『 近期,日本大模型公司sakana.ai(正是“Transformer八子”之一所创办的公司),把Huggingface上的现成模型拿来“攒一攒”—— 直接就组合出新的强大模型? ! 』 想出这么 一个进化合并模型的妙招,也是开启了AI模型开发的新时代。
当前的大语言模型开发方法虽然有效,但成本很高,需要大量的计算资源和训练数据。这一现状对于资源有限的研究机构和企业来说,无疑面临巨大的挑战。然而,随着技术的进步,模型合并技术的出现为我们提供了一种新的解决方案。模型合并技术可以利用现有的开源模型,通过巧妙的组合来创造出性能更强的新模型,而无需从头训练,非常高效!
模型合并将是高效创新的新途径?!
模型合并技术的概念可以追溯到20世纪90年代的"模型汤"(model soup)方法,即通过对同一基础模型的不同微调版本的参数取平均,可以得到泛化能力更强的模型。这种方法在图像领域,尤其是近年来在扩散模型(diffusion models)中得到了广泛应用,并取得了很好的效果。但是,目前的模型合并还主要依赖人工设计的"配方",就像炼金术一样,需要模型制作者的经验和直觉。近日,日本大模型公司sakana.ai发表了一篇文章:《Evolutionary Optimization of Model Merging Recipes》提出了进化合并模型的妙招,提出用进化算法来自动搜索最优的模型组合方案,可以极大地拓展模型合并的空间,发掘出人工难以设计的新型架构。
具体来讲,这篇论文提出了一种"智能炼金术",它利用进化算法来自动搜索最佳的模型组合方案。这就像是让计算机当炼金术士,在浩瀚的模型海洋中寻找最佳配方。进化算法模仿了自然界的进化规律,通过不断的"变异"和"选择",优胜劣汰,最终得到最适应环境的个体。在这里,"个体"就是一个模型组合方案,"环境"就是我们希望模型能够解决的任务。通过这种自动化的搜索,我们可以发现人工难以设计的新型架构,就像在炼金实验中发现了新的"魔法药水"配方一样,带来意想不到的惊喜。
模型参数与层重组:实现新配方的关键
实现这种新的配方,主要从模型参数融合、不同模型的层重组两个方面入手,参数融合就是将不同模型的参数按照一定的规则合并,形成新的参数集。这需要我们深入理解每个参数的作用,设计巧妙的融合策略,既要避免信息的损失,又要最大限度地发挥每个参数的长处。而模型层重组则是在模型架构层面进行的创新,它允许我们打破原有模型的层次结构,自由地组合不同模型的模块,创造出新的模型架构。这种重组不仅能带来性能的提升,还能实现跨领域的能力融合。比如,将一个语言模型的编码器和一个图像模型的解码器组合,可能就能得到一个能够根据文字描述生成图像的新模型。
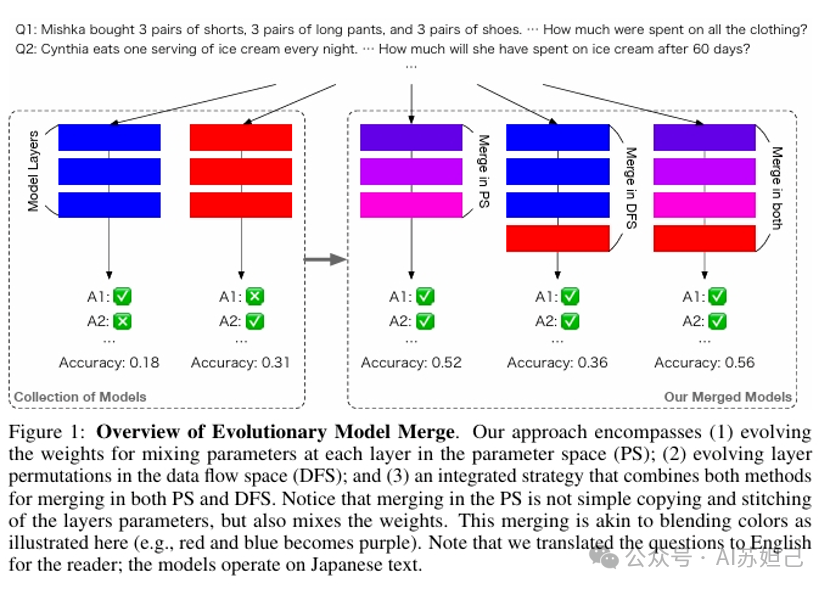
首先,关于模型参数,论文利用了一种叫做"任务向量"的技术。具体来说,它们将一个预训练模型和一个针对特定任务微调后的模型的参数做差,得到一个表示该任务的向量。这个向量可以看作是完成该任务所需的参数调整,反映了不同参数对该任务的重要性。通过对多个任务向量进行分析,研究者可以识别出不同参数在不同任务中的作用模式。一些参数可能在多个任务中都有重要作用,而另一些参数可能只在特定任务中起关键作用。这种分析有助于在合并模型时更加精细地控制参数的融合,让每个任务都能发挥所需的参数的作用。
