文章目录
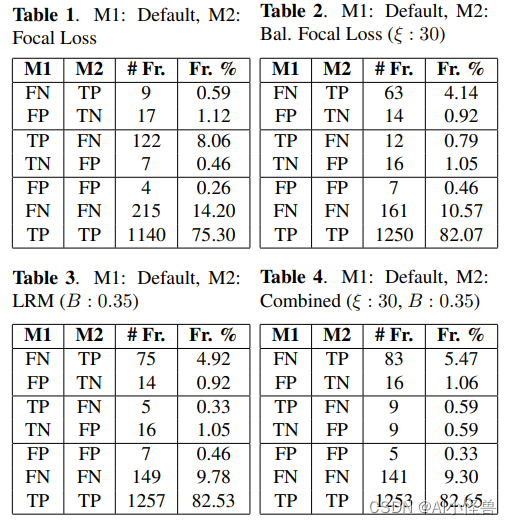
- 7. Flink组件栈
- 1. 部署层
- (1)Local模式
- (2)Cluster模式
- (3)Cloud模式
- 2.运行时
- 3.API层
- 4. 上层工具
- 8. 任务执行与资源划分
- 1. 再谈逻辑视图到物理执行图
- 2. 任务、算子子任务与算子链
- 3. Slot与计算资源
- 4. 并行度和Slot数目的概念可能容易让人混淆,这里再次阐明一下。
7. Flink组件栈
我们从更宏观的角度来对Flink的组件栈分层剖析。Flink的组件栈分为4层:部署层、运行时层、API层和上层工具。
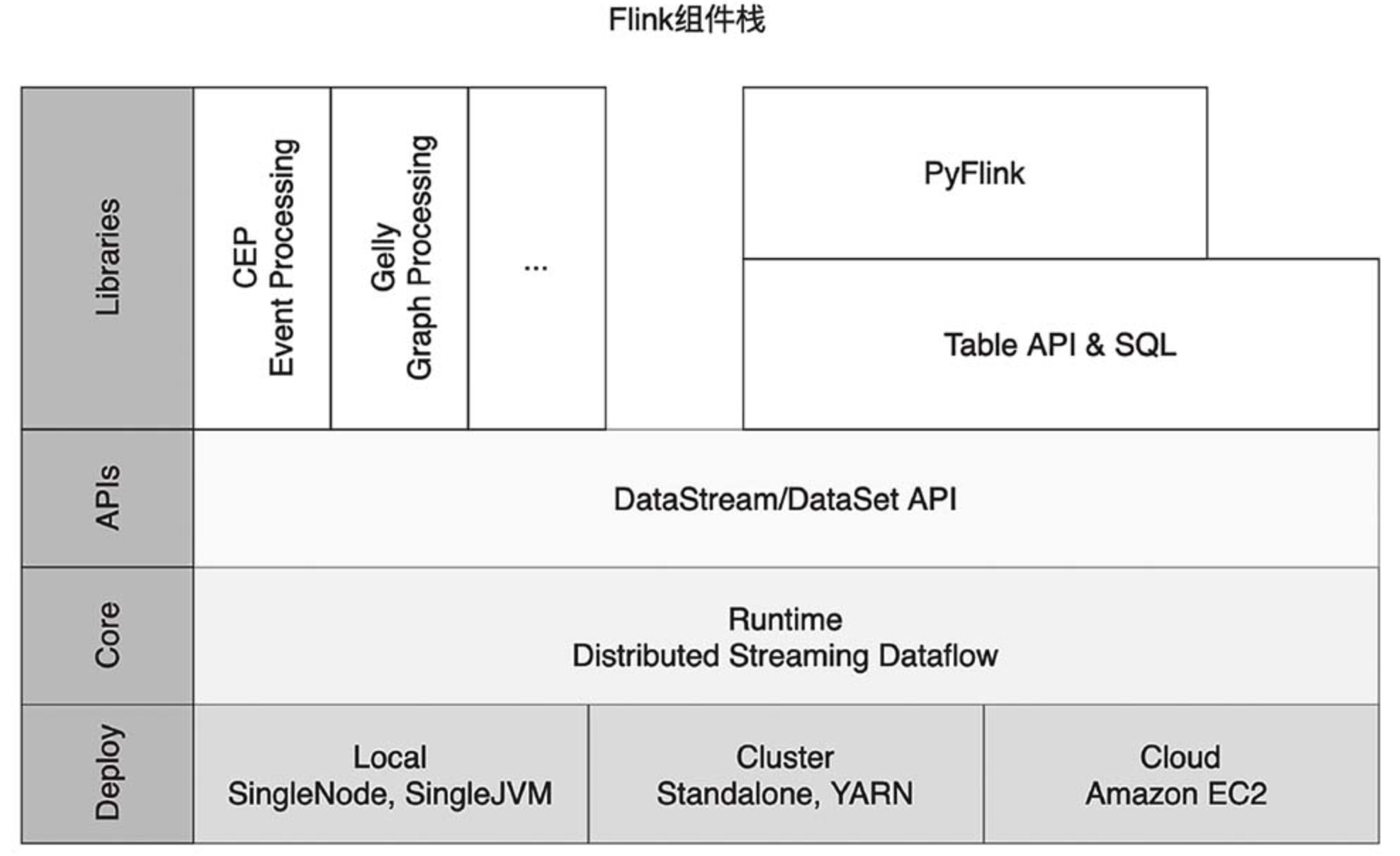
1. 部署层
Flink支持多种部署模式,可以部署在单机(Local)、集群(Cluster),以及云(Cloud)上。
(1)Local模式
Local模式有两种不同的模式,一种是单节点 (SingleNode),一种是单虚拟机 (SingleJVM)。Local-SingleJVM 模式大多是开发和测试时使用的部署方式,该模式下JobManager和TaskManager都在同一个JVM里。Local-SingleNode 模式下,JobManager 和 TaskManager 等所有角色都运行在一个节点上,虽然是按照分布式集群架构进行部署,但是集群的节点只有1个。该模式大多是在测试或者IoT设备上进行部署时使用的。
(2)Cluster模式
一般使用 Cluster 模式将 Flink 作业投入到生产环境中,生产环境可以是 Standalone 的独立集群,也可以是 YARN 或 Kubernetes 集群。
