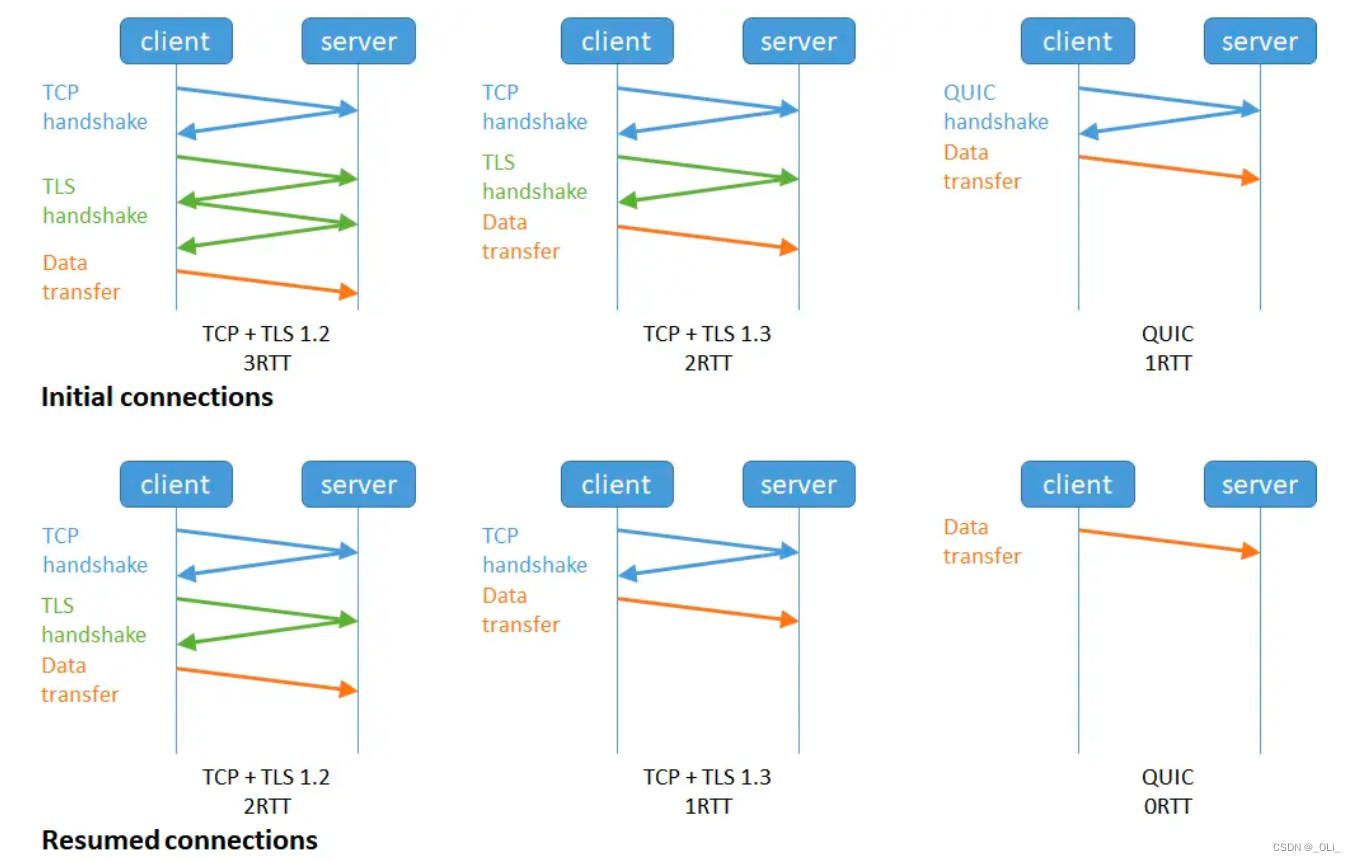
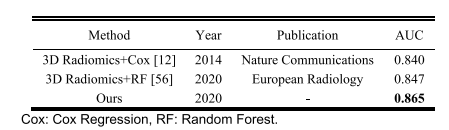
LLMs之DBRX:DBRX的简介、安装和使用方法、案例应用之详细攻略
导读:2024年3月27日(美国时间),DBRX是Databricks推出的一款新型开源大语言模型,主要特征和优势总结如下:
>> 表现优异:DBRX在各类自然语言处理benchmark上的表现超越现有主流开源模型,如Mixtral、LLaMA等。特别是在编程领域和数学计算领域表现显著优于同类型模型。
>> 模型规模:总参数量132B,活跃参数量36B。
>> 预训练数据量:12T个字符 token,最大上下文长度32K个token。DBRX能够处理上下文长度为32K个标记,在长文解答任务和RAG任务上表现好于GPT-3.5。
>> 网络结构:采用精细粒度混合专家(MoE)结构,每个专家包含的参数数量小于Dense结构。DBRX包含16个专家,每次选择4个专家,提供比Mixtral和Grok-1更多的65倍可能结合方式。
>> 训练效率:与dense结构相比,MoE结构可以提高训练效率2倍以上。DBRX家族模型DBRX MoE-B采用MoE结构,训练FLOPs较LLaMA2-13B少1.7倍就达到相近质量。DBRX可以用4分之1的计算资源达到之前模型的水平。
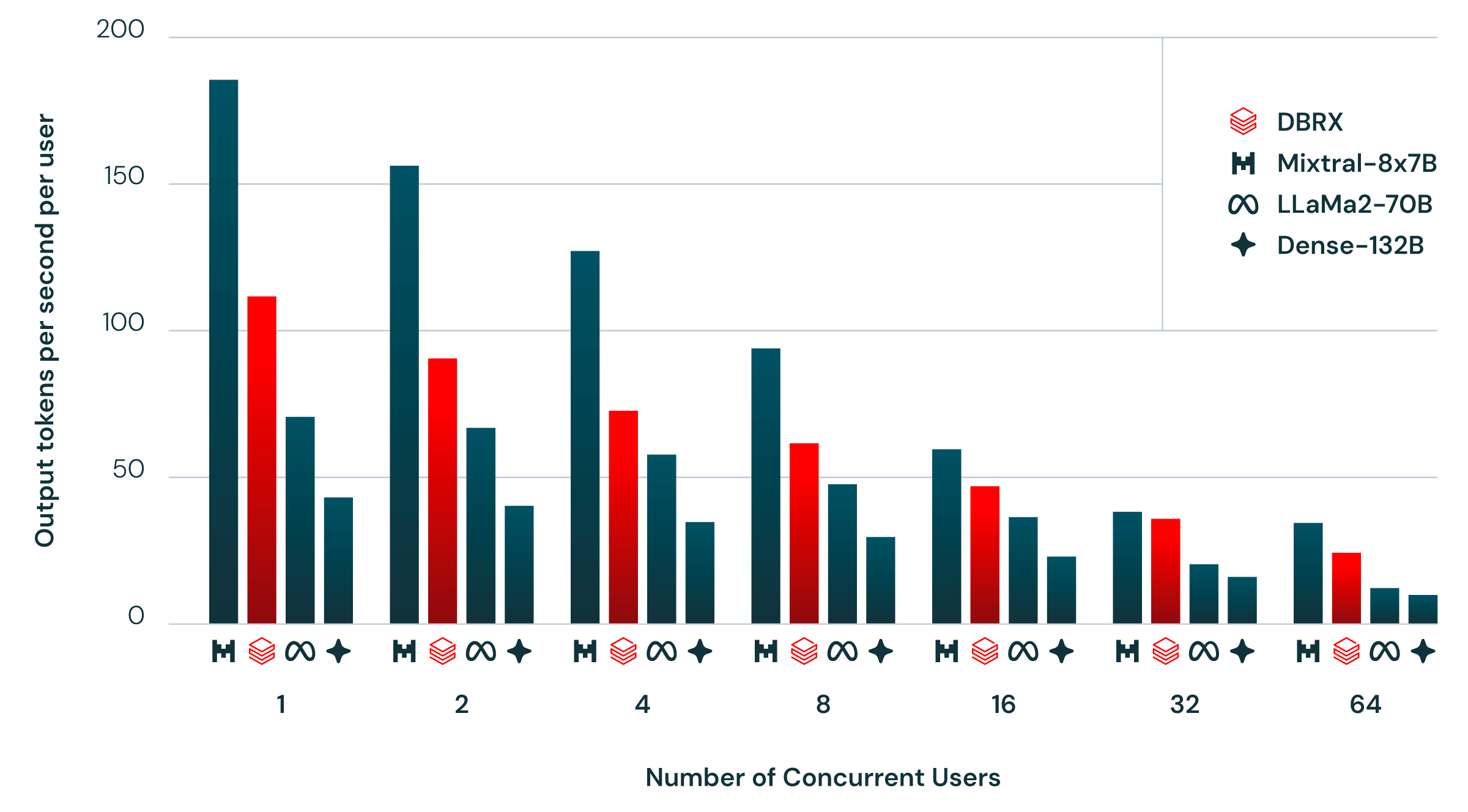
>> 推理性能:与总参数量132B对应的dense模型相比,DBRX的推理吞吐率快2-3倍。在Databricks优化的serving环境下,单个用户每秒支持的 token数达150个。
>> 参数利用率:相比总参数量,DBRX在每个输入下仅利用约36B或27%的参数。这使其在给定模型质量下推理更高效。
>> 开放性好:DBRX模型及训练序列全部开源共享,Databricks也发布了相应工具供用户重复训练和应用DBRX。
>> 商业可行:Databricks提供DBRX在线API服务和定制训练服务,满足企业实时查询和专属模型训练需求。
总体来说,DBRX继承并提升了Databricks在开放LLM研发和应用方面的先进经验,在模型性能、效率和可商业应用性方面都达到新水平,为企业提供了一款强大且开放的通用语言模型工具。
目录
DBRX的简介
1、模型详情
2、模型性能
图1:DBRX在语言理解(MMLU)、编程(HumanEval)和数学(GSM8K)等方面优于已建立的开源模型
表1显示了DBRX Instruct和领先的已建立的开源模型的质量。DBRX Instruct在复合基准、编程和数学基准以及MMLU方面是领先的模型。它超越了所有标准基准上的聊天或指导微调模型。
