YARN集群模式
本文内容需要基于 Hadoop 集群搭建完成的基础上来实现
如果没有搭建,请先按上一篇:
<Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤>
搭建:https://mp.weixin.qq.com/s/zPYsUexHKsdFax2XeyRdnA
配置hadoop安装目录下的 etc/hadoop/yarn-site.xml
配置hadoop安装目录下的 etc/hadoop/mapred-site.xml
例如:/opt/apps/hadoop-3.2.4/etc/hadoop/
配置 yarn-site.xml
vim etc/hadoop/yarn-site.xml添加内容如下:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>node3</value></property>
</configuration>注意:上面node3 为自己规划的作为 resourcemanager 节点的主机名
配置 mapred-site.xml
[zhang@node3 hadoop]$ vi mapred-site.xml添加内容如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.2.4</value></property>
</configuration>注意:上面的 /opt/apps/hadoop-3.2.4 为自己 hadoop 的安装目录
同步配置
修改完成后,需要复制配置到其他所有节点
scp -r etc/ zhang@node1:/opt/apps/hadoop-3.2.4/
scp -r etc/ zhang@node1:/opt/apps/hadoop-3.2.4/
在 $HADOOP_HOME/etc/下
scp -r hadoop/yarn-site.xml zhang@node2:/opt/apps/hadoop-3.2.4/etc/hadoop/也可以通过 pwd来表示远程拷贝到和当前目录相同的目录下
scp -r hadoop node2:`pwd` # 注意:这里的pwd需要使用``(键盘右上角,不是单引号),表示当前目录启动 YARN 集群
# 在主服务器(ResourceManager所在节点)上hadoop1启动集群sbin/start-yarn.sh# jps查看进程,如下所⽰代表启动成功
==========node1===========
[zhang@node1 hadoop]$ jps
7026 DataNode
7794 Jps
6901 NameNode
7669 NodeManager==========node2===========
[zhang@node2 hadoop]$ jps
9171 NodeManager
8597 DataNode
8713 SecondaryNameNode
9294 Jps==========node3===========
[zhang@node3 etc]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[zhang@node3 etc]$ jps
11990 ResourceManager
12119 NodeManager
12472 Jps
11487 DataNode
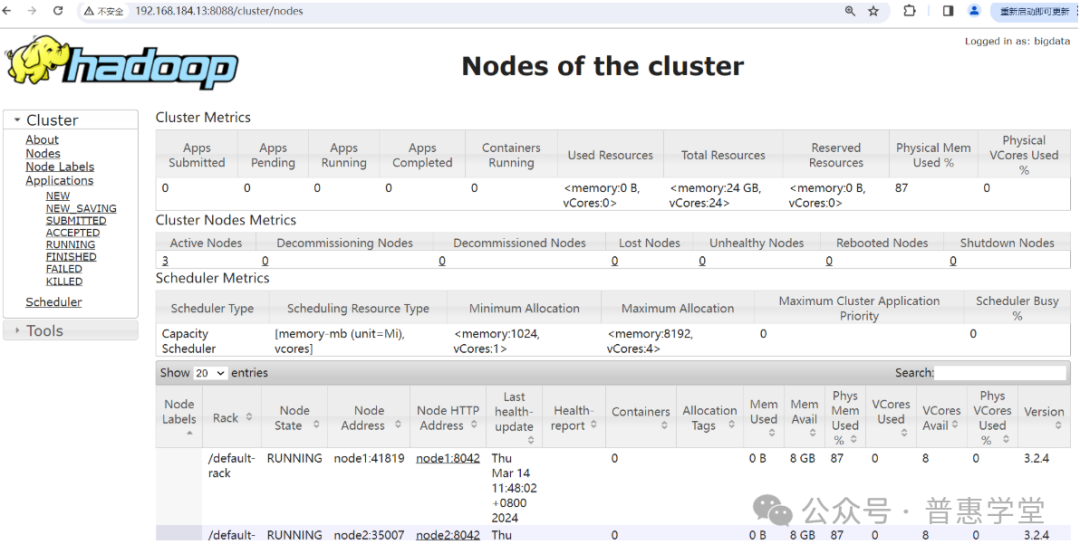
启动成功后,可以通过浏览器访问 ResourceManager 进程所在的节点 node3 来查询运行状态
截图如下:
MapReduce
简介和原理
MapReduce 是一种分布式编程模型,最初由 Google 提出并在学术论文中公开描述,后来被广泛应用于大规模数据处理,尤其是 Apache Hadoop 等开源项目中实现了这一模型。MapReduce 的核心思想是将复杂的大量数据处理任务分解成两个主要阶段:Map(映射)阶段和 Reduce(归约)阶段。
Map(映射)阶段:
-
将输入数据集划分为独立的块。
-
对每个数据块执行用户自定义的 map 函数,该函数将原始数据转换为一系列中间键值对。
-
输出的结果是中间形式的键值对集合,这些键值对会被排序并分区。
Shuffle(洗牌)和 Sort(排序)阶段:
-
在 map 阶段完成后,系统会对产生的中间键值对进行分发、排序和分区操作,确保具有相同键的值会被送到同一个 reduce 节点。
Reduce(归约)阶段:
-