对于一个 Standalone 集群,我们需要在配置文件中配置好 JobManager 和 TaskManager 对应的节点,然后使用 Flink 主目录下的脚本启动一个 Standalone 集群。我们将在详细介绍如何部署一个 Flink Standalone 集群。Standalone 集群上只运行 Flink 作业。除了 Flink,绝大多数企业的生产环境运行包括 MapReduce、Spark 等各种各样的计算任务,一般都会使用 YARN或Kubernetes 等方式对计算资源进行管理和调度。Flink 目前已经支持了 YARN、Mesos 以及 Kubernetes,开发者提交作业的方式变得越来越简单。
(3)Cloud模式
Flink也可以部署在各大云平台上,包括AWS、谷歌云和阿里云。
2.运行时
层运行时 (Runtime) 层为Flink各类计算提供了实现。该层对分布式执行进行了支持。Flink运行时层是Flink最底层也是最核心的组件。
3.API层
API层主要实现了流处 DataStream API 和批处理 DataSet API。
:::info
目前,DataStream API 针对有界和无界数据流,DataSet API 针对有界数据集。
:::
用户可以使用这两大API进行数据处理,包括转换 (Transformation)、连接 (Join)、聚合 (Aggregation)、窗口 (Window) 以及状态 (State) 的计算。
4. 上层工具
在 DataStream 和 DataSet 两大 API 之上,Flink还提供了以下丰富的工具。