表2显示了DBRX Instruct和领先的封闭模型的质量。根据每个模型创建者报告的得分,DBRX Instruct超越了GPT-3.5(如GPT-4论文中所述),并且与Gemini 1.0 Pro和Mistral Medium竞争。
表3.模型在KV-Pairs和HotpotQAXL基准上的平均性能。 粗体是最高分。 下划线是除了GPT-4 Turbo之外的最高分。 GPT-3.5 Turbo支持的最大上下文长度为16K,因此我们无法在32K上评估它。 * GPT-3.5 Turbo的开始、中间和结尾的平均值仅包括最多16K的上下文。
表4.模型在给定来自使用bge-large-en-v1.5的维基百科语料库中的前10个段落时的性能。 精度是通过与模型答案匹配来衡量。 粗体是最高分。 下划线是除了GPT-4 Turbo之外的最高分。
表5.我们用来验证DBRX MoE架构和端到端训练流程的训练效率的几个测试文章的详细信息
图2显示了使用NVIDIA TensorRT-LLM和我们的优化服务基础设施以及16位精度为DBRX和类似模型提供端到端推理效率。 我们的目标是使此基准尽可能地反映现实世界的使用情况,包括多个用户同时击中相同的推理服务器。 我们每秒生成一个新用户,每个用户请求包含大约2000个标记提示,并且每个响应包含256个标记。
3、模型特点
DBRX的安装和使用方法
1、下载权重
2、快速开始
T1、直接运行
T2、采用LLM Foundry
T3、Docker镜像
3、推理
T1、TensorRT-LLM
T2、vLLM
4、微调
DBRX的案例应用
DBRX的简介
2024年3月27日(美国时间),DBRX是Databricks开发的一款开放源码的 Transformer 结构的大规模语言模型,它使用了混合专家(MoE) 架构,总参数量为132B,活跃参数为36B。DBRX经过12兆字训练数据预训练,相比先前开源大模型具有质量和效率双赢。DBRX是一款强大且高效的开放源码模型,Databricks也提供了完整的工具链和服务支持用户高效应用和研发。
这一最先进的质量带来了在训练和推理性能方面的显著改进。DBRX通过其细粒度的专家混合(MoE)架构在开放模型中推进了效率的最新水平。推理速度比LLaMA2-70B快了多达2倍,而且DBRX的大小约为Grok-1的40%,无论是在总参数数量还是活跃参数数量上。当部署在Mosaic AI Model Serving上时,DBRX可以以每个用户150个tok/s的速度生成文本。我们的客户将发现,相同质量的模型训练MoEs的效率也比训练密集模型高出约2倍。从端到端来看,我们对DBRX的整体配方(包括预训练数据、模型架构和优化策略)几乎可以用近4倍的计算量来匹配我们以前一代的MPT模型的质量。
