代码实现:
- 开启隐式等待,等待元素加载完成
- 将句柄切换到 iframe中,关闭登录弹窗
- 从 iframe中切除,回到主页面
...# 隐式等待 最大10秒self.driver.implicitly_wait(10)# 关闭登录弹窗,需要切换到弹窗的iframe中self.driver.switch_to.frame('UDBSdkLgn_iframe')self.driver.find_element(by=By.ID, value="close-udbLogin").click()# 从弹窗的iframe中切换回主页面self.driver.switch_to.default_content()
...
解析直播列表的数据
根据 xpath 分析出各个元素的内容,在这里封装了一个函数,在每一页去拉取时调用它,代码如下:
def parse(self):"""解析虎牙直播的数据@param data_list:属于引用数据@return:"""list_data = []room_list = self.driver.find_elements(by=By.XPATH, value='//div[@class="box-bd"]//ul[@id="js-live-list"]/li')for elem in room_list:# 获取每个直播间的 链接,封面,直播间名字,主播名称,热度,游戏类名组成字典tmp_dic = {}# 直播间链接tmp_dic['link'] = elem.find_element(by=By.XPATH, value='./a[1]').get_attribute('href')# 直播间封面tmp_dic['cover'] = elem.find_element(by=By.XPATH, value='./a[1]/img').get_attribute('src')# 直播间名字tmp_dic['name'] = elem.find_element(by=By.XPATH, value='./a[2]').text# 主播头像tmp_dic['user-cover'] = elem.find_element(by=By.XPATH,value='./span[@class="txt"]/span[1]/img').get_attribute('src')# 主播昵称tmp_dic['user-name'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[1]/i').text# 游戏名称tmp_dic['game-name'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[2]/a').texttmp_dic['hot'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[3]/i[2]').textlist_data.append(tmp_dic)passreturn list_data
