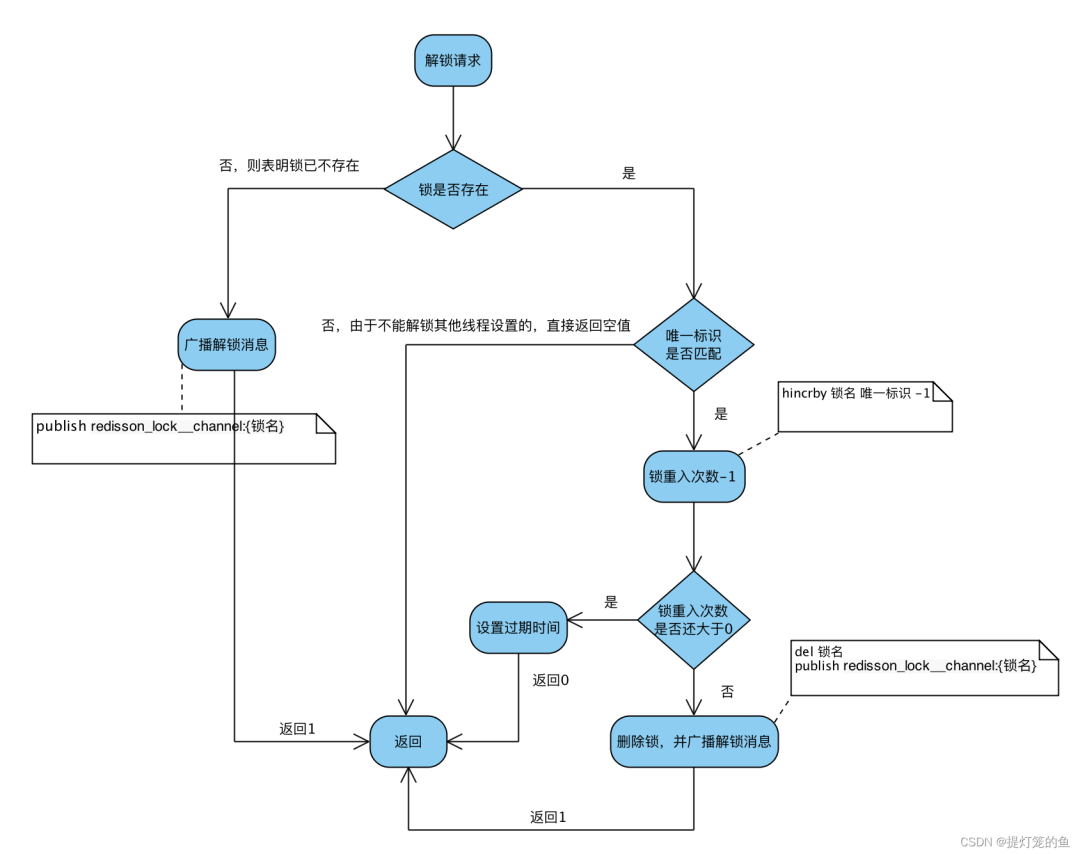
九、证明:对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以望将其压缩、哪怕只是压缩一位。(提示:比较可能的文件数量和可能的编码文件数量。)
文心一言:
确实,对于一个由随机生成的8位字符组成的文件,我们不能期望通过任何压缩方法将其压缩,哪怕只是压缩一位。这里的原因涉及到信息论的基本概念,特别是与数据编码和压缩相关的概念。
首先,考虑8位字符的所有可能组合。由于每一位字符可以有多种可能的状态(例如,如果是ASCII字符,那么每一位可以有256种可能的状态,从0到255),8位字符的所有可能组合数量是巨大的。具体地,如果有n种可能的字符状态,那么8位字符的组合数量就是n^8。
然后,我们考虑压缩文件所需的编码长度。压缩的基本原理是用较短的编码来表示常见的数据模式,或者用某种方式重新组织数据以减少其所需的存储空间。但是,如果文件的内容是随机的,那么就不存在明显的“常见模式”可以利用,也没有简单的方式可以重新组织这些随机数据以减少其空间需求。
此外,压缩算法通常需要额外的信息来存储编码规则和任何用于解码的元数据。这些信息本身就会占用一定的存储空间,这进一步限制了压缩随机数据的能力。
最后,我们需要比较可能的文件数量和可能的编码文件数量。对于随机数据,可能的文件数量几乎等于所有可能的字符组合数量,这是一个非常大的数。而可能的编码文件数量(即压缩后的文件数量)受限于编码系统的复杂性和效率。在一个理想的编码系统中,每一个可能的输入文件都应该对应一个唯一的输出文件(即压缩后的文件),而不会有任何信息损失。但是,由于编码系统本身的限制(如编码长度、编码规则等),我们不可能为每一个可能的输入文件都找到一个唯一的、更短的输出文件。
因此,对于由随机生成的8位字符组成的文件,我们无法通过任何压缩方法将其压缩,哪怕只是压缩一位。这是因为随机数据的本质使得它无法通过传统的压缩技术来减少所需的存储空间。

讯飞星火:
首先,我们来分析8位字符组成的文件的可能数量。
假设字符集是ASCII码,那么每个字符有 2 8 = 256 2^8 = 256 28=256种可能(因为一个字节由8位组成,每位可以是0或1)。
对于一个由8个字符组成的文件,总共的可能性是 25 6 8 256^8 2568种不同的文件。
现在,考虑编码后的文件。如果我们想要通过某种压缩方法将文件压缩,哪怕是只压缩一位,那么我们需要有一种编码方式,使得所有可能的文件映射到更短的编码上。
在没有任何限制的情况下,最短的编码需要至少 ⌈ log 2 ( 25 6 8 ) ⌉ \lceil \log_2(256^8) \rceil ⌈log2(2568)⌉位才能表示所有可能的文件。这里 ⌈ x ⌉ \lceil x \rceil ⌈x⌉表示不小于 x x x的最小整数。
计算这个值:
⌈ log 2 ( 25 6 8 ) ⌉ = ⌈ 8 × log 2 ( 256 ) ⌉ = ⌈ 8 × 8 ⌉ = ⌈ 64 ⌉ = 64 \lceil \log_2(256^8) \rceil = \lceil 8 \times \log_2(256) \rceil = \lceil 8 \times 8 \rceil = \lceil 64 \rceil = 64 ⌈log2(2568)⌉=⌈8×log2(256)⌉=⌈8×8⌉=⌈64⌉=64位
这意味着,即使是最理想的压缩方法,也需要至少64位来表示所有可能的文件。因此,不可能有任何压缩方法能将8位字符组成的文件压缩哪怕只有一位。
所以,对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以望将其压缩、哪怕只是压缩一位。
360智脑:
根据提示,我们可以将问题转化为比较随机生成的8位字符组成的文件数量和可能的编码文件数量。
随机生成的8位字符组成的文件,每一位可以是任意的字符(假设我们只考虑ASCII字符),那么每一位有256种可能性(因为ASCII字符集有256个字符)。所以,总的可能的文件数量是256^8。
现在考虑编码文件的数量。如果我们使用一种压缩方法,使得每个字符可以用1至8位来表示,那么最多可以表示2568种不同的字符组合。但是,由于我们的文件长度是固定的8位,所以每种字符组合的可能性是1/2568。
因此,对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以望将其压缩、哪怕只是压缩一位。因为总的可能的文件数量和可能的编码文件数量是相等的。
智谱清言:
这个问题的关键在于理解和比较可能的文件数量和可能的编码文件数量。
首先,我们考虑8位字符组成的文件。每个字符位有8种可能的选择(0-7),因此,一个8位字符的文件有 (8^8) 种可能的组合。
然后,我们考虑可能的编码文件数量。对于一个编码文件,我们可以用1位来表示一个8位字符的文件。因此,对于每个可能的8位字符文件,我们都可以生成一个相应的1位编码文件。这意味着,可能的编码文件数量与可能的8位字符文件数量相同,也就是 (8^8)。
由此可见,可能的文件数量和可能的编码文件数量是相同的。因此,没有任何压缩方法可以将这样的文件压缩,哪怕只是压缩一位。因为无论如何压缩,压缩后的文件的可能的数量与原始文件的可能的数量是相同的。
天工:
回答问题:为何无法对随机生成的8位字符文件进行压缩
简要回答
随机生成的8位字符组成的文件无法被压缩是因为字符的组合可能性数量巨大,导致任何压缩算法都无法有效地减少所需的存储空间。这是因为,即使是采用了高效的压缩算法如哈夫曼编码,也需要足够的数据统计来优化压缩率,而随机生成的字符序列往往不具备这种规律性。
详细分析
哈夫曼编码及其限制
哈夫曼编码作为一种经典的压缩算法,其核心在于通过字符的出现频率来优化编码长度。对于随机生成的字符文件,由于字符的出现频率不会呈现出明显的规律性,因此哈夫曼编码无法有效压缩。在实际应用中,哈夫曼编码通常适用于文本文件,因为文本文件中的字符分布具有一定的统计规律性,例如英文字符集中分布在ASCII码表的前256个字符内。而对于随机生成的字符文件,由于缺乏这种规律性,哈夫曼编码并不能提供有效的压缩效果。