面向流处理的:复杂事件处理 (Complex Event Process,CEP)。
面向批处理的:图 (Graph Processing)Gelly 计算库。
面向SQL用户的Table API和SQL。数据被转换成了关系型数据库式的表,每个表拥有一个表模式(Schema),用户可以像操作表那样操作流数据,例如可以使用 SELECT、JOIN、GROUP BY 等操作。
针对 Python 用户推出的 PyFlink,方便 Python 用户使用 Flink。目前,PyFlink 主要基于 Table API。
8. 任务执行与资源划分
1. 再谈逻辑视图到物理执行图
:::info
逻辑视图转化为物理执行图的过程,该过程可以分成4层:StreamGraph→JobGraph→ExecutionGraph→物理执行图。
:::
我们根据下图来大致了解这些图的功能。
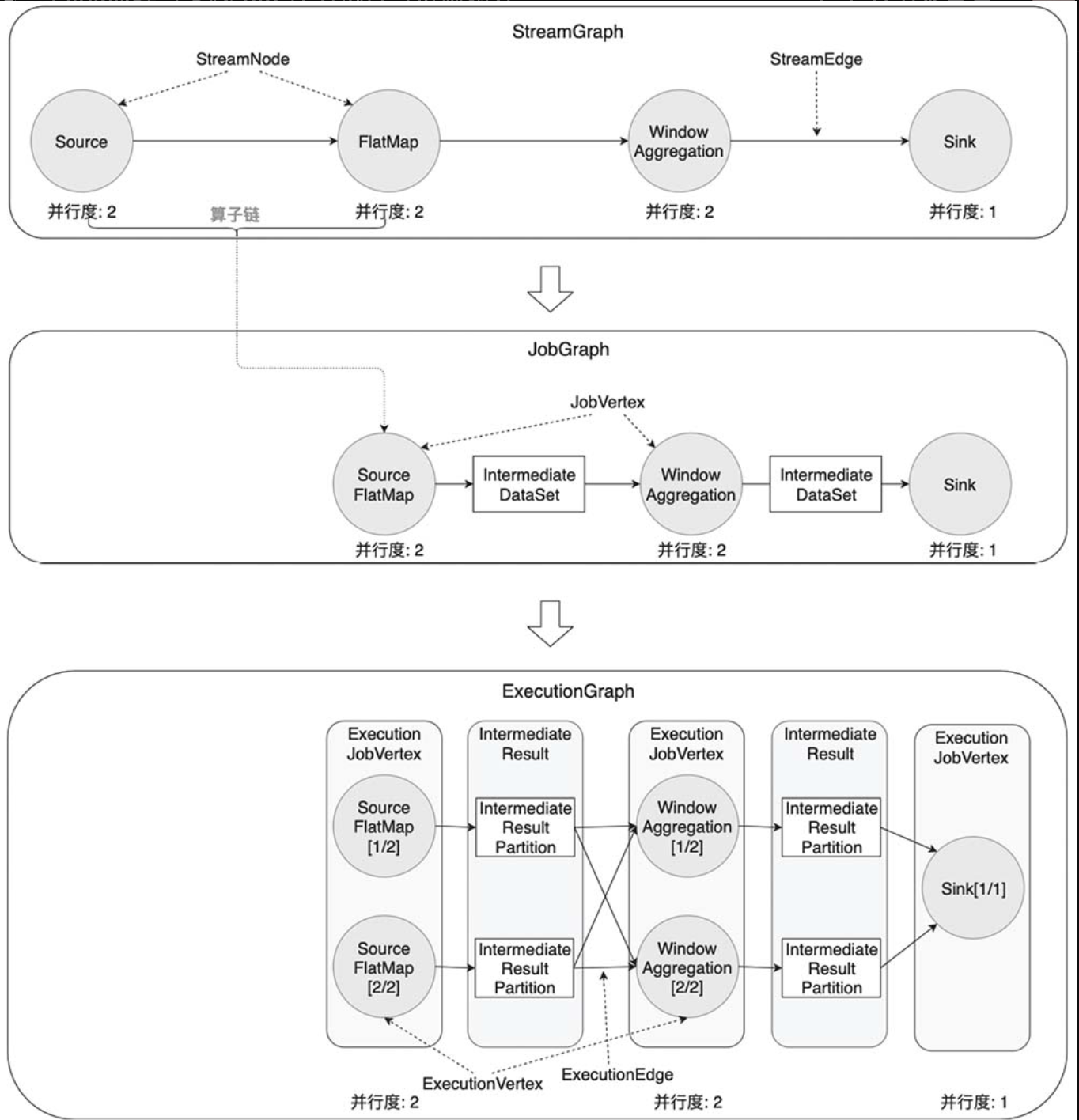
StreamGraph:根据用户编写的代码生成的最初的图,用来表示一个Flink流处理作业的拓扑结构。在StreamGraph中,节点StreamNode就是算子。JobGraph:JobGraph是被提交给JobManager的数据结构。StreamGraph经过优化后生成了JobGraph,主要的优化为,将多个符合条件的节点链接在一起作为一个JobVertex节点,这样可以减少数据交换所需要的传输开销。这个链接的过程叫算子链(Operator Chain)。JobVertex经过算子链后,会包含一到多个算子,它的输出是IntermediateDataSet,这是经过算子处理产生的数据集。ExecutionGraph:JobManager将JobGraph转化为ExecutionGraph。
