注册接口
演示注册接口的三步操作:【注册流程逻辑】
第一步:发送注册短信验证码接口请求
请求方法: put
请求地址:http://shop.lemonban.com:8107/user/sendRegisterSms
请求参数:{“mobile”:“13422337766”}
请求头部:{“Content-Type”:application/json;charset=UTF-8"}
响应结果: 空
需要去查询数据库中tz_sms_log表获取验证码信息
项目的数据库说明文档在百度网盘里,大家自己去获取。
第二步:发送校验注册短信验证码接口请求
请求方法: put
请求地址:http://shop.lemonban.com:8107/user/checkRegisterSms
请求参数:{“mobile”:“13422337766”,“validCode”:“869760”}
请求头部:{“Content-Type”:application/json;charset=UTF-8"}
响应结果:b57b9b5865584c8ca3e23f36868a2511 【注意是文本-text】
第三步:真正的注册接口请求
请求方法: put
请求地址:http://shop.lemonban.com:8107/user/registerOrBindUser
“appType”:3,“checkRegisterSmsFlag”:“b57b9b5865584c8ca3e23f36868a2511”,“mobile”:“13422337766”,“userN
请求参数:
{
请求头部:{“Content-Type”:application/json;charset=UTF-8”}
{“access_token”:“79db686e-1a83-4401-a571-
23a68ac8d45b”,“token_type”:“bearer”,“refresh_token”:“47590c95-5b0f-48c7-8d5cd093fba4f021”,“expires_in”:1295999,“pic”:null,“userId”:“eea8b4fb74514837b2f683bbadcd22aa”,“nickName”
执行注册接口的用例,现在发现有几个问题需要解决:
1、需要去获取验证码了;验证没有在接口返回值里返回,我们就需要去数据库里获取了!
- 数据库获取验证码的问题: 因为我们有封装好的数据库查询的方法可以直接使用。
- 调用一下我们之前讲的数据库的封装好的方法, 返回的结果是查询数据的字典。
- 第一条用例执行完成之后,就会再数据库里生成一个记录
- 第二条用例执行之前查询数据库 得到数据库结果
2、手机号码和用户名注册过一次后,不能重复注册,就会有问题。
- 也就是标红的这些数据是不能写死的。要么是数据库里拿的 要么是不能每次写一样的的。 要么是从上个接
口返回的提取的
"""
思路:整体思路跟我们之前的提取响应结果差不多。
1、先把前置sql语句写在excel表格里: json格式 ,key 【变量名】: value 【sql语句】
2、读取出来,是字符串,做反序列化操作,转化为字典;
3、读取这个前置sql,for循环k v 得到这个变量和sql语句,sql去数据库里查,调用我们之前封装的sql的类方法,得到的结果是个字典。
4、查完后结果存储在环境变量作为属性。属性名就是k 变量名;
5、请求参数里的mobilecode就可以从环境变量里获取这个结果数据了。-- 调用之前的替换函数。【所以,参数里变化的数据需要占位符占位,方便查找替换】==已经完成了!"""
import json
from tools.handle_mysql import HandleMysql
from datas.db_data import my_db
from tools.envi_data import EnviDatasql_data = '''{"mobile_code":
"select mobile_code from tz_sms_log where user_phone='13422337768' order by rec_date desc limit 1;"}'''# 第一步: 字符串做反序列化操作--转化为字典
sql_data = json.loads(sql_data)
# 第二步: 分别得到key 和value ==for遍历 items()
for k,v in sql_data.items(): # k 是变量变量名- mobile_code,v是sql语句sql_result = HandleMysql(**my_db).query_data(v) # 结果是字典 {'mobile_code': '845305'}# 第三步: 查完后结果存储在环境变量作为属性。属性名就是k 变量名;mobile_codefor i,j in sql_result.items(): # i 是变量名 j 是v属性值setattr(EnviData,i,j) # 把结果存在环境变量里
print(EnviData.__dict__)前置SQL思路
先解决第一个问题,数据里获取数据。
思考问题: 这个操作应该是在第二个接口请求发送之前做的还是发送之后做的?