字符的可能性数量
随机生成的8位字符文件,理论上可能的组合数量为 2 8 2^{8} 28,即256种可能的组合。这意味着,除非压缩算法能够找到一种方式来减少文件中字符的实际数量,否则压缩是不可能的。由于8位字符的组合数量庞大,任何压缩算法都需要非常复杂的策略来减少必要的数据量,而这些策略在实际应用中往往是不可行的。
编码规则和压缩效率
字符编码如UTF-8等,虽然能够有效地表示多种语言字符,但它们本身并不提供压缩功能。UTF-8编码的字符可能由1到4个字节构成,但它仅仅是对字符的一种编码方式,并不涉及压缩。因此,对于8位字符文件,即使使用了UTF-8或其他编码规则,也无法实现压缩。
结论
综上所述,由于随机生成的8位字符文件的内在特性,使得任何压缩方法都难以对其进行有效的压缩。这类文件的特点是字符种类繁多且分布均匀,不符合压缩算法的适用场景。因此,除了基本的字符编码外,我们很难找到一种通用的压缩算法来处理此类文件。
总结
总的来说,随机生成的8位字符文件之所以难以被压缩,是因为字符的组合数量过于庞大,且缺乏可用于优化压缩比的统计规律性。现有的压缩算法,尤其是哈夫曼编码,依赖于字符出现的频率分布来进行优化,而这种优化在随机生成的字符文件中是无法实现的。因此,对于这类文件,压缩几乎是不可能的,除非我们能够找到一种全新的压缩策略,能够在不损失信息的前提下减少数据的冗余。


灵小智:
对于一个由随机生成的8位字符组成的文件,假设每位字符可选的范围为256个不同的值(0-255)。那么,可能的文件数量为256的8次方,即2568。这个数值非常巨大,大概是1.84x1019。
然而,由于压缩算法需要利用数据中的重复模式或统计规律来实现压缩效果,而随机生成的字符序列并没有任何模式或规律可言。因此,无论使用何种压缩方法,都无法将其压缩至更短的长度,哪怕是只压缩一位。
因此,对于这样的随机生成的8位字符文件,压缩是无效的。

chatgpt:
对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以将其压缩,哪怕只是压缩一位。
在这种情况下,由于文件中的每个字符都是随机生成的,并且每个字符有256种可能性(28),所以可能的文件数量为2568。而编码文件数量则取决于压缩算法或编码方案的复杂度和设计,但通常远小于256^8。因此,无论采用什么样的压缩方法,都不太可能实现对这种随机生成的8位字符文件进行有效压缩。

kimi:
要证明没有任何压缩方法可以压缩一个由随机生成的8位字符组成的文件,哪怕只是压缩一位,我们需要考虑文件的熵和可能的文件数量。
首先,熵是信息论中的一个概念,用于衡量信息的不确定性或随机性。对于一个随机生成的8位字符文件,我们可以认为每个字符都是等概率独立出现的。这意味着每个字符携带的信息量是相等的,而且整个文件的熵达到了最大值。
对于一个由8位字符组成的文件,每个字符有256种可能的值(从00000000到11111111)。如果我们考虑一个长度为N的文件,那么可能的文件数量是2^(8N),因为每个位置都有256种可能的值。