官网:Introducing DBRX: A New State-of-the-Art Open LLM | Databricks
GitHub地址:GitHub - databricks/dbrx: Code examples and resources for DBRX, a large language model developed by Databricks
1、模型详情
DBRX是一个具有1320亿总参数和360亿实时参数的专家混合模型(MoE)。我们使用16个专家,其中4个在训练或推理期间处于活动状态。DBRX经过了12T文本标记的预训练。DBRX的上下文长度为32K个标记。
2、模型性能
DBRX在综合评测、编程和数学任务上优于目前开放源码模型,且与商业闭源模型如GPT-3.5水平相当。它在长文本场景和关联生成任务上也表现出色。
在一系列标准基准测试中,DBRX创造了新的开源LLM技术水平。此外,它为开放社区和构建自己LLM的企业提供了之前仅限于封闭模型API的功能;根据我们的测量,它超越了GPT-3.5,并且在与Gemini 1.0 Pro竞争中保持竞争力。作为一款特别强大的代码模型,它不仅在编程方面超越了像CodeLLaMA-70B这样的专业模型,而且在作为通用型LLM方面也很有优势。
图1:DBRX在语言理解(MMLU)、编程(HumanEval)和数学(GSM8K)等方面优于已建立的开源模型
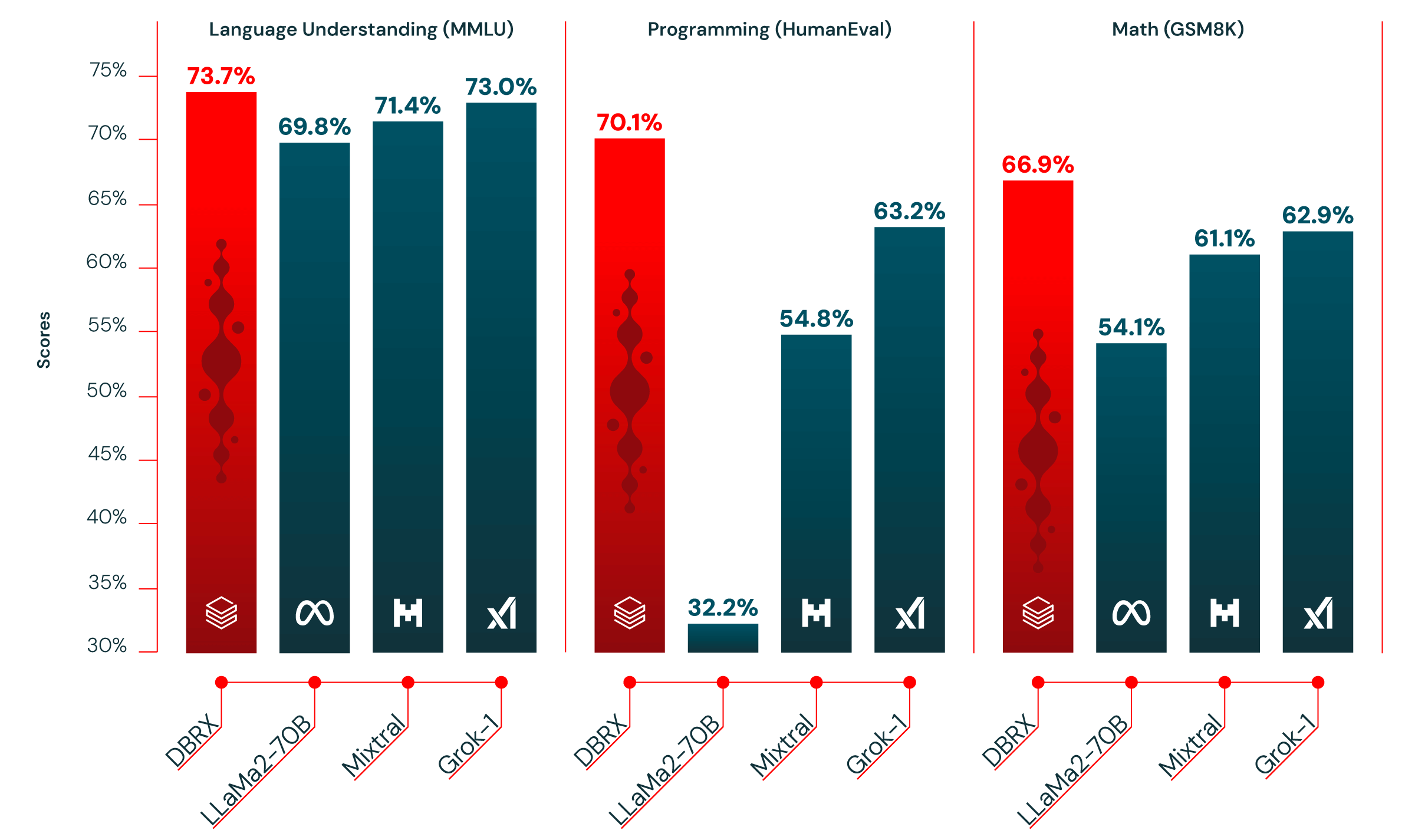
表1显示了DBRX Instruct和领先的已建立的开源模型的质量。DBRX Instruct在复合基准、编程和数学基准以及MMLU方面是领先的模型。它超越了所有标准基准上的聊天或指导微调模型。
| Model | DBRX Instruct | Mixtral Instruct | Mixtral Base | LLaMA2-70B Chat | LLaMA2-70B Base | Grok-11 |
| Open LLM Leaderboard2 (Avg of next 6 rows) | 74.5% | 72.7% | 68.4% | 62.4% | 67.9% | — |
| ARC-challenge 25-shot | 68.9% | 70.1% | 66.4% | 64.6% | 67.3% | — |
| HellaSwag 10-shot | 89.0% | 87.6% | 86.5% | 85.9% | 87.3% | — |
| MMLU 5-shot | 73.7% | 71.4% | 71.9% | 63.9% | 69.8% | 73.0% |
