串
定义串,即字符串(String)是由零个或多个字符组成的有限序列.
术语:串长、空串、空格串、子串、主串、字符在主串中的位置、子串在主串中的位置
-
串的定义和性质:了解串的基本定义,包括如何表示、如何存储、如何操作串以及串的基本性质,比如长度、空串等。
-
串的基本操作:掌握对串进行的基本操作,如串的赋值、串的连接、串的比较、串的子串提取等。
-
串的存储结构:了解串的不同存储结构,比如顺序存储结构和链式存储结构,以及它们各自的优缺点。
-
串的模式匹配:掌握串的模式匹配算法,如朴素的暴力匹配算法、KMP算法、Boyer-Moore算法等,理解它们的原理和实现。
-
串的应用:了解串在实际中的应用,比如文本编辑器中的搜索功能、编译器中的词法分析、生物信息学中的序列比对等。
-
串的高级操作:了解一些高级的串操作,如串的替换、串的插入、串的删除等。
-
串的扩展:了解一些扩展的串结构,比如循环串、定长串等,以及它们的特点和应用场景。
-
串的算法复杂度:理解对串进行操作的算法的时间和空间复杂度,以便能够评估算法的效率和性能。
串的存储结构主要有两种:顺序存储结构和链式存储结构。
-
顺序存储结构:串的顺序存储结构通常使用一维数组来实现。在这种结构中,串中的字符被顺序地存储在一片连续的存储空间中。每个字符占用一个存储单元,通过数组下标可以访问串中的任意一个字符。这种结构适合于对串进行频繁的随机存取和修改操作。
-
链式存储结构:串的链式存储结构使用链表来实现。在链式结构中,每个节点存储一个字符,同时包含一个指向下一个节点的指针。通过节点之间的链接,可以将字符依次串起来形成一个完整的串。这种结构适合于对串进行频繁的插入和删除操作。
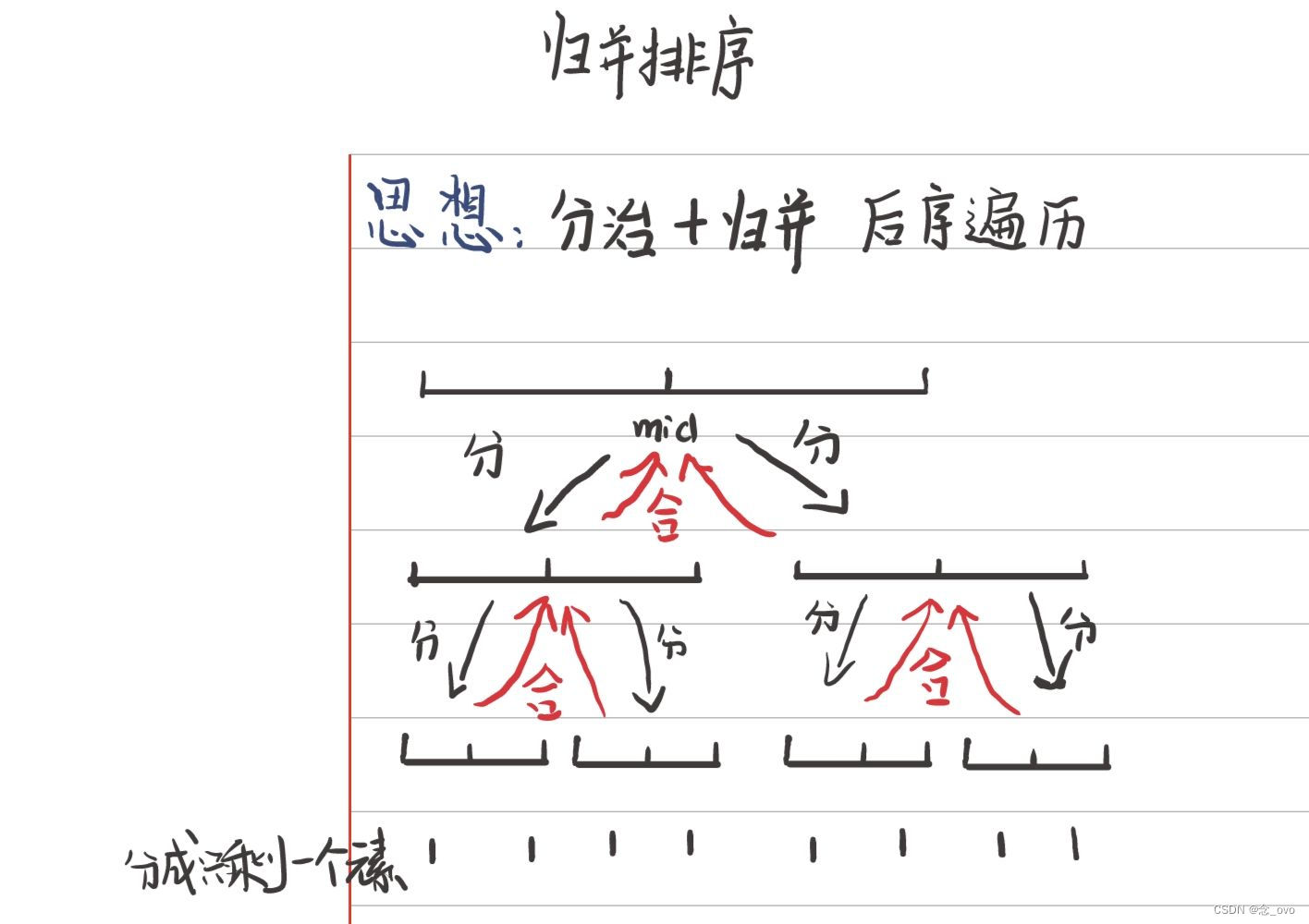
串的模式匹配是一种常见的算法问题,其目标是在一个主串中查找一个模式串是否存在,并找到所有匹配的位置。常见的模式匹配算法包括:
-
朴素的暴力匹配算法:从主串的第一个字符开始,依次与模式串进行比较,如果不匹配,则主串向后移动一位,直到找到匹配的位置或主串结束。这种算法的时间复杂度为O(m*n),其中m和n分别是主串和模式串的长度。
算法思想

-
KMP算法:KMP算法通过预处理模式串,构建一个部分匹配表(next数组),利用这个表在匹配过程中避免回溯。它的时间复杂度为O(m+n),其中m和n分别是主串和模式串的长度。
算法思想

def getNext(pattern):next = [-1] * len(pattern)i, j = 0, -1while i < len(pattern) - 1:if j == -1 or pattern[i] == pattern[j]:i += 1j += 1if pattern[i] != pattern[j]:next[i] = jelse:next[i] = next[j]else:j = next[j]return nextdef KMP(text, pattern):next = getNext(pattern)i, j = 0, 0while i < len(text) and j < len(pattern):if j == -1 or text[i] == pattern[j]:i += 1j += 1else:j = next[j]if j == len(pattern):return i - jelse:return -1# Example usage:
text = "ABCABCDABABCDABCDABDE"
pattern = "ABCDABD"
print("Pattern found at index:", KMP(text, pattern))
这段代码中,getNext 函数用于生成模式串的 next 数组,KMP 函数则是实现了KMP算法。在 KMP 函数中,通过不断移动模式串的位置,并根据 next 数组进行跳跃,以在主串中寻找匹配的子串。