在excel表格里加上一列: 前置SQL。【参考Jmeter这种工具前置处理器,就是在接口执行之前操作】
思路:整体思路跟我们之前的提取响应结果差不多。
- 1、先把前置sql语句写在excel表格里: json格式 ,key 【变量名】: value 【sql语句】
- 2、读取出来,是字符串,做反序列化操作,转化为字典;
- 3、读取这个前置sql,for循环k v 得到这个变量和sql语句,sql去数据库里查,调用我们之前封装的sql的类方法,得到的结果是个字典。
- 4、查完后结果存储在环境变量作为属性。属性名就是k 变量名;
- 5、请求参数里的mobilecode就可以从环境变量里获取这个结果数据了。-- 调用之前的替换函数。【所以,参数里变化的数据需要占位符占位,方便查找替换】==已经完成了!
封装好了前置sql的方法后,思考在哪里用?
还是发送接口请求之前用,所以依然在requests_api方法库调用这个方法。
在替换提前之前调用,因为要提取完成后,去替换参数。
然后分析第三条用例。验证码"checkRegisterSmsFlag"的value是要第二步的结果里的值
但是第三步操作返回结果是text,不是json,怎么提取?
公用之前的提取的函数: 如果是json就用jsonpath提取,如果是text就或文本 【类似我们的响应断言的思路】
所以,要二次修改 extract提取的方法。加一个判断分支:
- 1、针对键值对的值做判断,是$开头的就是jsonpath
- 2、v如果是text 就是直接获取响应文本。
- 3、结果都是存在环境变量里的。
前置SQL数据封装
第一步:发送请求前先获取数据
handle_replace.py
"""
方法优化:
1、日志加上2、测试用例方法里调用夹具 获取返回值。
- 更新requests-api,需要做token处理:- 设置一个默认参数:token = None- 如果接口需要鉴权,测试用例里调用夹具,得到token,requests_api传递token参数;--requests 更新头部- 如果接口不需要鉴权: token不传 None。 不会做更新头部的操作。"""import json
import requests
from tools.handle_path import pic_path
from loguru import logger
from tools.handle_extract import extract_response
from tools.handle_replace import replace_mark
from tools.handle_presql import pre_sqldef requests_api(casedata,token=None):method = casedata["请求方法"]url = casedata["接口地址"]headers = casedata["请求头"]params = casedata["请求参数"]presql = casedata["前置SQL"]# 在执行前置SQL之前,替换占位符数据presql = replace_mark(presql)# 在数据替换之前调用前置SQL方法:调用完成后,把结果放到环境变量里pre_sql(presql)# 在发送请求之前完成头部和参数的替换--调用替换的函数==结果是字符串headers = replace_mark(headers)params = replace_mark(params)# 反序列操作: 结合判空处理,if headers is not None:headers = json.loads(headers)if token is not None: # 这是做接口如果需要鉴权,传进来token 更新头部信息。headers["Authorization"] = token # 字典新增 / 修改if params is not None:params = json.loads(params)logger.info("---------------------------请求消息-----------------------------------")logger.info(f"请求方法是{method}")logger.info(f"请求地址是{url}")logger.info(f"请求头部是{headers}")logger.info(f"请求参数是{params}")#接口请求可能是get post put等各种请求方法 分支判断if method.lower() == "get":resp = requests.request(method=method, url=url, params=params,headers=headers)elif method.lower() == "post":if headers is None:logger.info("头部为空,检查excel表格里头部信息!")return# post请求:content-type的类型有关系。