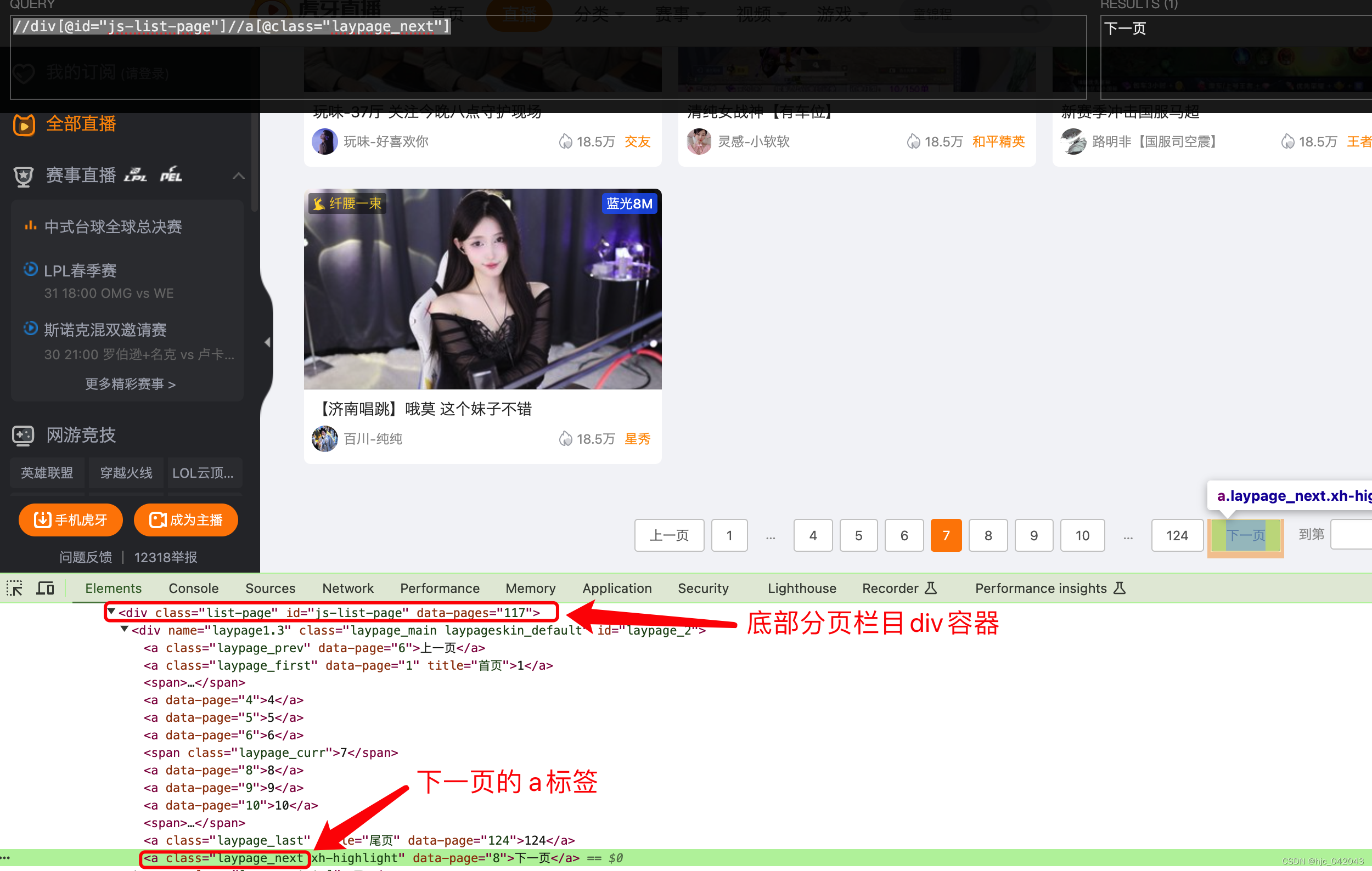
分页处理
因为分页结构在最下面,所以需要来用 js做一个页面滚动,滚动时,水平方向不用变,垂直放下往下滚动到最下面就行
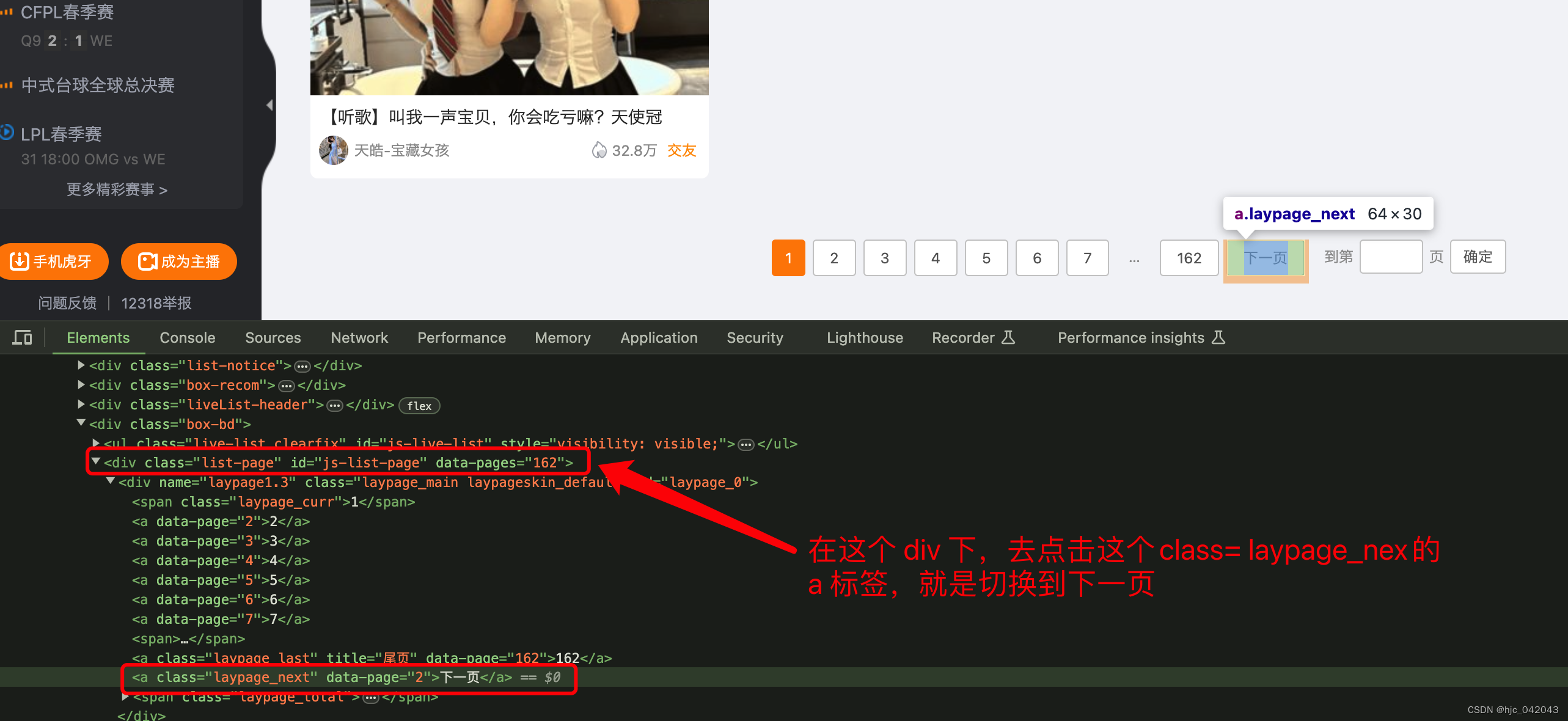
- 代码片段:
# 滚动到底部
self.driver.execute_script("window.scrollTo(0, 10000);")
self.driver.find_element(by=By.XPATH,value='//div[@id="js-list-page"]//a[@class="laypage_next"]').click()
完整的代码
我在这里是爬取前10页,所以在在解析和分页的外面套了一层循环,再每一页分析完成,入库到 mongodb中,具体看如下完整代码:
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromService
from selenium.webdriver.common.by import Byfrom db.mongo_pool import MongoPoolclass GetHuyaDatas(object):def __init__(self):self.url = 'https://www.huya.com/l'# 显示设置驱动的路径,这是 selenium4之后的新写法,主要是为了解决 selenium打开浏览器慢的问题service = ChromService(executable_path="/usr/local/bin/chromedriver")self.driver = webdriver.Chrome(service=service)passdef run(self):self.driver.get(self.url)# 关闭登录弹窗try:# 隐式等待 最大10秒self.driver.implicitly_wait(10)# 关闭登录弹窗,需要切换到弹窗的iframe中self.driver.switch_to.frame('UDBSdkLgn_iframe')self.driver.find_element(by=By.ID, value="close-udbLogin").click()# 从弹窗的iframe中切换回主页面self.driver.switch_to.default_content()except Exception as e:print(e)pass# 隐式等待 最大10秒,等待ajax请求完成self.driver.implicitly_wait(10)# 遍历10页for i in range(0, 10):# 解析data_list = self.parse()self.save_data(data_list)# 点击下一页,获取新的页面内容try:# 滚动到底部self.driver.execute_script("window.scrollTo(0, 