太快了太快了…
大模型的生成技能,已经到了普通人看不懂的境界!
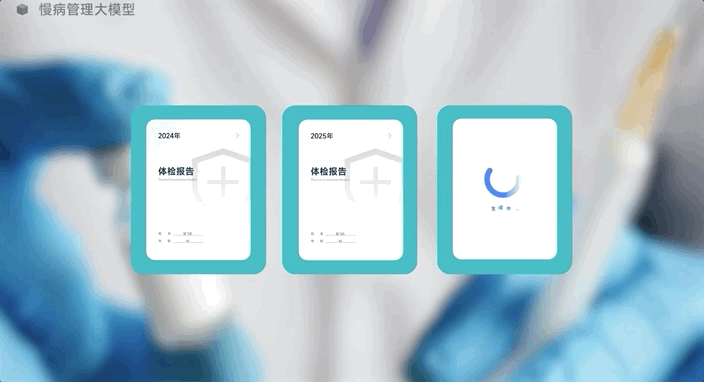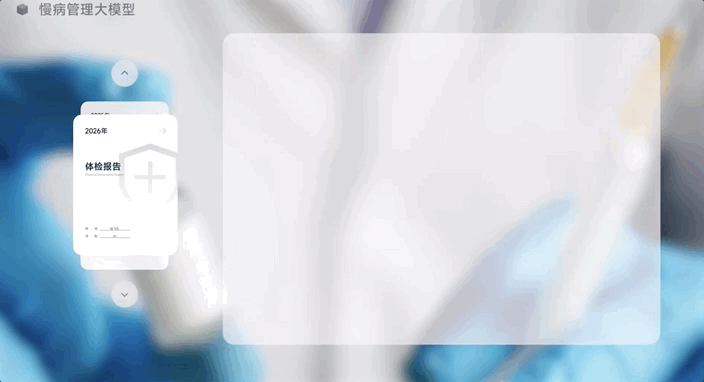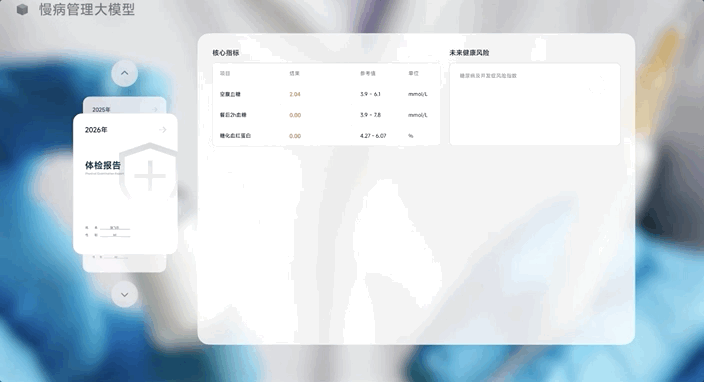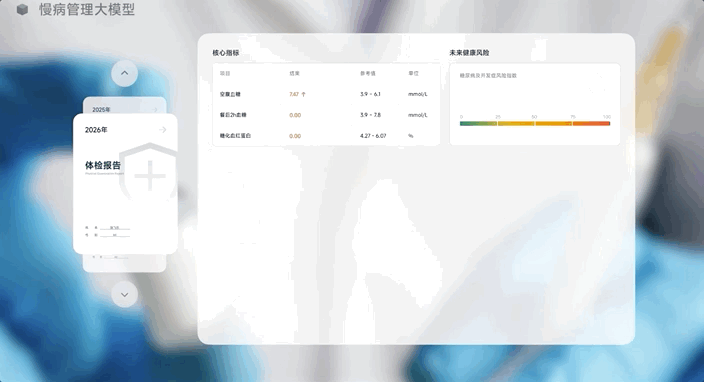
它可以根据用户过去5年的体检报告,生成未来第1年、第2年、第3年的体检报告。
你看,这个生成的过程,是不是像极了ChatGPT,根据历史单词预测下一个单词。
它能查看过去7天机组子部件的运行情况,生成未来3天每小时的子部件报告 。

还能基于历史水文数据和未来7天气象数据,生成未来第1天、第2天……至第7天的每小时降水分析报告,包括详细降水量、降水分布。

如今,大模型的生成内容,早已不只是文字/图像/视频了。
如上生成的这些报告分析涉及诸多专业知识,普通人很难基于自己的知识储备评价其合理性和正确性。
最多只能评价一句:不明觉厉!
