通过nvtx和Nsight Compute分析pytorch算子的耗时
- 一.效果
- 二.代码
本文演示了如何借助nvtx和Nsight Compute分析pytorch算子的耗时
一.效果
- 第一次执行,耗时很长
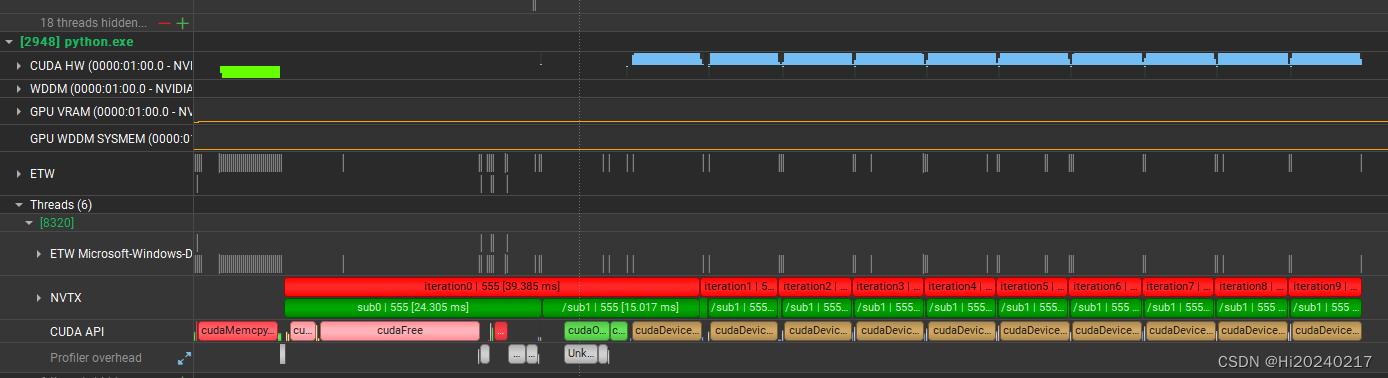
- 小规模的matmul,调度耗时远大于算子本身
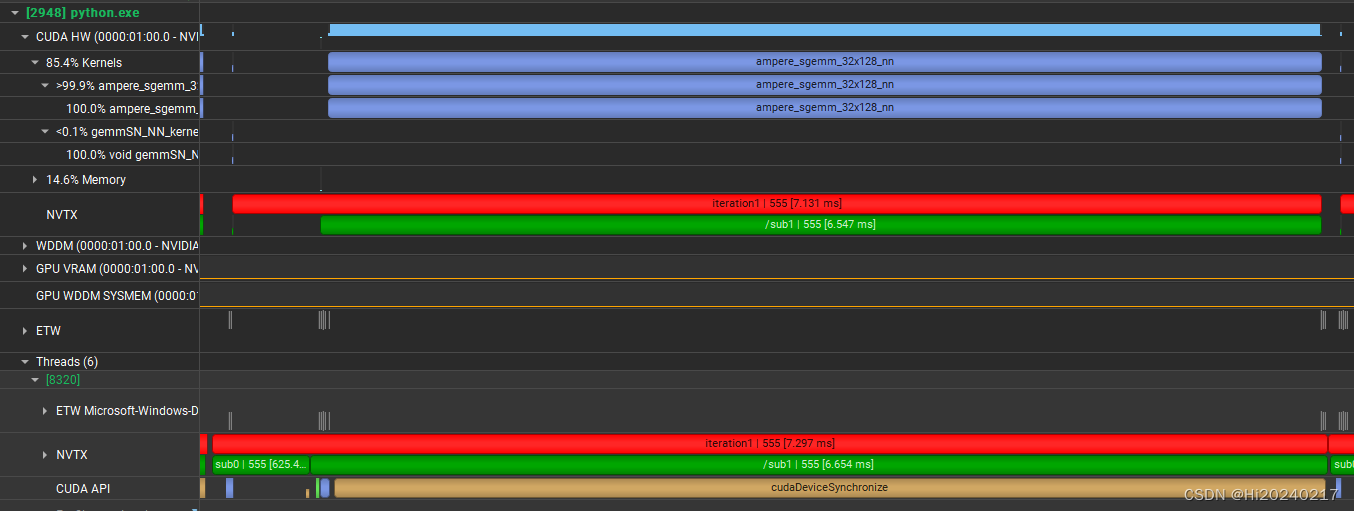
- 大规模的matmul,对资源的利用率高

- 小规模matmul,各层调用的耗时
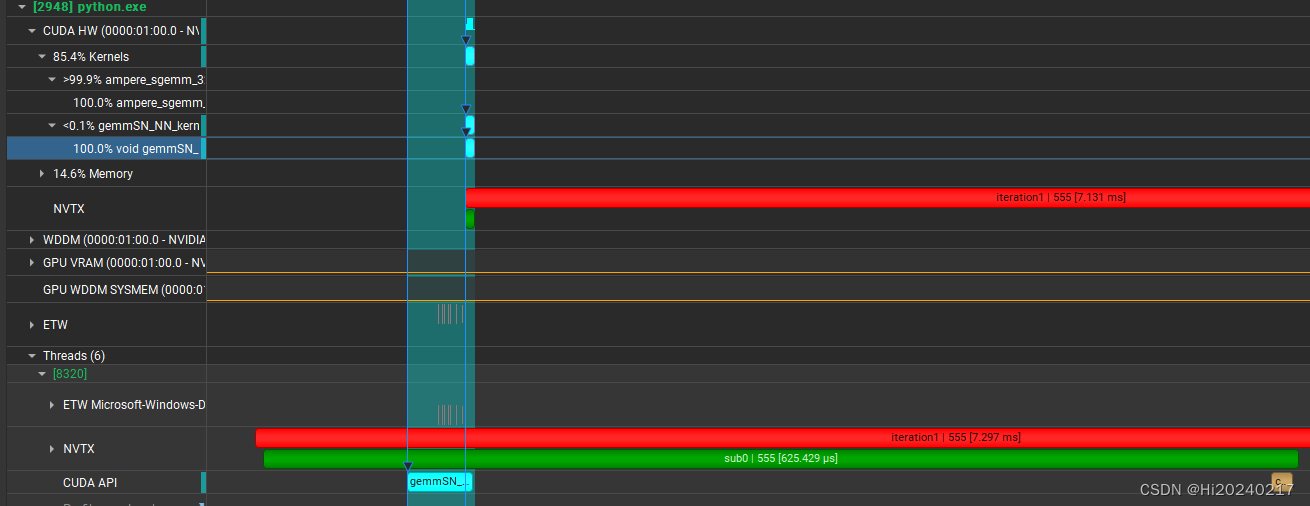
二.代码
import torch
import nvtx# 二种不同规模矩阵乘的耗时,通过小算子可以看到调度的耗时
A=torch.ones((3,4),dtype=torch.float32).to('cuda:0')
B=torch.ones((4,5),dtype=torch.float32).to('cuda:0')C=torch.ones((1024,8196),dtype=torch.float32).to('cuda:0')
D=torch.ones((8196,1024),dtype=torch.float32).to('cuda:0')#torch.cuda.cudart().cudaProfilerStart()
for i in range(10):#torch.cuda.nvtx.range_push(f"iteration{i}")with nvtx.annotate(f"iteration{i}", color="red"):with nvtx.annotate(f"sub0", color="green"):OUT0=torch.matmul(A,B)torch.cuda.synchronize()with nvtx.annotate(f"sub1", color="green"):OUT1=torch.matmul(C,D)torch.cuda.synchronize()#torch.cuda.nvtx.range_pop()
#torch.cuda.cudart().cudaProfilerStop()