| Truthful QA 0-shot | 66.9% | 65.0% | 46.8% | 52.8% | 44.9% | — |
| WinoGrande 5-shot | 81.8% | 81.1% | 81.7% | 80.5% | 83.7% | — |
| GSM8k CoT 5-shot maj@13 | 66.9% | 61.1% | 57.6% | 26.7% | 54.1% | 62.9% (8-shot) |
| Gauntlet v0.34 (Avg of 30+ diverse tasks) | 66.8% | 60.7% | 56.8% | 52.8% | 56.4% | — |
| HumanEval5 0-Shot, pass@1 (Programming) | 70.1% | 54.8% | 40.2% | 32.2% | 31.0% | 63.2% |
表2显示了DBRX Instruct和领先的封闭模型的质量。根据每个模型创建者报告的得分,DBRX Instruct超越了GPT-3.5(如GPT-4论文中所述),并且与Gemini 1.0 Pro和Mistral Medium竞争。
| Model | DBRX | GPT-3.57 | GPT-48 | Claude 3 Haiku | Claude 3 Sonnet | Claude 3 Opus | Gemini 1.0 Pro | Gemini 1.5 Pro | Mistral Medium | Mistral Large |
| MT Bench (Inflection corrected, n=5) | 8.39 ± 0.08 | — | — | 8.41 ± 0.04 | 8.54 ± 0.09 | 9.03 ± 0.06 | 8.23 ± 0.08 | — | 8.05 ± 0.12 | 8.90 ± 0.06 |
| MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
| HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
| HumanEval 0-Shot | 70.1% temp=0, N=1 | 48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
| GSM8k CoT maj@1 | 72.8% (5-shot) | 57.1% (5-shot) | 92.0% (5-shot) | 88.9% | 92.3% | 95.0% | 86.5% (maj1@32) | 91.7% (11-shot) | 66.7% (5-shot) | 81.0% (5-shot) |