需要对每一种类型做处理 分支判断if headers["Content-Type"] == "application/json":resp = requests.request(method=method, url=url, json=params, headers=headers)if headers["Content-Type"] == "application/x-www-form-urlencoded":resp = requests.request(method=method, url=url, data=params, headers=headers)if headers["Content-Type"] == "multipart/form-data":# 发送请求的时候不能带上 'Content-Type': 'multipart/form-data' 删除之后才发送接口请求。headers.pop("Content-Type") # 字典删除元素filename = params["filename"] # 文件名字 值file_obj = {"file": (filename, open(pic_path/filename, "rb"))} # 文件参数logger.info(f"文件接口的参数是:{file_obj}")logger.info(f"文件接口的头部是:{headers}")resp = requests.request(method=method, url=url,headers=headers,files=file_obj)elif method.lower() == "put":resp = requests.request(method=method, url=url, json=params, headers=headers)logger.info("------------------------------响应消息-----------------------------")logger.info(f"接口响应状态码是:{resp.status_code}")logger.info(f"接口响应体是:{resp.text}")# 提取响应结果的数据-- 调用提取数据的函数extract_response(resp,casedata["提取响应字段"])return resp第二步从获取前置sql数据,为空就不调用数据库连接,不为空就调用数据库连接
handle_presql.py
"""
1、def封装
2、参数化
3、返回值: 因为数据都存在环境变量 所以不需要返回值
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做前置SQL,所以判空处理:"""
import json
from tools.handle_mysql import HandleMysql
from datas.db_data import my_db
from tools.envi_data import EnviData
from loguru import loggerdef pre_sql(sql_data):if sql_data is None:return# 第一步: 字符串做反序列化操作--转化为字典logger.info("---------------------前置SQL执行开始-------------------------")sql_data = json.loads(sql_data)logger.info(f"前置sql提取表达式为:{sql_data}")# 第二步: 分别得到key 和value ==for遍历 items()for k,v in sql_data.items(): # k 是变量变量名- mobile_code,v是sql语句sql_result = HandleMysql(**my_db).query_data(v) # 结果是字典 {'mobile_code': '845305'}# 第三步: 查完后结果存储在环境变量作为属性。属性名就是k 变量名;mobile_codefor i,j in sql_result.items(): # i 是变量名 j 是v属性值setattr(EnviData,i,j) # 把结果存在环境变量里logger.info(f"提取并设置环境变量之后的类属性是:{EnviData.__dict__}")if __name__ == '__main__':sql_data = '''{"mobile_code":"select mobile_code from tz_sms_log where user_phone='13422337768' order by rec_date desc limit 1;"}'''pre_sql(sql_data)
第三步连接数据库封装
handle_mysql.py
import pymysql
from pymysql.cursors import DictCursor