怎么说呢?“AI似乎正在生成一切”。
LLM+行业数据,路走错了?
简单理解大模型,就是Predict the Next “X”。ChatGPT是Predict the Next “Word”。
但行业需要的往往不是预测下一个字。
比如对于慢性病患者的健康管理规划,它需要基于一系列生理指标数据,从医学角度进行数据预测。举个不恰当的例子,这更像是用数学方法解题。
如果在大语言模型基础上投喂大量专业的医学语料,更像是用语文方法读题。尽管能理解相关的术语和指标,可是给出的预测结果大概率不准确。因为问题本身超出了“语言”范畴,不能用语文方法求解。
如果“X“的模态从“文字Word”变成了“体检报告”,模型则可以根据历史体检报告数据去预测下一个体检报告,这才是一个健康管理大模型。
它的逻辑更像是“种瓜得瓜、种豆得豆”。即输入“X”、输出“X”。
这里的“X”可能包含水文数据、健康报告、设备监测数值、设计推演等不同样式的专业数据。
它能基于音乐厅的几何模型和房间数据,从声源发射5000Hz频率射线,生成射线分布图,找到听觉最佳的音源摆放位置。
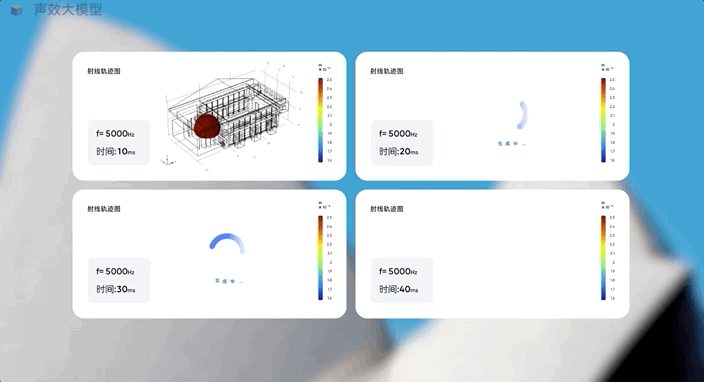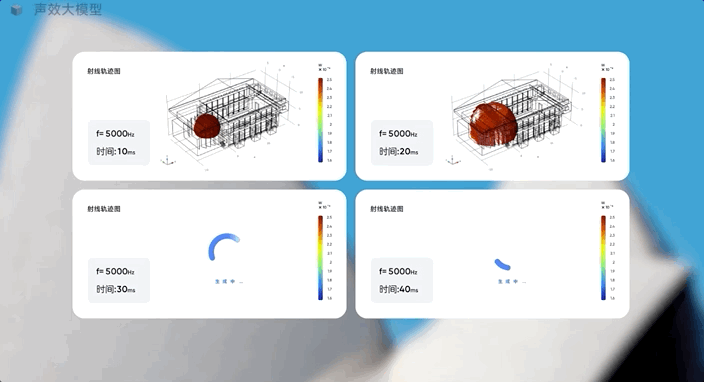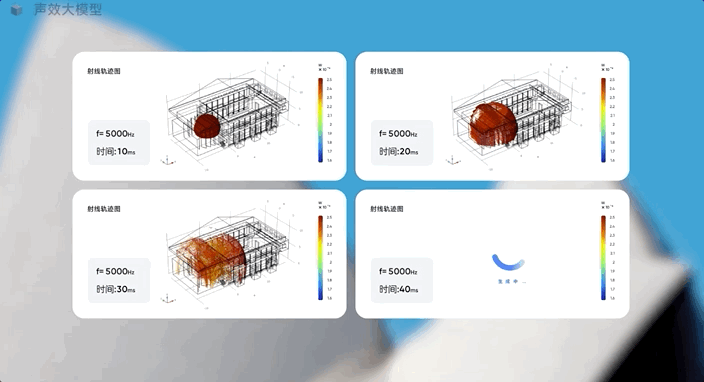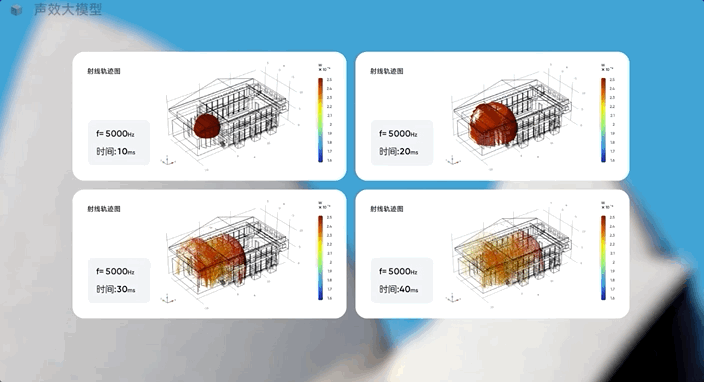
如何预测“X”?