| WinoGrande 5-shot | 81.8% | 81.6% | 87.5% | — | — | — | — | — | 88.0% | 86.7% |
表3.模型在KV-Pairs和HotpotQAXL基准上的平均性能。 粗体是最高分。 下划线是除了GPT-4 Turbo之外的最高分。 GPT-3.5 Turbo支持的最大上下文长度为16K,因此我们无法在32K上评估它。 * GPT-3.5 Turbo的开始、中间和结尾的平均值仅包括最多16K的上下文。
| Model | DBRX Instruct | Mixtral Instruct | GPT-3.5 Turbo (API) | GPT-4 Turbo (API) |
| Answer in Beginning Third of Context | 45.1% | 41.3% | 37.3%* | 49.3% |
| Answer in Middle Third of Context | 45.3% | 42.7% | 37.3%* | 49.0% |
| Answer in Last Third of Context | 48.0% | 44.4% | 37.0%* | 50.9% |
| 2K Context | 59.1% | 64.6% | 36.3% | 69.3% |
| 4K Context | 65.1% | 59.9% | 35.9% | 63.5% |
| 8K Context | 59.5% | 55.3% | 45.0% | 61.5% |
| 16K Context | 27.0% | 20.1% | 31.7% | 26.0% |
| 32K Context | 19.9% | 14.0% | — | 28.5% |
表4.模型在给定来自使用bge-large-en-v1.5的维基百科语料库中的前10个段落时的性能。 精度是通过与模型答案匹配来衡量。 粗体是最高分。 下划线是除了GPT-4 Turbo之外的最高分。
| Model | DBRX Instruct | Mixtral Instruct | LLaMa2-70B Chat | GPT 3.5 Turbo (API) | GPT 4 Turbo (API) |
| Natural Questions | 60.0% | 59.1% | 56.5% | 57.7% | 63.9% |
| HotPotQA | 55.0% | 54.2% | 54.7% | 53.0% | 62.9% |
表5.我们用来验证DBRX MoE架构和端到端训练流程的训练效率的几个测试文章的详细信息
| Model | Total Params | Active Params | Gauntlet Score | Relative FLOPs |