from loguru import loggerclass HandleMysql:def __init__(self,user,password,database,port,host):"""定义了两个实例属性: conn cursor ,可以用于后续实例方法共享。"""self.conn = pymysql.connect(user=user,password=password,database=database,port=port,host=host,charset="utf8mb4",cursorclass=DictCursor)self.cursor = self.conn.cursor()def query_data(self,query_sql,match_num=1,size=None):""":param query_sql: 查询sql语句:param match_num: 用户获取条数 match_num=1,fetchone;match_num=2,fetchmany,match_num=-1,fetchall:param size:当match_num=2,size是查询的条数,传参。:return: 返回查询结果数据"""try:result = self.cursor.execute(query_sql) # 结果条数 >0 才有获取详细数据必要logger.info(f"数据库的查询结果条数为:{result}")if result > 0:if match_num==1:data = self.cursor.fetchone()logger.info(f"查询结果数据为:{data}")return dataelif match_num == 2:data = self.cursor.fetchmany(size = size)logger.info(f"查询结果数据为:{data}")return dataelif match_num == -1:data = self.cursor.fetchall()logger.info(f"查询结果数据为:{data}")return datalogger.warning("请传入1,2,-1的match_num")logger.info("数据库没有查询结果!")except:logger.error("数据库操作异常!")finally:self.cursor.close()self.conn.close()if __name__ == '__main__':my_db = {"user": "lemon_auto","password": "lemon!@123","database": "yami_shops","port": 3306,"host": "mall.lemonban.com"}sql = "select mobile_code from tz_sms_log where user_phone='13645321122' order by rec_date desc limit 1;"result = HandleMysql(**my_db).query_data(sql)print(result)
数据生成思路
解决第二个问题:手机号码和用户名注册过一次后,不能重复注册,就会有问题。
思路:参考JMeter 随机函数 random
- 1、生成一个随机的手机号码 | 用户名,符合手机号和用户名的格式规则,类似于Jmeter里随机函数助手:random ,Python里也有类似的库:Faker
- 2、把生成的数据去数据库里确认是否真的不重复,调用数据库的方法 : 查询这个号码不存在用户表里
–select * from tz_user where user_mobile = "13444444444"
第一步:faker(骗子),这是一个生成随机数据的工具; Faker是一个第三方库,
安装: pip install Faker
官方地址:https://faker.readthedocs.io/en/stable/
faker.python下有更多的生成随机的方法:这些方法有很多,没有必要都记住,做好笔记,以及用到了再查笔记即可。
from faker import Faker
# 实例化 -Faker本身就是一个类
# 直接各种地区的标准,可以先指定一个区域 中国就是zh_CN,生成的数据就是中国的标准 电话 银行卡之类的
fk = Faker(locale='zh_CN')
print(fk.phone_number()) #手机号码
print(fk.name()) # 人名字,如果名字有长度的要求,4-6位,还要做额外的判断处理。
print(fk.name_female()) # 女性名字
print(fk.ssn()) # 身份证
print(fk.email()) # 邮箱
print(fk.company()) # 公司名字
print(fk.city()) # 城市
print(fk.address()) # 地址
print(fk.sentence()) # 一句话
print(fk.text()) # 一段文章
print(fk.pystr(min_chars=2,max_chars=10)) # 随机字符串 最小长度和最大长度
第二步: 把生成的数据去数据库里确认有无。调用数据库的方法 : 查询这个号码不存在用户表里:
select * from tz_user where user_mobile = "13444444444"
