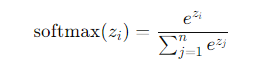🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、关键要点
AdaBoost,即自适应提升(Adaptive Boosting)算法的缩写,是一种基于 Boosting 策略的集成学习方法,旨在降低偏差。AdaBoost 的 “自适应” 二字意味着它能够在每一轮迭代后调整对训练数据实例的关注度(特别是那些之前被错误预测的样本)和更新弱学习器的权重。
与随机森林类似,AdaBoost 也是集成学习中的代表性算法之一,并且适用于分类和回归任务。Boosting 方法在近年来的多项数据竞赛中均取得了卓越的成绩,其背后的概念却并不复杂。该方法通过简单、易于理解的步骤构建简单的模型,进而将这些简单模型组合成强大的学习器。
当 Bagging 方法无法有效发挥作用时,可能会导致所有分类器在同一区域内都产生错误的分类结果。Boosting 方法背后的直观理念是,我们需要串行地训练模型,而非并行。每个模型都应专注于之前分类器表现不佳的样本区域。相较于随机森林中各决策树的相互独立性,AdaBoost 展现出一种顺序训练的级联结构。在 AdaBoost 中,后续模型的训练基于前一个模型的预测结果,形成依赖关系。这种级联方式使 AdaBoost 更专注于解决之前未能正确预测的样本,逐步优化预测性能。AdaBoost 充分考虑了每个弱学习器的发言权,不同于随机森林的简单投票或计算平均值。
AdaBoost 的核心思想在于:每一轮迭代后更新样本权重和弱学习器权重(这里的弱学习器通常使用决策树桩,决策树桩是指一个单层决策树),从而实现整体性能的优化提升。核心逻辑在于 “前人栽树,后人乘凉”。即前辈为后辈创造条件,后辈在此基础上进行改进。在 AdaBoost 中,我们首先训练一个弱学习器,并对其预测性能进行评估。在每一轮迭代后,我们更新样本的权重,也就是改变样本的困难度。对预测正确的样本减少关注,而对预测错误的样本加大关注,使新模型更能专注于克服前面的模型无法正确预测的困难样本。

最终,我们通过为不同的弱学习器赋予不同的权重,并将它们有效结合,成功地构建了一个强大的集成学习模型。这个集成模型不仅涵盖了处理容易样本的模型,还包括了处理困难样本的模型。因此,AdaBoost 显著提高了模型的预测能力。
【注意:配图截图自 B 站 UP 主 —— 五分钟机器学习的视频里的某一部分,视频链接为:https://www.bilibili.com/video/BV1iA411e76Y/。非常好的分享,点赞、投币支持。】
二、AdaBoost 的基本原理和建模过程
我们的第一个挑战在于如何评估样本的难度。通常,在训练 AdaBoost 的第一个模型时,我们会为每个样本点分配一个难度值,该值等于数据集中样本总数的倒数。训练完第一个模型后,我们将评估所有样本点,找出预测正确和错误的样本。对于预测正确的样本,我们会降低其难度值;而对于预测错误的样本,则增加其难度值。每一轮迭代后更新样本权重。

在此基础上,我们训练第二个模型,并再次评估所有样本点。由于训练第二个模型时,我们已经提高了对困难样本点的关注度,因此部分之前的预测错误的样本现在可能被正确预测。我们采用与训练第一个模型相同的策略:对于预测正确的样本,降低其难度值;对于预测错误的样本,增加其难度值(这相当于调整学习数据的分布)。这个过程会持续进行,直到达到我们预先设定的学习器数量。届时,AdaBoost 中将包含多个模型。
通过赋予不同的权重来组合不同的弱学习器。最后,我们需要整合每个模型的结果。不同于随机森林中的简单投票或均值计算,AdaBoost 需要对每个模型的预测性能进行评估,以确定不同弱学习器的权重。最后,利用这些权重将所有弱学习器的输出整合成一个整体。以上便是训练 AdaBoost 的基本逻辑。
AdaBoost 使用指数损失函数(exponential loss function): L ( y , f ( x ) ) = exp ( − y f ( x ) ) L(y, f(x)) = \exp(-yf(x)) L(y,f(x))=exp(−yf(x))
其中, y y y 是实际标签(取值为 -1 或 1), f ( x ) f(x) f(x) 是模型对样本 x x x 的预测值。AdaBoost 通过最小化加权指数损失来训练每个弱学习器,并通过调整样本权重来重点关注误差较大的样本。尽管 AdaBoost 通常不直接采用梯度下降法来优化损失函数,但其过程可以视作一种特殊的梯度下降形式。具体来说,在每一轮中选择弱学习器以最小化当前所有样本的加权指数损失总和,这可以被看作是在损失空间中朝着减少总体误差的方向迈出的一步。
