引言
处理读写是Pulsar服务端最基本也是最重要的逻辑,今天就重点看看服务端是如何处理的读请求也就是消费者请求
正文
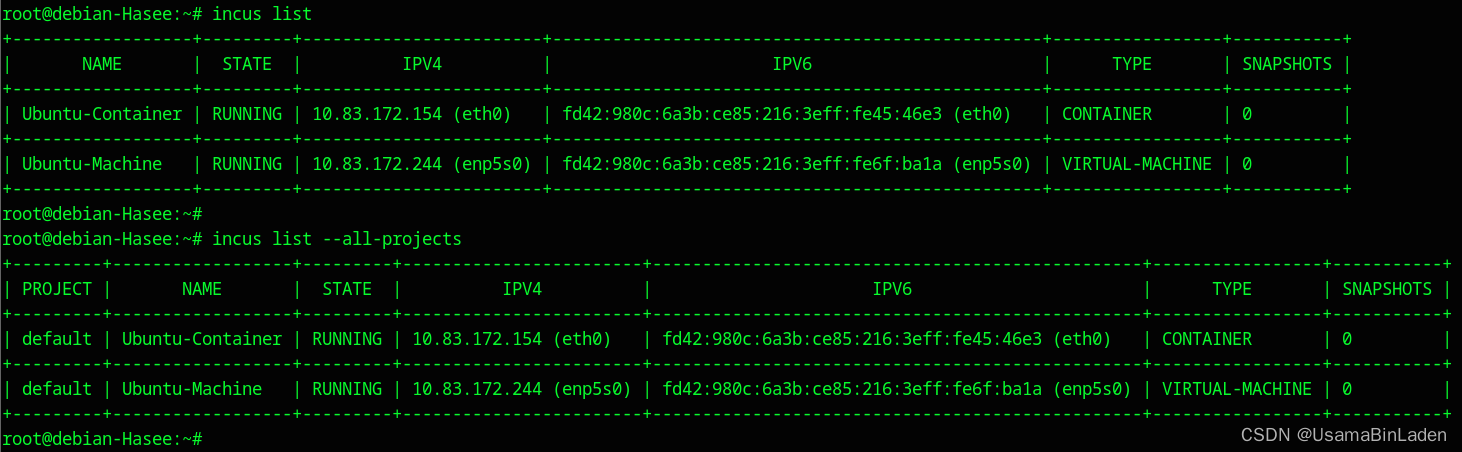
Pulsar服务端处理消费者请求的流程大致如下图所示

- 消费者通过TCP向服务端发起消息拉取请求
- Broker会根据请求中携带的ID来获取在服务端对应的Consumer对象,每个Consumer对象都有一个对应的游标对象,这个游标对象会调用Dispatcher来做数据查询的操作
- Dispatcher会先尝试读取缓存,这个缓存是个跳表结构并且节点数据是存在堆外内存中的,如果命中则直接返回
- 未命中缓存的话会通过Bookkeeper客户端去读取Bookkeeper中的数据,读取到后会通过跟客户端所建立的TCP连接将查到的数据发送过去
整体流程就是这四步,接下来就让咱们看看Pulsar的代码实现吧
处理消费请求
Broker处理的请求基本都是从ServerCnx这里开始的,因为它实现了Netty的ChannelInboundHandlerAdapter类,因此所有TCP的数据写进来时最终都是ServerCnx进行处理的,处理消费的请求时从handleFlow方法开始,因此从这里进行跟踪
protected void handleFlow(CommandFlow flow) {....//从当前Broker维护的Consumer列表中获取客户端对应服务端的Consumer对象CompletableFuture<Consumer> consumerFuture = consumers.get(flow.getConsumerId());if (consumerFuture != null && consumerFuture.isDone() && !consumerFuture.isCompletedExceptionally()) {Consumer consumer = consumerFuture.getNow(null);if (consumer != null) {//传入客户端配置的拉取条数,最大默认不会超过1000consumer.flowPermits(flow.getMessagePermits());} else {log.info("[{}] Couldn't find consumer {}", remoteAddress, flow.getConsumerId());}}}public void flowPermits(int additionalNumberOfMessages) {....// 处理消息拉取请求,继续跟进去看看subscription.consumerFlow(this, additionalNumberOfMessages);}public void consumerFlow(Consumer consumer, int additionalNumberOfMessages) {this.lastConsumedFlowTimestamp = System.currentTimeMillis();//最终调用者是dispatcherdispatcher.consumerFlow(consumer, additionalNumberOfMessages);}
Dispatcher是个接口,在这里选择PersistentDispatcherSingleActiveConsumer的实现进行跟踪
public void consumerFlow(Consumer consumer, int additionalNumberOfMessages) {//作为一个任务交给线程池处理executor.execute(() -> internalConsumerFlow(consumer));}private synchronized void internalConsumerFlow(Consumer consumer) {//进行消息的读取readMoreEntries(consumer);}private void readMoreEntries(Consumer consumer) {....//通过游标进行数据的读取cursor.asyncReadEntriesOrWait(messagesToRead,bytesToRead, this, readEntriesCtx, topic.getMaxReadPosition());}
PersistentDispatcherSingleActiveConsumer最终会调用ManagedCursorImpl进行数据的读取,这里要注意PersistentDispatcherSingleActiveConsumer实现了回调接口,也就是它自身实现了数据读取成功的处理逻辑。这里它将自己作为参数传给下一层用于在读取成功后进行回调处理,这也是最常见的异步回调设计方式。
继续跟踪ManagedCursorImpl的数据读取逻辑