ExecutionGraph是JobGraph的并行化版本:假如某个JobVertex的并行度是2,那么它将被划分为2个ExecutionVertex,ExecutionVertex表示一个算子子任务,它监控着单个子任务的执行情况。每个ExecutionVertex会输出一个IntermediateResultPartition,这是单个子任务的输出,再经过ExecutionEdge输出到下游节点。ExecutionJobVertex是这些并行子任务的合集,它监控着整个算子的执行情况。
:::info
ExecutionGraph 是调度层非常核心的数据结构。
:::
- 物理执行图:
JobManager根据ExecutionGraph对作业进行调度后,在各个TaskManager上部署具体的任务,物理执行图并不是一个具体的数据结构。
:::info
可以看到,Flink在数据流图上可谓煞费苦心,仅各类图就有4种之多。对于新人来说,可以不用太关心这些非常细节的底层实现,只需要了解以下两点。
- Flink采用主从架构,Master起着管理协调作用,TaskManager负责物理执行,在执行过程中会发生一些如数据交换、生命周期管理等事情。
- 用户调用Flink API,构造逻辑视图,Flink会对逻辑视图优化,并转化为并行化的物理执行图,最后被执行的是物理执行图。
:::
2. 任务、算子子任务与算子链
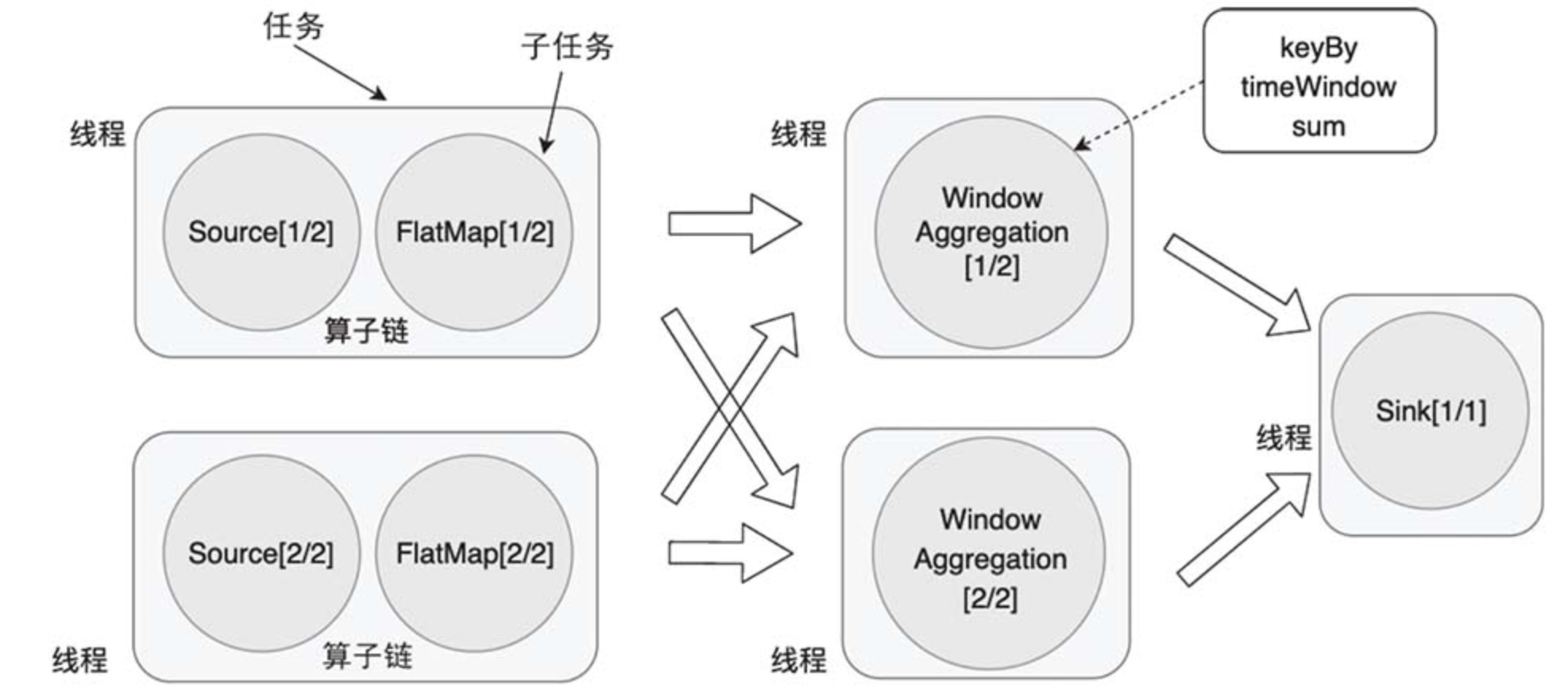