查询结果为None,就是不存在的。那么这个号码可以用
查询结果不为None,那么就是存在数据库了,重复了,不能用,就继续重新生成一个号码,再重复上述操作。
直到查询的结果为None位置。【所以,这个过程需要用什么技术完成?】
思考问题: 现在生成数据的方法已经封装好了,在哪里用?
我注册的第一条用例的数据就需要用,也就是这个号码的位置需要用-函数生成的数据 替换。
测试用例里先占位符替换一下 - 手机号码和用户名的位置需要调用函数生成-- 用函数名替换。
#gen_unregister_phone()# == 替换函数,gen_unregister_phone() 就是一个函数名 --直接调用函数 执行函数 得到结果
函数的返回值。
生成完成后,我们需要设置到环境变量里,后面要用的时候去环境变量里获取,用这个同样的号码。
思考: 后面还能每次调用这个函数生成么?–不能,因为需要是同一个号码 重新生成号码会是新的号码
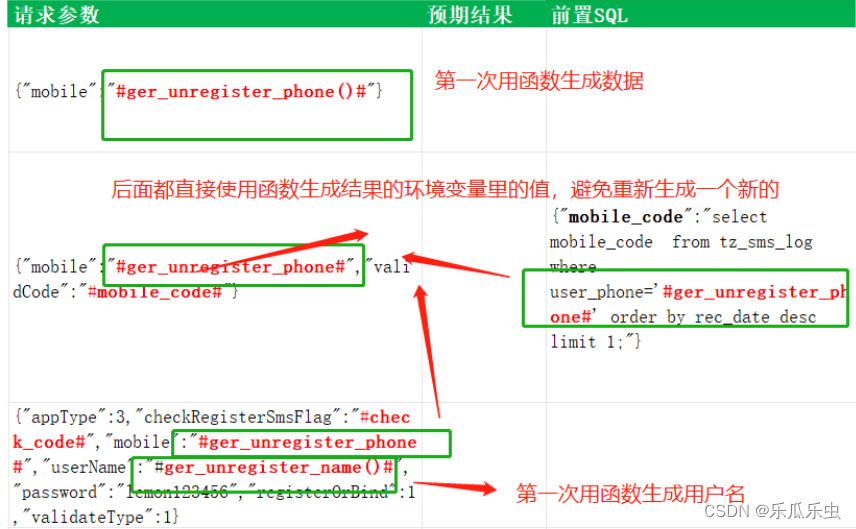
既然要替换占位符,我们之前的函数就可以用了;但是之前的函数只用于替换变量,不能替换函
数。所以要扩展这个函数的功能:
思路:需要做分支判断:
- 如果是函数【有括号()】: 得到占位符里的函数,调用函数并执行函数,生成数据,存到环境变量里 ==新加的分支方法
- 如果是变量【没有()】: 那么就直接从环境变量里获取属性 替换就可以了;–老方法 不用改
"""
用faker生成随机手机号码和用户名:
第一步: 调用faker类生成手机号码
第二步:把生成的数据去数据库里确认是否真的不重复,调用数据库的方法- 查询这个号码不存在用户表里-- select * from tz_user where user_mobile = "13444444444"- 结果是None,数据库不存在的;- 结果不是None,那么数据里存在的,继续生成,重复过程。"""from faker import Faker
from tools.handle_mysql import HandleMysql
from datas.db_data import my_db# Faker是一个类 实例化,传参: locale可以指定地区,生成数据符合地区的格式【手机号,银行卡 地址】
fk = Faker(locale="zh_CN")while True:# 第一步:调用faker类生成手机号码phone_number = fk.phone_number()# 第二步:把生成的数据去数据库里确认是否真的不重复sql = f'select * from tz_user where user_mobile = "{phone_number}"'sql_result = HandleMysql(**my_db).query_data(sql)if sql_result is not None: # 如果数据里有这个号码 继续生成 循环continueelse: # 如果数据里没有这个号码 得到号码 跳出循环print(phone_number)break数据生成封装
第一步生成随机数据并去数据库查询是否已含有对应的数据
handle_generate.py
"""
用户名有长度要求: 4-16位长度的用户名因为这些生成数据的方法可能需要后续进行扩展: 生成其他的数据。
所以可以把这些方法都当到一个类里。 统一管理。思考:这个函数应该在哪里执行呢?
思路:
1、执行第一个接口的时候,需要替换掉参数里的占位符位置-- 调用函数并执行函数的结果"""from faker import Faker
from tools.handle_mysql import HandleMysql
from datas.db_data import my_dbclass GenData:def gen_unregister_phone(self):fk = Faker(locale="zh_CN")while True:# 第一步:调用faker类生成手机号码phone_number = fk.phone_number()# 第二步:把生成的数据去数据库里确认是否真的不重复sql = f'select * from tz_user where user_mobile = "{phone_number}"'sql_result = HandleMysql(**my_db).query_data(sql)if sql_result is not None: # 如果数据里有这个号码 继续生成 循环continueelse: # 如果数据里没有这个号码 得到号码 跳出循环return phone_numberdef gen_unregister_name(self):fk = Faker(locale="zh_CN")while True:# 第一步:调用faker类生成用户名username = fk.user_name()# 第二步:把生成的数据去数据库里确认是否真的不重复sql = f'select * from tz_user where user_name = "{username}"'sql_result = HandleMysql(**my_db).query_data(sql)if sql_result is not None or (len(username) < 4 or len(username) > 16): # 如果数据里有这个号码 继续生成 循环continueelse: # 如果数据里没有这个号码 得到号码 跳出循环return usernameif __name__ == '__main__':print(GenData().gen_unregister_phone())print('GenData().gen_unregister_name()')result = eval('GenData().gen_unregister_name()')print(result)第二步在excel数据中调用对应的函数方法。
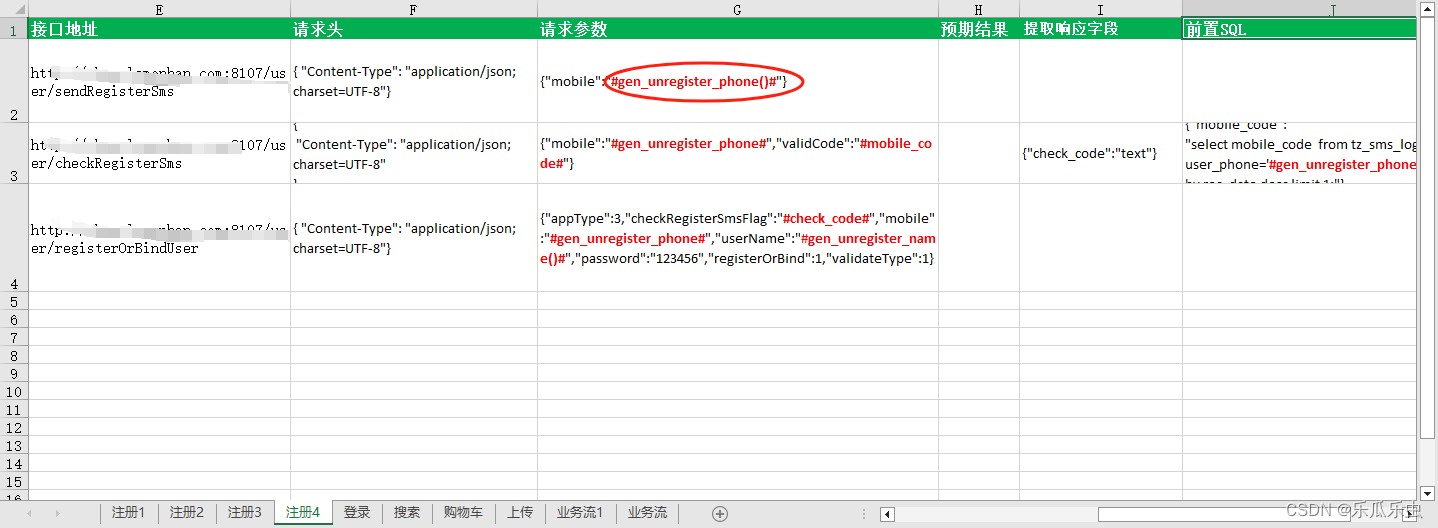
第三步有就不替换,如果没有对应的函数(需要对数据进行二次替换)
handle_replace.py
"""
1、def封装
2、参数化
3、返回值: 最终要拿到替换后的字符串 --- 头部 参数 要用于发送接口测试的
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做数据提取,所以判空处理:
6、异常捕获: 因为有可能环境变量里没有这个属性名 和属性值"""
import re
from loguru import logger
from tools.envi_data import EnviData
from tools.handle_generate import GenDatadef replace_mark(str_data):while True:if str_data is None:returnresult = re.search("#(.*?)#",str_data)if result is None: # 如果没有占位符 就是None 跳出循环breakmark = result.group() # 结果是 #prodId# --要被替换的子字符串| #gen_unregister_phone()#logger.info(f"要被替换的子字符串:{mark}")if "()" in mark:fun_name = result.group(1) # 第一个分组的值 结果是 gen_unregister_phone()logger.info(f"要提取环境变量的函数名:{fun_name}")# 通过eval拖引号之后,不可以直接GenData().gen_unregister_name(),要导包gen_data = eval(f'GenData().{fun_name}') # 接口函数的返回值结果-生成的数据logger.info(f"生成的随机的数据是:{gen_data}")# 1、存数据到环境变量里 -- 类属性的名字 函数名去掉()var_name = fun_name.strip("()") # 结果是 gen_unregister_phonesetattr(EnviData,var_name,gen_data) # 属性名:gen_unregister_phone 属性值: gen_datalogger.info(f"环境变量的属性值:{EnviData.__dict__}")# 2、完成第一条的参数的替换 用刚刚生成的数据替换str_data = str_data.replace(mark,str(gen_data))logger.info(f"替换完成后的字符串是:{str_data}")else:var_name = result.group(1) # 第一个分组的值 结果是 prodIdlogger.info(f"要提取环境变量的属性名:{var_name}")try:var_value = getattr(EnviData,var_name) # 结果 : 7717--int类型except AttributeError as e:logger.error(f"环境变量里不存在这个属性:{var_name}")raise elogger.info(f"要提取环境变量的属性值:{var_value}")str_data = str_data.replace(mark,str(var_value))logger.info(f"替换完成后的字符串是:{str_data}")return str_dataif __name__ == '__main__':# str_data = '{"basketId": 0, "count": 1, "prodId": #prodId#, "shopId": 1, "skuId": #skuId#}'str_data = '{"mobile": "#gen_unregister_phone()#"}'replace_mark(str_data)
![[实时流基础 flink] 窗口](https://img-blog.csdnimg.cn/img_convert/bf88acf050deddebb5a9b9b8ea8de090.png)