每个 reduce 节点接收一组特定键的中间键值对,并执行用户自定义的 reduce 函数。
-
reduce 函数负责合并相同的键值对,并生成最终输出结果。
整个过程通过高度并行化的方式完成,非常适合处理 PB 级别的海量数据。由于其简单易懂的设计理念和强大的并行处理能力,MapReduce 成为了大数据处理领域的重要基石之一,尤其适用于批处理类型的分析任务,如网页索引构建、日志分析、机器学习算法实现等。
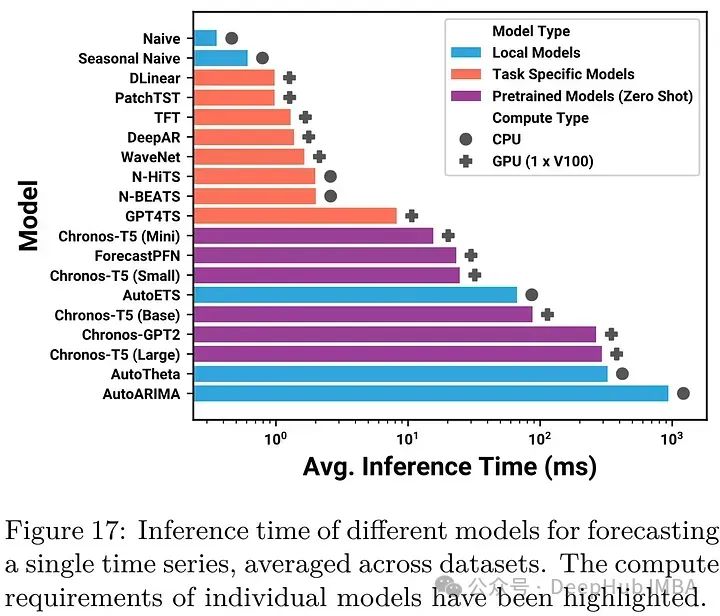
下面通过一张使用 MapReduce 进行单词数统计的过程图,来更直观的了解 MapReduce 工作过程和原理
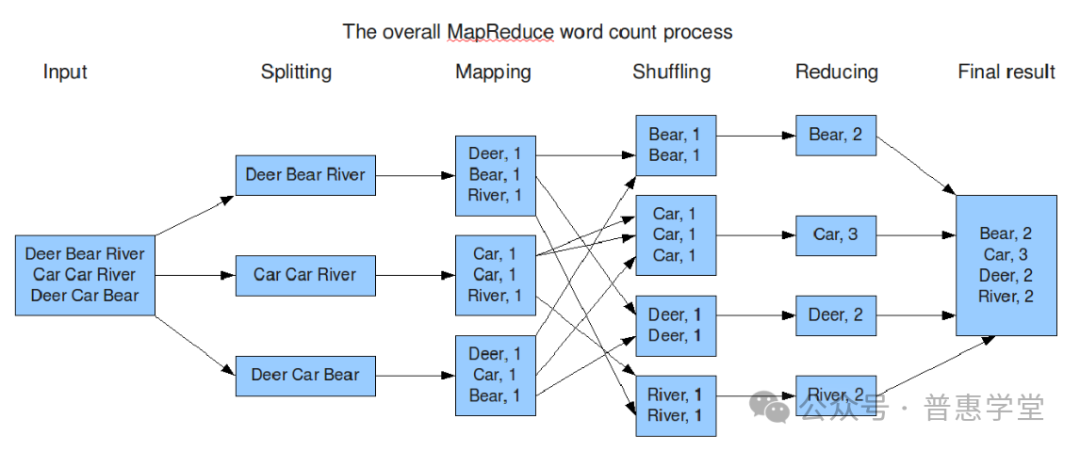
MapReduce 示例程序
在搭建好 YARN 集群后,就可以测试 MapReduce 的使用了,下面通过两个案例来验证使用 MapReduce
-
单词统计
-
pi 估算
在hadoop 安装目录下的 share/hadoop/mapreduce 目录下存放了一些示例程序 jar 包,
可以调用 hadoop jar 命令来调用示例程序
具体步骤如下:
PI 估算案例
先切换目录到 安装目录/share/hadoop/mapreduce/ 下
[zhang@node3 ~]$ cd /opt/apps/hadoop-3.2.4/share/hadoop/mapreduce/
[zhang@node3 mapreduce]$ ls
hadoop-mapreduce-client-app-3.2.4.jar hadoop-mapreduce-client-shuffle-3.2.4.jar
hadoop-mapreduce-client-common-3.2.4.jar hadoop-mapreduce-client-uploader-3.2.4.jar
hadoop-mapreduce-client-core-3.2.4.jar hadoop-mapreduce-examples-3.2.4.jar
hadoop-mapreduce-client-hs-3.2.4.jar jdiff
hadoop-mapreduce-client-hs-plugins-3.2.4.jar lib
hadoop-mapreduce-client-jobclient-3.2.4.jar lib-examples
hadoop-mapreduce-client-jobclient-3.2.4-tests.jar sources
hadoop-mapreduce-client-nativetask-3.2.4.jar
[zhang@node3 mapreduce]$
调用 jar 包执行
hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 3 4
[zhang@node3 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 3 4
Number of Maps = 3 #
Samples per Map = 4
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Starting Job
2024-03-23 17:48:56,496 INFO client.RMProxy: Connecting to ResourceManager at node3/192.168.184.13:8032
2024-03-23 17:48:57,514 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for #............省略
2024-03-23 17:48:59,194 INFO mapreduce.Job: Running job: job_1711186711795_0001
2024-03-23 17:49:10,492 INFO mapreduce.Job: Job job_1711186711795_0001 running in uber mode : false
2024-03-23 17:49:10,494 INFO mapreduce.Job: map 0% reduce 0%
2024-03-23 17:49:34,363 INFO mapreduce.Job: map 100% reduce 0%
............Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=354File Output Format Counters Bytes Written=97
Job Finished in 53.854 seconds
Estimated value of Pi is 3.66666666666666666667 # 计算结果
命令的含义
这个命令的具体含义是:
hadoop jar: 命令用于执行 Hadoop 应用程序,这里的应用程序是指从 JAR 包hadoop-mapreduce-examples-3.2.4.jar中提取的 MapReduce 程序。
pi: 这是具体的示例程序名称,用于通过概率方法估算π值。
2: 这个数字代表实验的总样本数(也称为总投点数),意味着将会随机投掷2次点来估计π值。
4: 这个数字通常表示地图任务(map tasks)的数量,也就是说,计算过程将会被拆分为4个部分来并行执行。
单词统计案例
hadoop-mapreduce-examples-3.2.4.jar是 Apache Hadoop MapReduce 框架的一部分,其中包含了多个演示 MapReduce 概念和功能的例子程序,其中一个经典例子就是wordcount。
wordcount示例程序展示了如何使用 MapReduce 模型处理大规模文本数据,统计文本中每个单词出现的次数。当你在 Hadoop 环境中执行如下命令时:hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount input_path output_path这里发生了以下过程:
input_path:指定输入数据的位置,通常是 HDFS 上的一个目录,该目录下的所有文件将作为输入数据源,被分割成各个映射任务(Mapper)处理。
Mapper:每个映射任务读取一段输入数据,并将其拆分成单词,然后为每个单词及其出现次数生成键值对
<word, 1>。Reducer:所有的映射任务完成后,Reducer 对由 Mapper 发出的中间键值对进行汇总,计算出每个单词的总出现次数,并将最终结果输出到 output_path 指定的 HDFS 目录下。
演示步骤如下:
新建文件
首先在 /opt/下新建目录 data 用来存放要统计的文件
新建 word.txt 文件并输入内容如下:
hello java
hello hadoop
java hello
hello zhang java具体命令如下:
[zhang@node3 opt]$ mkdir data
[zhang@node3 opt]$ cd data
[zhang@node3 data]$ ls
[zhang@node3 data]$ vim word.txt上传文件到hadoop
hdfs dfs 命令
新建 input 目录用来存放 word.txt 文件
[zhang@node3 data]$ hdfs dfs -mkdir /input # 新建目录
[zhang@node3 data]$ hdfs dfs -ls / # 查看目录
Found 1 items
drwxr-xr-x - zhang supergroup 0 2024-03-23 16:52 /input
[zhang@node3 data]$ hdfs dfs -put word.txt /input # 上传文件到目录
[zhang@node3 data]$ 统计单词
hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount /input /outputx
hadoop jar 为命令
hadoop-mapreduce-examples-3.2.4.jar 为当前目录下存在jar文件
wordcount 为要调用的具体的程序
/input 为要统计单词的文件所在的目录,此目录为 hadoop 上的目录
/outputx 为输出统计结果存放的目录
注意:/outputx 目录不能先创建,只能是执行时自动创建,否则异常
[zhang@node3 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.4.jar wordcount /input /outputx
2024-03-23 18:11:55,438 INFO client.RMProxy: Connecting to ResourceManager at node3/192.168.184.13:8032
#............省略
