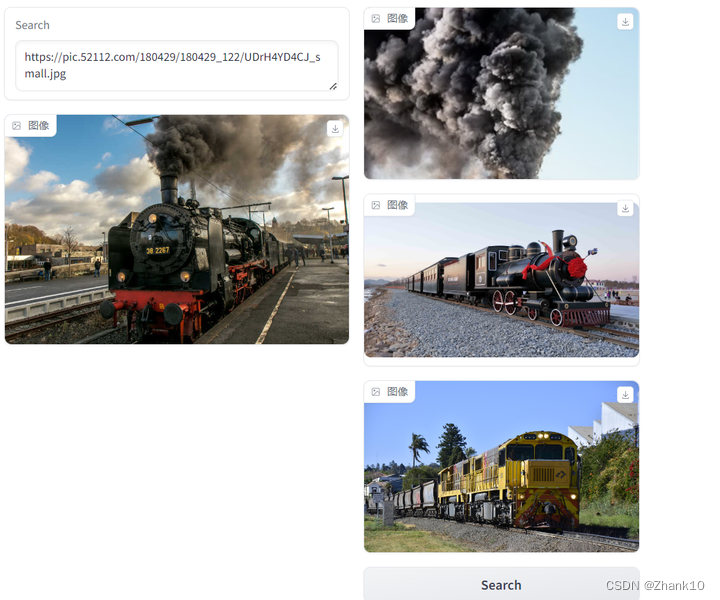
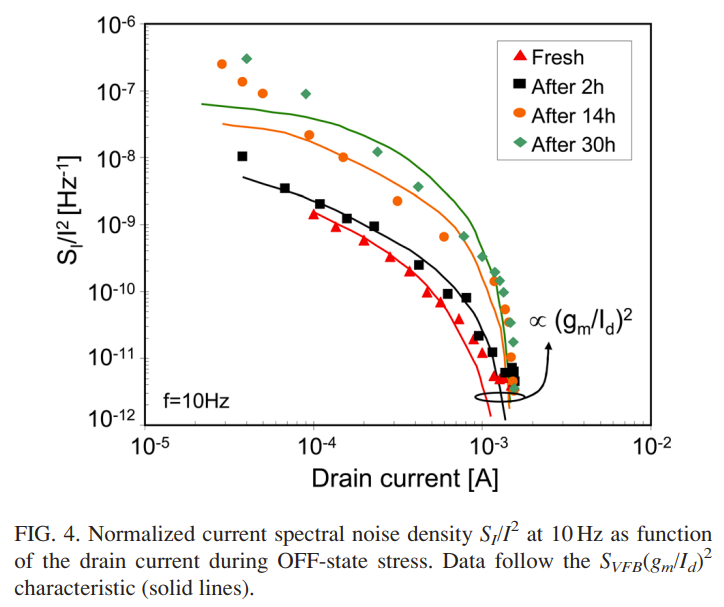
本文将会详细介绍如何使用多模态模型——LLaVA模型来实现以文搜图和以图搜图的功能。本文仅为示例Demo,并不能代表实际的以文搜图和以图搜图的技术实现方案。
1、实现原理
- 使用多模态模型获取图片的标题和详细描述
- 以文搜图功能:使用ES实现查询匹配,找到相似的图片描述,从而获得对应图片。
- 以图搜图功能:对于查询图片,根据其图片描述,在ES查询得到详细的图片描述;再对这些查询得到的图片描述使用Rerank模型进行匹配,调整顺序,从而获得对应图片
2、使用模型
- 多模态模型:LLaVA-1.5-7B,主要用于图片理解,本文的使用场景为获取图片标题和图片内容描述。
- OCR模型:PaddleOCR,主要用于图片中的文字识别。
- ReRank模型:ReRank模型,主要用于文本匹配,本文的使用场景为匹配两张图片的内容描述。
2.1、下面将按功能进行阐述,主要分为以下三部分:
- 图片上传
- 以文搜图
- 以图搜图
3、前期准备
3.1、基于LLaVa大模型的图片理解
参考:https://blog.csdn.net/zhanghan11366/article/details/136763065?spm=1001.2014.3001.5501
3.2、基于PaddleOCR文字识别
模型介绍及部署方法: https://www.paddlepaddle.org.cn/hubdetail?name=ch_pp-ocrv3&en_category=TextRecognition
3.2.1、安装
1、环境依赖
paddlepaddle >= 2.2
paddlehub >= 2.2
2、安装
hub install ch_pp-ocrv3
3.2.2、服务部署
PaddleHub Serving 可以部署一个目标检测的在线服务。
第一步:启动PaddleHub Serving
运行启动命令: hub serving start -m ch_pp-ocrv3
这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
NOTE:如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
第二步:发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果。
import requests
import json
import cv2
import base64def cv2_to_base64(image):data = cv2.imencode('.jpg', image)[1]return base64.b64encode(data.tostring()).decode('utf8')# 发送HTTP请求
data = {'images': [cv2_to_base64(cv2.imread(r"C:\Users\zh\Desktop\1.jpg"))]}
headers = {"Content-type": "application/json"}
url = "http://0.0.0.0:8866/predict/ch_pp-ocrv3"
r = requests.post(url=url, headers=headers, data=json.dumps(data))# 打印预测结果
print(r.json()["results"])
结果如下:
[{'data': [{'confidence': 0.9090811014175415, 'text': '2023年A1大模型应用研究报告', 'text_box_position': [[102, 90], [780, 90], [780, 127], [102, 127]]}, {'confidence': 0.9284242391586304, 'text': 'AI、AGI、大模型、通用大模型、行业大模型', 'text_box_position': [[215, 207], [670, 207], [670, 227], [215, 227]]}], 'save_path': ''}]