- Boyer-Moore算法:Boyer-Moore算法采用了启发式的策略,在匹配过程中利用模式串中的信息进行跳跃式的移动。它的时间复杂度通常为O(m*n),但在实际中通常比KMP算法表现更好。
Boyer-Moore算法是一种用于字符串匹配的高效算法,它通过预处理模式串和文本串,利用字符比较的结果来跳过尽可能多的无效比较。下面是Boyer-Moore算法的C++代码实现:
#include <iostream>
#include <vector>
#include <string>using namespace std;// 构建坏字符规则表
void buildBadCharTable(const string& pattern vector<int>& badCharTable) {int m = pattern.length();for (int i = 0; i < 256; i++) {badCharTable[i] = m;}for (int i = 0; i < m - 1; i++) {badCharTable[pattern[i]] = m - 1 - i;}
}// 构建好后缀规则表
void buildGoodSuffixTable(const string& pattern, vector<int>& goodSuffixTable) {int m = pattern.length();vector<int> suffix(m, 0);goodSuffixTable.resize(m, m);// Case 1: 模式串的后缀与整个模式串匹配int j = 0;for (int i = m - 1; i >= 0; i--) {if (pattern[i] == pattern[j]) {suffix[i] = j + 1;j++;} else {suffix[i] = j;j = 0;}}// Case 2: 模式串的后缀是模式串的前缀for (int i = 0; i < m - 1; i++) {int len = m - suffix[i];goodSuffixTable[len] = m - 1 - i;}
}// Boyer-Moore算法
int boyerMoore(const string& text, const string& pattern) {int n = text.length();int m = pattern.length();vector<int> badCharTable(256, 0);vector<int> goodSuffixTable(m, m);buildBadCharTable(pattern, badCharTable);buildGoodSuffixTable(pattern, goodSuffixTable);int i = 0;while (i <= n - m) {int j = m - 1;while (j >= 0 && pattern[j] == text[i + j]) {j--;}if (j < 0) {return i; // 匹配成功,返回匹配的起始位置} else {int badCharShift = badCharTable[text[i + j]] - m + 1 + j;int goodSuffixShift = goodSuffixTable[m - j];i += max(badCharShift, goodSuffixShift);}}return -1; // 匹配失败,返回-1
}int main() {string text = "ABCDABDABCDABCD";string pattern = "ABCD";int pos = boyerMoore(text, pattern);if (pos != -1) {cout << "Pattern found at position: " << pos << endl;} else {cout << "Pattern not found." << endl;}return 0;
}