public void asyncReadEntriesOrWait(int maxEntries, long maxSizeBytes, ReadEntriesCallback callback, Object ctx, PositionImpl maxPosition) {asyncReadEntriesWithSkipOrWait(maxEntries, maxSizeBytes, callback, ctx, maxPosition, null);}public void asyncReadEntriesWithSkipOrWait(int maxEntries, long maxSizeBytes, ReadEntriesCallback callback,Object ctx, PositionImpl maxPosition,Predicate<PositionImpl> skipCondition) {....// 读取数据asyncReadEntriesWithSkip(numberOfEntriesToRead, NO_MAX_SIZE_LIMIT, callback, ctx,maxPosition, skipCondition);}public void asyncReadEntriesWithSkip(int numberOfEntriesToRead, long maxSizeBytes, ReadEntriesCallback callback,Object ctx, PositionImpl maxPosition, Predicate<PositionImpl> skipCondition) {// 封装第二层回调OpReadEntry op =OpReadEntry.create(this, readPosition, numOfEntriesToRead, callback, ctx, maxPosition, skipCondition);//核心方法,从这里进去读取ledger.asyncReadEntries(op);
}void asyncReadEntries(OpReadEntry opReadEntry) {....internalReadFromLedger(currentLedger, opReadEntry);....}private void internalReadFromLedger(ReadHandle ledger, OpReadEntry opReadEntry) {....// 进行数据读取asyncReadEntry(ledger, firstEntry, lastEntry, opReadEntry, opReadEntry.ctx);}protected void asyncReadEntry(ReadHandle ledger, long firstEntry, long lastEntry, OpReadEntry opReadEntry,Object ctx) {if (config.getReadEntryTimeoutSeconds() > 0) {....// 封装第三层回调ReadEntryCallbackWrapper readCallback = ReadEntryCallbackWrapper.create(name, ledger.getId(), firstEntry,opReadEntry, readOpCount, createdTime, ctx);lastReadCallback = readCallback;// 尝试从缓存中读取数据,继续跟踪进去entryCache.asyncReadEntry(ledger, firstEntry, lastEntry, opReadEntry.cursor.isCacheReadEntry(),readCallback, readOpCount);} else {entryCache.asyncReadEntry(ledger, firstEntry, lastEntry, opReadEntry.cursor.isCacheReadEntry(), opReadEntry,ctx);}}
entryCache有RangeEntryCacheImpl和EntryCacheDisabled两种实现,EntryCacheDisabled相当于不走缓存直接查Bookkeeper,而RangeEntryCacheImpl是会尝试去读取Broker自身的缓存,这里跟着RangeEntryCacheImpl看看实现
public void asyncReadEntry(ReadHandle lh, long firstEntry, long lastEntry, boolean shouldCacheEntry,final ReadEntriesCallback callback, Object ctx) {//跟进去看asyncReadEntry0(lh, firstEntry, lastEntry, shouldCacheEntry, callback, ctx);}void asyncReadEntry0(ReadHandle lh, long firstEntry, long lastEntry, boolean shouldCacheEntry,final ReadEntriesCallback callback, Object ctx) {//一样,继续跟踪看asyncReadEntry0WithLimits(lh, firstEntry, lastEntry, shouldCacheEntry, callback, ctx, null);}void asyncReadEntry0WithLimits(ReadHandle lh, long firstEntry, long lastEntry, boolean shouldCacheEntry,final ReadEntriesCallback originalCallback, Object ctx, InflightReadsLimiter.Handle handle) {....// 缓存实现是ConcurrentSkipListMap value是堆外内存Collection<EntryImpl> cachedEntries = entries.getRange(firstPosition, lastPosition);....