所以,这些能预测下一个X的行业大模型,如何构建出来?
通过刚刚发布的先知AIOS 5.0。其核心特点是基于各行各业场景的X模态数据,构建行业基座大模型。
解决了当前行业大模型只能将行业文本数据喂给大语言模型、生成下一个字的问题,让大模型能来到的领域更加广泛。

先知是AI公司第四范式的核心产品。2015年,先知AIOS 1.0版本首次发布,通过高维、实时、自学习框架提升模型精度;2017年,先知AIOS 2.0版本利用自动建模工具HyperCycle,降低模型开发门槛;2020年发布的先知AIOS 3.0版本规范AI数据治理和上线投产;2022年,先知AIOS 4.0版本引入北极星指标,更大化发挥AI应用价值。
AIOS 5.0版本则从生成式AI+行业这一角度出发,给行业大模型提出了一种新思路。
而在公认的大模型应用落地元年里,行业大模型的发展和影响一定是此前的数倍。这种更具规模化的动向,由此也形成了AIGC趋势的下一个范式。
One More Thing:AIGC迈向新范式?
从图片、文字、视频,再到健康、水利……我们不难看出AIGC现在正以迅猛的速度朝着AI生成一切的方向飞奔。
通常来说,一切事物的发展似乎都需要一些范式来推动,而且不是新范式取代旧范式,而是它们之间互补使其更加深入和全面。
正如科学研究中的四种范式一般,即实验归纳、理论推演、计算机仿真和数据密集型科学发现,它们相互补充,共同推动了科学研究的进步。
那么若是以这种逻辑来看待AIGC,似乎类似的四种范式也已经开始出现。
AIGC的第一范式以文本生成为核心,通过智能客服、内容续写等应用,展示了AI在理解和生成自然语言方面的能力。这一阶段的AIGC技术,为后续的发展奠定了基础,使得机器能够与人类进行有效的交流和互动。
AIGC的第二范式将应用领域扩展到了图像生成。
如生成对抗网络(GAN)、变分自编码器(VAE)等,可以学习从随机噪声生成逼真图像的映射。并能将输出结果用于艺术创作、图像增强、虚拟场景生成等领域。这一范式进一步展现了AI的想象力。
AIGC的第三范式则是聚焦在了视频生成,例如Gen2,例如Sora。
视频生成一定程度上反映了AI对于世界的理解。从Sora诞生以来,能否理解世界?是否是世界模拟器的说法一直争论不休。因为如果确定Sora可以理解世界,将意味着AGI大门正式开启。

而AIGC的第四范式,就是以行业为主,技术将全面渗透到各个行业之中。
这一阶段的核心任务是将AI技术与行业知识深度融合。今年作为大模型应用落地的元年,我们看到AIGC技术开始在医疗、教育、金融等关键领域发挥重要作用。
具体怎么做才能更快推进AIGC扎入行业?各路玩家都还在不断尝试中。以大语言模型为底座?还是直接训练行业大模型?不同路线都有各自的底层逻辑,谁的路线更能跑通,还言之过早。
但可以确定的是——
在AI生成一切的进程中,那些能够率先利用AI技术的个人和行业,将能够更早地享受到技术带来的红利。他们将有机会引领行业变革,塑造未来的社会和经济格局。
而且也只有AIGC进入到了第四范式,才意味着完成了技术创新到商业创业的飞轮转换,意味着生成式AI开启新质生产力变革。