在构造物理执行图的过程中,Flink会将一些算子子任务链接在一起,组成算子链。链接后以任务(Task)的形式被TaskManager调度执行。使用算子链是一个非常有效的优化,它可以有效减少算子子任务之间的传输开销。链接之后形成的任务是TaskManager中的一个线程。
:::info
如图所示,展示了任务、子任务和算子链之间的关系。
:::
例如,数据从 Source 前向传播到 FlatMap,这中间没有发生跨分区的数据交换,因此,我们完全可以将 Source、FlatMap 这两个子任务组合在一起,形成一个任务。
数据经过 keyBy() 发生了数据交换,数据会跨越分区,因此无法将 keyBy() 以及其后面的窗口聚合、链接到一起。
由于 WindowAggregation 的并行度为2、Sink 的并行度为1,数据再次发生了交换,我们不能把 WindowAggregation 和 Sink 两部分链接到一起。Sink的并行度被人为设置为1,如果我们把Sink的并行度也设置为2,那么是可以让这两个算子链接到一起的。
默认情况下,Flink会尽量将更多的子任务链接在一起,这样能减少一些不必要的数据传输开销。但一个子任务有超过一个输入或发生数据交换时,链接就无法建立。两个算子能够链接到一起是有一些规则的,感兴趣的读者可以阅读 Flink 源码中 org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator 中的 isChainable() 方法。StreamingJobGraphGenerator 类的作用是将 StreamGraph 转换为 JobGraph。
尽管将算子链接到一起会减少一些传输开销,但是也有一些情况并不需要太多链接。比如,有时候我们需要将一个非常长的算子链拆开,这样我们就可以将原来集中在一个线程中的计算拆分到多个线程中来并行计算。Flink允许开发者手动配置是否启用算子链,或者对哪些算子使用算子链。