//如果全部命中缓存则直接返回,否则往下走// 从bookkeeper读pendingReadsManager.readEntries(lh, firstEntry, lastEntry,shouldCacheEntry, callback, ctx);}void readEntries(ReadHandle lh, long firstEntry, long lastEntry, boolean shouldCacheEntry,final AsyncCallbacks.ReadEntriesCallback callback, Object ctx) {....//从Bookkeeper进行数据的读取CompletableFuture<List<EntryImpl>> readResult = rangeEntryCache.readFromStorage(lh, firstEntry,lastEntry, shouldCacheEntry);}CompletableFuture<List<EntryImpl>> readFromStorage(ReadHandle lh,long firstEntry, long lastEntry, boolean shouldCacheEntry) {....//这里的lh其实就是Bookkeeper的客户端对象LedgerHandleCompletableFuture<List<EntryImpl>> readResult = lh.readAsync(firstEntry, lastEntry)....}
到这里基本就到了Bookkeeper的内部逻辑了,Bookkeeper相关的后面在单独进行分析。读取逻辑基本就到这了,肯定会有伙伴疑惑🤔,读到数据后怎么将数据发给客户端/消费者呢?请继续往下看
回调处理
刚刚进行代码跟踪的时候应该都看到流程中封住了好几个回调函数,这里就拎最重要的也就是PersistentDispatcherSingleActiveConsumer进行讨论,这里直接从它的回调方法readEntriesComplete进行跟踪
public void readEntriesComplete(final List<Entry> entries, Object obj) {//作为任务放到线程池去执行executor.execute(() -> internalReadEntriesComplete(entries, obj));}private synchronized void internalReadEntriesComplete(final List<Entry> entries, Object obj) {....//分派数据到消费者dispatchEntriesToConsumer(currentConsumer, entries, batchSizes, batchIndexesAcks, sendMessageInfo, epoch);}protected void dispatchEntriesToConsumer(Consumer currentConsumer, List<Entry> entries,EntryBatchSizes batchSizes, EntryBatchIndexesAcks batchIndexesAcks,SendMessageInfo sendMessageInfo, long epoch) {//将查到的消息通过TCP写到消费者端currentConsumer.sendMessages(entries, batchSizes, batchIndexesAcks, sendMessageInfo.getTotalMessages(),sendMessageInfo.getTotalBytes(), sendMessageInfo.getTotalChunkedMessages(),redeliveryTracker, epoch)....}public Future<Void> sendMessages(final List<? extends Entry> entries, EntryBatchSizes batchSizes,EntryBatchIndexesAcks batchIndexesAcks,int totalMessages, long totalBytes, long totalChunkedMessages,RedeliveryTracker redeliveryTracker, long epoch) {....//通过PulsarCommandSenderImpl进行消息发送,继续跟踪进去Future<Void> writeAndFlushPromise = cnx.getCommandSender().sendMessagesToConsumer(....);....}public ChannelPromise sendMessagesToConsumer(....) {....//通过Netty的TCP将查到的消息数据写到客户端ctx.write(....);....}
到这里基本上服务端的事情就结束了,剩余的其他几个回调函数感兴趣的伙伴可以自行跟踪。
总结
可以看到Pulsar里大量使用了异步回调处理,这样的设计在高并发场景大幅提升服务的性能,尽可能的避免了存在瓶颈的地方。不过带来的另一影响是,代码跟踪起来相对来说容易“迷路”,因此掌握好异步设计的逻辑是很有必要的,可以帮助我们更好的跟踪Pulsar的代码。