文章目录
- PyTorch 项目分析
- 1.背景
- 2.分析流程
PyTorch 项目分析
1.背景
当我们拿到一个 PyTorch 的深度学习项目时,应该怎么入手?怎么去查看代码?
2.分析流程
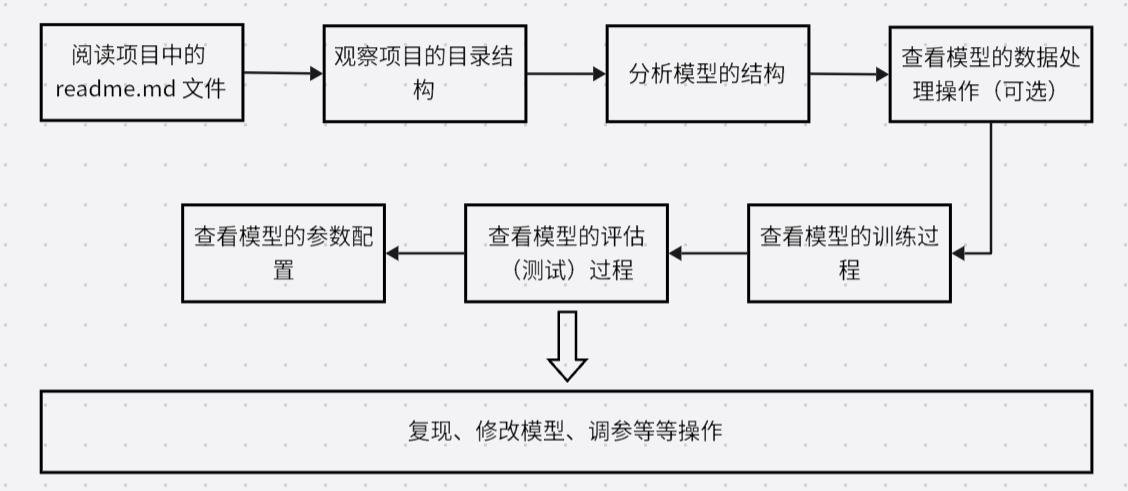
- 首先阅读对应项目的
README.md文件。通过阅读README.md,一般可以轻松的搭建起项目所需的环境(如果给了requirements.txt文件,直接导入就行),并且知道一些关于该项目的必要内容。 - 通过观察项目中文件、文件夹的命名,对每个文件的功能有一个初步的判断。一个典型的深度学习项目可能包含以下几个关键部分:
- 数据预处理(Data Preprocessing):
通常包含数据加载、清洗、标准化、增强等对数据集的操作。文件可能命名为data_utils.py、preprocess.py、data_loader.py等。通常在datasets文件夹下面。- 模型定义(Model Definition):
包含模型架构的定义,通常是神经网络的层和结构。相关文件可能命名为model.py、network.py、architecture.py等。通常在models文件夹下面。- 训练和测试(Training and Test):
有关训练的代码一般包含模型的训练过程,包括前向传播、损失计算、反向传播和优化器的使用。文件可能命名为train.py、trainer.py等。测试代码用于计算验证集或测试集上的性能指标。文件可能命名为evaluate.py、test.py、eval.py等。通常在scripts文件夹下面。- 超参数配置(Hyperparameter Configuration):
用于存储和配置模型训练所需的超参数。文件可能命名为config.py、params.py、defaults.py、ops.py等。通常在config文件夹下面。- 实用工具(Utility Functions):
提供项目中使用的辅助函数和工具,如日志记录、计时、检查点保存等。文件可能命名为utils.py、helpers.py、logger.py等。通常在utils文件夹下面。- 主脚本(Main Script):
是项目的主要执行脚本,用于整合上述各个部分并启动训练或测试流程。通常命名为main.py、run.py、app.py。- 测试脚本(Testing Scripts):
用于对模型进行额外的测试,可能包含一些单独的测试案例。文件可能命名为test_models.py。- 模型保存和加载(Model Saving and Loading):
包含模型权重的保存和加载代码。文件可能命名为save_load.py、checkpoint.py等。通常在checkpoint文件夹下面。
- 分析模型的结构。找到项目中定义模型的文件,通常是
model.py或者类似的名字。了解模型的架构、网络层的结构以及各个部分的作用。理解模型的定义对于后续的分析和修改非常重要!!! - 查看模型的数据处理操作(可选)。例如查看
dataset.py文件,了解数据是如何加载、预处理、增强以及转换成模型可接受的格式的。数据处理对于模型训练和评估是很重要的,需要确保数据的格式符合模型的需求。 - 查看模型的训练过程。查看项目中的
train.py,知道模型是如何在训练集上进行训练的。包括数据的加载、模型的前向传播和反向传播过程、损失函数的计算、优化器的更新等。理解训练过程可以帮助我们调试和优化模型。 - 查看模型的评估(测试)过程。查看项目中的
test.py,知道模型是如何在验证集或测试集上进行评估的。包括模型的加载、数据的加载、模型的前向传播、性能指标的计算等。了解评估过程可以帮助我们评估模型的性能和泛化能力。 - 查看模型的参数配置。例如查看
ops文件,查看项目中的参数配置。包括模型的超参数、训练参数、数据路径等。通过查看参数配置信息,可以帮助我们很好的调参。
通过上面的分析,项目的核心我们就掌握了,接下来就可以尝试运行项目的 train.py 和test.py ,对项目进行训练和评估,并观察模型的训练过程和性能表现。最后,可以根据我们的需求,对模型和代码进行修改和调试,通过修改模型结构、调整超参数等等操作,观察对模型性能的影响。
上面提到的是我自己用到的一种方法,还有一种分析方法是这样的:打开项目之后,从项目的运行入口开始查看(大多数是 train.py),然后按照 train.py 里面代码的逻辑顺序进行查看,遇到各种类,各种方法就跳过去查看相应的实现。
😃😃😃
![[flink 实时流基础]源算子和转换算子](https://img-blog.csdnimg.cn/img_convert/b6b3026c6ba5c3c64079df5c81888e22.png)