2024-03-23 18:12:17,514 INFO mapreduce.Job: map 0% reduce 0%
2024-03-23 18:12:50,885 INFO mapreduce.Job: map 100% reduce 0%
2024-03-23 18:12:59,962 INFO mapreduce.Job: map 100% reduce 100%
2024-03-23 18:12:59,973 INFO mapreduce.Job: Job job_1711186711795_0003 completed successfully
2024-03-23 18:13:00,111 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=188FILE: Number of bytes written=1190789FILE: Number of read operations=0#............省略HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=4Launched reduce tasks=1Data-local map tasks=4Total time spent by all maps in occupied slots (ms)=125180#............省略Map-Reduce FrameworkMap input records=13Map output records=27Map output bytes=270Map output materialized bytes=206#............省略Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=163File Output Format Counters Bytes Written=51
[zhang@node3 mapreduce]$
查看统计结果
先查看输出目录下的结果文件名
在 hdfs dfs -cat 查看内容
[zhang@node3 mapreduce]$ hdfs dfs -ls /outputx # 查看输出目录下文件
Found 2 items
-rw-r--r-- 3 zhang supergroup 0 2024-03-23 18:12 /outputx/_SUCCESS
-rw-r--r-- 3 zhang supergroup 51 2024-03-23 18:12 /outputx/part-r-00000
[zhang@node3 mapreduce]$ hdfs dfs -cat /outputx/part-r-00000 # 查看内容
hadoop 3
hello 14
java 6
python 2
spring 1
zhang 1常见问题
错误1:
[2024-03-15 08:00:16.276]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}
解决办法:
根据上面提示修改 mapred-site.xml ,配置 HADOOP_MAPRED_HOME,指向 hadoop 安装目录 即可。
错误2:
运行 Java 程序,调用 Hadoop 时,抛出异常
2024-03-16 14:35:57,699 INFO ipc.Client: Retrying connect to server: node3/192.168.184.13:8032. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)原因:
连接node3的 yarn 时,没有成功,说明没启动 start-yarn.sh
错误3:
node2: ERROR: JAVA_HOME is not set and could not be found.解决办法:
${HADOOP_HOME}/etc/hadoop/hadoop_en.sh 添加
JAVA_HOME=/opt/apps/opt/apps/jdk1.8.0_281
注意:不能使用 JAVA_HOME=${JAVA_HOME}
错误4:
[zhang@node3 hadoop]$ start-dfs.sh
ERROR: JAVA_HOME /opt/apps/jdk does not exist.解决办法:
修改 /hadoop/etc/hadoop/hadoop-env.sh 文件
添加 JAVA_HOME 配置