3.3、es部署与测试
3.3.1、es部署
docker load < es.tar####便于添加用户和密码
chmod 644 /.../elasticsearch.yml
chmod 644 /.../kibana.ymldocker run -d
-v /.../elasticsearch.yml:/home/elasticsearch/elasticsearch-7.16.2/config/elasticsearch.yml
-v /.../kibana.yml:/home/elasticsearch/kibana-7.16.2-linux-x86_64/config/kibana.yml
-p 9200:9200 -p 5601:5601 --name elasticKibana nshou/elasticsearch-kibanadocker ps --format "table {{.ID}}\t{{.Names}}\t{{.Image}}\t{{.RunningFor}}\t{{.Status}}\t{{.Ports}}" | head -n 11
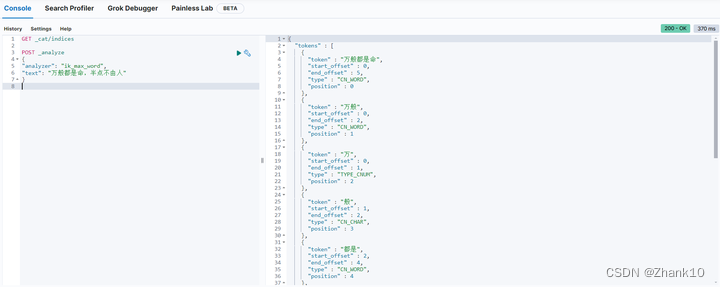
3.3.2、按照ik_smart分词器
下载网址:https://github.com/infinilabs/analysis-ik/releases?page=2
下载解压之后,把文件名修改为ik放到plugins文件夹下:
docker cp /.../ik elasticKibana:/home/elasticsearch/elasticsearch-7.16.2/pluginsdocker restart elasticKibana
测试如下:
3.4、基于ReRank模型的文本匹配
模型下载:https://huggingface.co/maidalun1020/bce-reranker-base_v1
服务:
# -*- coding: utf-8 -*-
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
from operator import itemgetter
from sentence_transformers import CrossEncoderapp = FastAPI()
# init rerank model
model_path = './model/bce-reranker-base_v1'
model = CrossEncoder(model_path, max_length=512)class SentencePair(BaseModel):text1: strtext2: strfrom typing import Listclass Sentences(BaseModel):texts: List[SentencePair]@app.get('/')
def home():return 'hello world'@app.post('/rerank')
def get_embedding(sentence_pairs: Sentences):scores = model.predict([[pair.text1, pair.text2] for pair in sentence_pairs.texts]).tolist()result = [[scores[i], sentence_pairs.texts[i].text1, sentence_pairs.texts[i].text2] for i in range(len(scores))]sorted_result = sorted(result, key=itemgetter(0), reverse=True)return {"result": sorted_result}if __name__ == '__main__':uvicorn.run(app, host='0.0.0.0', port=50074)
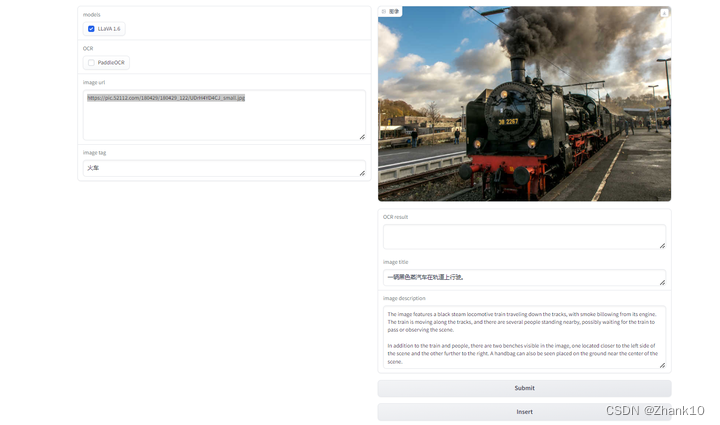
4、结果展示
4.1、图片展示
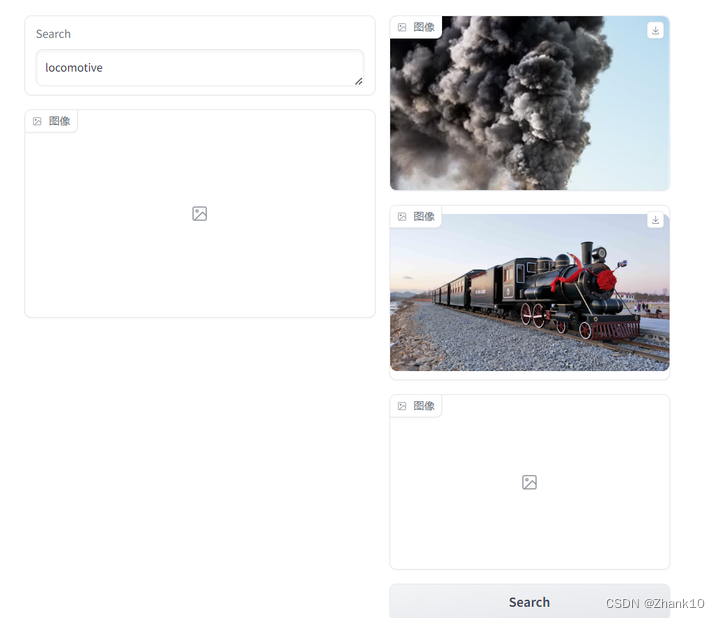
4.2、以字搜图
4.3、以图搜图