其次,关于模型层的作用,论文中用到了一种叫做"Frankenmerging"的技术。这里的"层"更准确地说应该是"模块"或"子网络",指的是模型架构中相对独立的一些部分,如Transformer模型中的注意力层、前馈层等。Frankenmerging允许研究者将不同模型的模块拼接组合,形成新的模型架构。通过分析不同组合方式下模型的性能,研究者可以推断不同模块在处理不同任务时的作用。比如,如果用一个语言模型的编码器替换一个视觉模型的编码器,新模型在视觉语言任务上的表现提升了,那么可以推断语言模型的编码器可能更擅长处理跨模态的信息交互。
为了更系统地探索模块组合空间,论文利用进化算法自动搜索最优的组合方式。在进化过程中,不同的模块组合被看作是不同的"物种",它们在不同任务上的表现决定了它们的"适应度",适应度高的物种会被保留并产生新的变异,适应度低的物种则会被淘汰。这种自动化的搜索过程可以发现人工难以设计的模块组合,揭示出不同模块在不同任务中的作用模式。
模型合并的成功案例
文中介绍了两个通过组合模型方法开发的新模型:EvoLLM-JP和EvoVLM-JP,EvoLLM-JP结合了非英语语言处理和数学推理的能力,而EvoVLM-JP则结合了非英语语言理解和视觉处理的能力,并且在多个基准测试中展现出了先进的性能,尽管参数数量相对较少(7B),EvoLLM-JP和EvoVLM-JP在基准数据集上的表现超越了一些参数数量更多的模型(70B),表明,通过智能的模型组合,新模型不仅能够继承原有模型的强大功能,还能在多个领域内实现更优的性能,证明了新模型能够在较少的资源投入下达到甚至超越原有大型模型的性能水平。
1、EvoLLM-JP
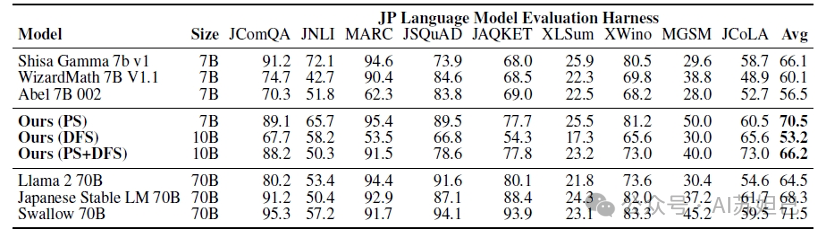
它在GSM8K数据集的多语言版本——MGSM的日语评估集上取得成绩如下:
2、EvoVLM-JP
在以下两个图像问答的基准数据集上,分数越高,代表模型用日语回答的描述越准确。

自动化模型合并的未来展望
这个新的大模型开发思路,可以让我们在相对较少的资源投入下,快速探索和迭代新模型,我们可以利用现有的模型作为"积木",在此基础上快速构建和测试新的模型架构。一旦我们通过这种低成本的探索发现了一个有前景的新模型,我们就可以针对性地加大资源投入,对这个模型进行进一步的优化和扩展。比如,我们可以在更大的数据集上对这个模型进行微调,或者增加模型的参数量和深度,以提升它的性能。这种策略可以大大降低开发新模型的成本和风险。它允许我们在投入大量资源之前,先进行广泛的探索和验证。只有当我们对一个新模型的潜力有了足够的信心,我们才会投入更多的资源来开发它。这就像是在大海捞针之前,先用一个高效的"金属探测器"扫描海底,锁定最有希望的区域。
此外,这种模型合并的方法还可以促进不同领域、不同任务之间的知识迁移和复用。通过组合不同领域的模型,我们可能发现一些意想不到的跨领域能力。这种知识的复用不仅可以提升模型的性能,还可以加速新领域的探索。
总的来说,论文提出的自动化模型合并方法为我们提供了一个高效、低成本的模型创新工具。它允许我们在广阔的模型设计空间中快速探索,发现有前景的新模型,然后再有针对性地投入资源进行深度开发。这种策略有望极大地加速人工智能的进步,让我们能够以更低的成本、更快的速度创造出更加强大和通用的AI模型。