3. Slot与计算资源
- slot
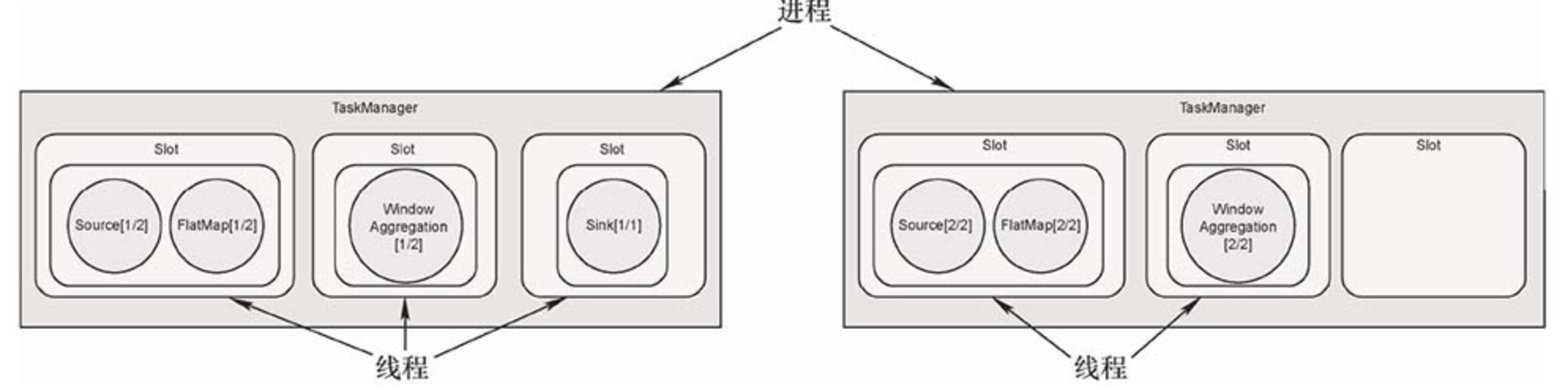
TaskManager 是一个 JVM 进程,在 TaskManager 中可以并行执行一到多个任务。每个任务是一个线程,需要 TaskManager 为其分配相应的资源,TaskManager 使用 Slot 给任务分配资源。
Flink 的 Slot 分配机制上,一个 TaskManager 是一个进程,TaskManager 可以管理一至多个任务,每个任务是一个线程,占用一个 Slot。每个 Slot 的资源是整个 TaskManager 资源的子集,如上图所示的 TaskManager 下有3个 Slot,每个 Slot 占用 TaskManager 1/3 的内存,第一个 Slot 中的任务不会与第二 个 Slot 中的任务互相争抢内存资源。
:::info
注意,在分配资源时,Flink并没有将CPU资源明确分配给各个Slot。
:::
Flink允许用户设置TaskManager中Slot的数目,这样用户就可以确定以怎样的粒度将任务做相互隔离。如果每个TaskManager只包含一个Slot,那么该Slot内的任务将独享JVM。如果TaskManager包含多个Slot,那么多个Slot内的任务可以共享JVM资源,比如共享TCP连接、心跳信息、部分数据结构等。官方建议将Slot数目设置为TaskManager下可用的CPU核心数,那么平均下来,每个Slot都能获得1个CPU核心。
- 槽位共享