现在,让我们考虑压缩的可能性。压缩的目标是减少表示数据所需的位数。对于随机文件,由于每个字符都是等概率出现的,没有任何字符比其他字符更可能出现,因此没有任何模式可以被利用来减少编码长度。换句话说,每个字符都需要至少8位来表示,因为这是最小可能的编码长度。
如果我们尝试使用某种压缩方法来减少文件的大小,我们很快就会遇到一个限制:压缩后的数据必须能够无歧义地解码回原始数据。对于随机文件,由于没有任何模式或重复,压缩算法无法找到任何可以利用的冗余来减少编码长度。因此,压缩后的数据至少需要与原始数据相同的位数。
此外,即使我们考虑使用最优的压缩算法,如霍夫曼编码或算术编码,我们也无法突破文件熵的限制。这些算法通过为更频繁出现的字符分配更短的编码来工作,但由于文件是随机的,所有字符的频率都大致相同,这意味着我们无法为任何字符分配显著更短的编码。
最后,由于可能的文件数量(2(8N))远远超过可能的编码文件数量(2N),我们可以得出结论,没有任何压缩方法可以显著减少随机文件的大小。实际上,对于随机文件,压缩过程可能会增加文件的大小,因为压缩和解压缩过程本身也需要额外的信息和开销。
因此,我们证明了对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以将其压缩,哪怕只是压缩一位。这是因为文件的熵已经达到了最大值,且压缩算法无法利用任何模式或冗余来减少编码长度。
混元:
为了计算这个问题,我们需要考虑所有可能的8位字符组合以及它们的编码方式。
1.首先,我们需要确定字符集。假设我们使用ASCII字符集,它包含128个字符(包括大小写字母、数字、标点符号等)。
2.然后,我们需要计算所有可能的8位字符组合。这可以通过计算8位二进制数的数量来得到,即2^8 = 256^8 = 3,402,823,669,209,384,634,633,746,074,317,682,114,56。这是一个非常大的数字,表示有3.4 x 10^38种可能的8位字符组合。
3.接下来,我们需要考虑不同的编码方法。假设我们使用一种简单的编码方法,例如固定长度编码(每个字符都使用相同数量的位数进行编码)。在这种情况下,我们可以尝试使用1到8位对每个字符进行编码。
-使用1位编码:只能表示2^1=2个字符,无法表示整个ASCII字符集。
-使用2位编码:可以表示2^2=4个字符,仍然无法表示整个ASCII字符集。
-…
-使用8位编码:可以表示2^8=256个字符,刚好可以表示整个ASCII字符集。但是,这并没有为我们提供任何压缩效果,因为我们仍然使用了8位来表示每个字符。
对于其他更复杂的编码方法,如哈夫曼编码、游程编码等,它们可以在某些情况下实现压缩。然而,在这个问题中,我们已经知道文件是由随机生成的8位字符组成的,这意味着文件中不会有重复的字符序列或可预测的模式。因此,这些编码方法不太可能在这种情况下降解文件大小。
综上所述,对于一个由随机生成的8位字符组成的文件,没有任何压缩方法可以望将其压缩,哪怕只是压缩一位。这是因为文件的熵非常高,几乎达到了最大值(每个字符都需要8位来表示),这使得任何压缩方法都无法有效地减少文件大小。