10000);")self.driver.find_element(by=By.XPATH,value='//div[@id="js-list-page"]//a[@class="laypage_next"]').click()except:print('已经到最后一页了')passtime.sleep(10)self.driver.quit()passdef save_data(self, data_list):"""保存数据到mongodb@param data_list:@return:"""res = MongoPool().test.huya.insert_many(data_list)print(res.inserted_ids)def parse(self):"""解析虎牙直播的数据@param data_list:属于引用数据@return:"""list_data = []room_list = self.driver.find_elements(by=By.XPATH, value='//div[@class="box-bd"]//ul[@id="js-live-list"]/li')for elem in room_list:# 获取每个直播间的 链接,封面,直播间名字,主播名称,热度,游戏类名组成字典tmp_dic = {}# 直播间链接tmp_dic['link'] = elem.find_element(by=By.XPATH, value='./a[1]').get_attribute('href')# 直播间封面tmp_dic['cover'] = elem.find_element(by=By.XPATH, value='./a[1]/img').get_attribute('src')# 直播间名字tmp_dic['name'] = elem.find_element(by=By.XPATH, value='./a[2]').text# 主播头像tmp_dic['user-cover'] = elem.find_element(by=By.XPATH,value='./span[@class="txt"]/span[1]/img').get_attribute('src')# 主播昵称tmp_dic['user-name'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[1]/i').text# 游戏名称tmp_dic['game-name'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[2]/a').texttmp_dic['hot'] = elem.find_element(by=By.XPATH, value='./span[@class="txt"]/span[3]/i[2]').textlist_data.append(tmp_dic)passreturn list_datapass
- 调用:
if __name__ == '__main__':huya = GetHuyaDatas()huya.run()