| DBRX MoE-A | 7.7B | 2.2B | 30.5% | 1x |
| MPT-7B (1T tokens) | — | 6.7B | 30.9% | 3.7x |
| DBRX Dense-A (1T tokens) | — | 6.7B | 39.0% | 3.7x |
| DBRX Dense-A (500B tokens) | — | 6.7B | 32.1% | 1.85x |
| DBRX MoE-B | 23.5B | 6.6B | 45.5% | 1x |
| LLaMA2-13B | — | 13.0B | 43.8% | 1.7x |
图2显示了使用NVIDIA TensorRT-LLM和我们的优化服务基础设施以及16位精度为DBRX和类似模型提供端到端推理效率。 我们的目标是使此基准尽可能地反映现实世界的使用情况,包括多个用户同时击中相同的推理服务器。 我们每秒生成一个新用户,每个用户请求包含大约2000个标记提示,并且每个响应包含256个标记。
3、模型特点
使用细粒度MoE结构,训练和推理效率比 Dense 模型高2-3倍
相对于同类型模型参数数量下,DBRX推理吞吐更高
预训练数据和训练方法得到优化,使效率提升近4倍
DBRX的安装和使用方法
可以从Databricks Marketplace下载DBRX模型,并在Databricks Model Serving平台上部署使用。也可以通过Databricks提供的基金会模型API在线查询模型。对于生产场景,Databricks提供了吞吐保证版本。
DBRX基础模型(DBRX Base)和微调模型(DBRX Instruct)的权重可在Hugging Face上以开放许可证获取。从今天开始,DBRX可供Databricks的客户通过API使用,Databricks的客户可以从头开始预训练自己的DBRX类模型,或者使用我们用于构建它的相同工具和科学在我们的检查点之一上继续训练。DBRX已经被集成到我们的GenAI驱动产品中,其中-在诸如SQL之类的应用程序中-早期的推出已经超越了GPT-3.5 Turbo,并且正在挑战GPT-4 Turbo。它还是RAG任务中开放模型和GPT-3.5 Turbo的领先模型之一。
DBRX是由Databricks训练的大型语言模型,并在开放许可下提供。该存储库包含了运行推理所需的最小代码和示例,以及一系列用于使用DBRX的资源和链接。
HuggingFace:https://huggingface.co/collections/databricks/
LLM Foundry:https://github.com/mosaicml/llm-foundry 在modeling_dbrx.py中可以找到参考模型代码。