默认情况下,Flink还提供了一种槽位共享 (Slot Sharing) 的优化机制,进一步减少数据传输开销,充分利用计算资源。将上图所示的任务做槽位共享优化后,结果如下图所示。
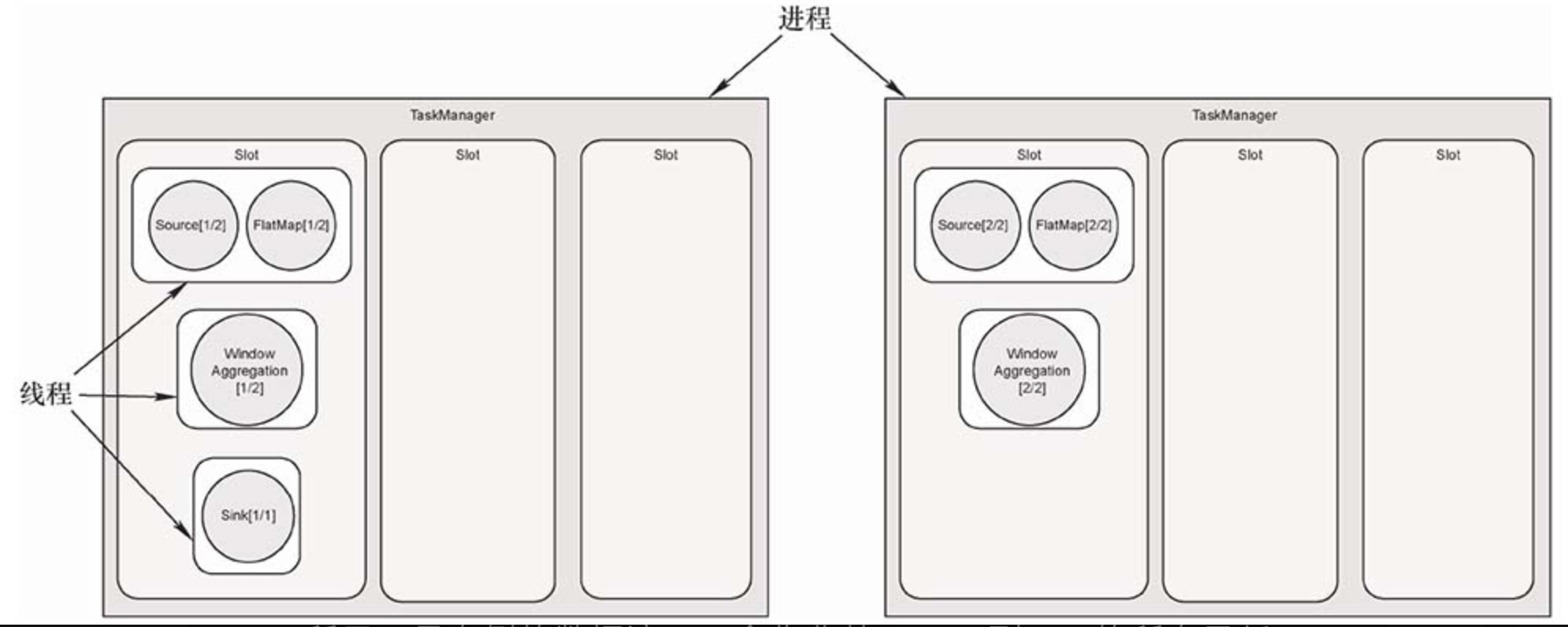
开启槽位共享后,Flink允许多个任务共享一个Slot。如图所示,最左侧的数据流,一个作业从Source到Sink的所有子任务都可以放置在一个Slot中,这样数据交换成本更低。而且,对于一个数据流图来说,Source、FlatMap等算子的计算量相对不大,WindowAggregation算子的计算量比较大,计算量较大的算子子任务与计算量较小的算子子任务可以互补,空出更多的槽位,分配给更多任务,这样可以更好地利用资源。如果不开启槽位共享,计算量小的Source、FlatMap算子子任务独占槽位,造成一定的资源浪费。
:::info
综上,Flink的一个Slot中可以执行一个算子子任务、也可以是被链接的多个子任务组成的任务,或者是共享Slot的多个任务,具体这个Slot上执行哪些计算由算子链和槽位共享两个优化措施决定。我们将在9.3节再次讨论算子链和槽位共享这两个优化选项。
:::
4. 并行度和Slot数目的概念可能容易让人混淆,这里再次阐明一下。
用户使用Flink提供的API算子可以构建一个逻辑视图,需要将任务并行才能被物理执行。一个算子将被切分为多个子任务,每个子任务处理整个作业输入数据的一部分。如果输入数据过大,增大并行度可以让算子切分为更多的子任务,加快数据处理速度。可见,并行度是Flink对任务并行切分的一种描述。Slot数目是在资源设置时,对单个TaskManager的资源切分粒度。