注意:此模型代码仅供参考,请参阅HuggingFace存储库获取官方支持的版本。
1、下载权重
该模型使用我们的开源库Composer、LLM Foundry、MegaBlocks和Streaming的优化版本进行训练。
对于instruct模型,我们使用了ChatML格式。有关此信息,请参阅DBRX Instruct模型卡。
2、快速开始
T1、直接运行
要下载权重和分词器,请首先访问DBRX HuggingFace页面并接受许可。注意:访问基础模型需要手动批准。建议至少拥有320GB的内存来运行模型。
pip install -r requirements.txt # Or requirements-gpu.txt to use flash attention on GPU(s)
huggingface-cli login # Add your Hugging Face token in order to access the model
python generate.py # See generate.py to change the prompt and other settingsT2、采用LLM Foundry
对于更高级的用法,请参阅LLM Foundry(聊天脚本、批量生成脚本)
地址:llm-foundry/scripts/inference/hf_chat.py at main · mosaicml/llm-foundry · GitHub
T3、Docker镜像
如果您遇到任何软件包安装问题,我们建议使用我们的Docker镜像:mosaicml/llm-foundry:2.2.1_cu121_flash2-latest
3、推理
DBRX可以使用TensorRT-LLM和vLLM来运行优化推理。我们已在NVIDIA A100和H100系统上测试了这两个库。要使用16位精度运行推理,需要至少4 x 80GB多GPU系统。
T1、TensorRT-LLM
DBRX支持正在添加到TensorRT-LLM库:待处理的PR
合并后,构建和运行DBRX TensorRT引擎的说明将在README中找到。
T2、vLLM
有关如何使用vLLM引擎运行DBRX的说明,请参阅vLLM文档。
地址:Welcome to vLLM! — vLLM
4、微调
在我们的开源库LLM Foundry中可以找到微调DBRX的示例脚本
地址:https://www.github.com/mosaicml/llm-foundry
DBRX的案例应用
DBRX已广泛应用于Databricks提供的人工智能产品中,例如SQL引擎等就优于GPT-3.5。客户也可以基于DBRX进行各种领域下的应用,如内部功能开发或自研大模型等。