相较于随机森林中各决策树的相互独立性,AdaBoost 展现出一种顺序训练的级联结构。随机森林的性能受限于其并行结构,导致性能上限相对较低,类似于三个学渣合作,虽有提升,但在面对特别困难的问题时仍无法正确解答。而在 AdaBoost 中,后续模型的训练基于前一个模型的预测结果,形成依赖关系。这种级联方式使 AdaBoost 更专注于学习之前未能正确预测的样本,逐步优化预测性能。AdaBoost 充分考虑了每个弱学习器的发言权,不同于随机森林的简单投票或计算平均值。
这意味着对于复杂数据,模型的预测性能上限可能会超过随机森林。然而,过度追求对困难样本的正确预测,有时会导致模型过拟合,使其对异常样本点过于敏感。AdaBoost 的性能上限较高,但下限也较低。此外,由于 AdaBoost 的特殊结构,后续模型的训练是基于前一个模型的预测结果进行的,这导致模型的训练速度相对较慢。
AdaBoost 除了能用于分类任务外,也能执行回归预测(即 AdaBoost.R2),尽管它在回归任务中并不常见。在 AdaBoost 回归中,损失函数可能采用加权均方误差,该误差量化了真实值与预测值之间的差异。作为一种元估计器,AdaBoost 回归器首先在原始数据集上训练一个基础回归器,然后在同一数据集上训练该回归器的多个副本,AdaBoost 在每次训练时会根据当前预测的误差调整样本的权重。因此,后续的回归器会更加关注那些预测误差较大的困难样本。
三、AdaBoost 的优点和不足
AdaBoost 的优点:
-
准确性高:通过在每一轮迭代后调整对训练数据实例的关注度(特别是那些之前被错误预测的样本)和更新弱学习器的权重,最后将不同的弱学习器以不同的权重组合在一起,以输出最终的预测结果。AdaBoost 通常能够达到较好的预测性能。
-
易于代码实现:相对于其他复杂算法,AdaBoost 算法容易实现。并且默认参数就能取得不错的效果。
-
自动处理特征选择:AdaBoost 可以自动选择有效特征,并且忽略不相关或噪声特征。
-
灵活性:可与各种类型数据和不同类型问题配合使用。
-
不太容易过拟合:在许多实践中,尽管增加了复杂度,但 AdaBoost 往往不容易过拟合。
AdaBoost 的不足:
-
噪声敏感性:对噪声和异常值敏感。由于算法会给错误预测样本更高权重,因此噪声和异常值可能会导致模型表现不佳。
-
计算量较大:尽管单个模型可能简单,但需要顺序训练多个模型可能导致计算量增大。由于 AdaBoost 是一种迭代算法,需要顺序训练大量弱学习器,因此在处理大规模数据集或高维特征时,其计算量可能会变得相当大。
-
数据不平衡问题:在面对极端不平衡数据时表现可能不佳。
总体而言,AdaBoost 是一种简单而高效的算法,适合作为解决分类问题的起点。然而,在应用时,需要注意其对噪声和异常值的敏感性。
四、AdaBoost 的实际应用
面部识别系统:想象一个门禁系统需要识别人脸来决定是否允许进入。每个人脸都有很多特征:眼睛大小、鼻子形状、嘴巴位置等等。 AdaBoost 可以通过逐步 “关注” 难以区分人脸特征的部分(比如某些人眼睛形状相似),逐渐提高系统识别人脸的准确性。
信用评分:银行需要决定是否批准贷款申请。他们可以使用 AdaBoost 来结合多个简单模型(例如基于申请人年龄、收入、信用记录等因素)来预测申请人违约的可能性。通过不断迭代,AdaBoost 能够更加精确地识别哪些客户是安全风险较低的借款者。
客户流失预测:公司通常希望知道哪些客户可能会停止使用其服务或产品。使用 AdaBoost 分析客户数据(包括购买历史、服务使用频率、客户反馈等),可以帮助公司识别出潜在的流失客户,并采取措施挽留他们。
AdaBoost 是一种强大且灵活的机器学习算法,广泛应用于多个领域。它通过不断迭代,并在每一轮迭代后更新样本和弱学习器的权重,将不同的弱学习器以不同的权重组合在一起,以输出最终的预测结果。这种方法有效地提高了预测的准确率和稳健性。无论是面部识别、信用评分还是客户流失预测等问题,AdaBoost 都能提供有效的解决方案。
📚️ 相关链接:
-
【五分钟机器学习】Adaboost:前人栽树后人乘凉
-
机器学习中最最好用的提升方法:Boosting 与 AdaBoost
-
7 个步骤详解 AdaBoost 算法原理和构建流程(附代码)
-
AdaBoost 算法解密:从基础到应用的全面解析
-
CAO Ying, MIAO Qi-Guang, LIU Jia-Chen, GAO Lin. Advance and Prospects of AdaBoost Algorithm. ACTA AUTOMATICA SINICA, 2013, 39(6): 745-758. doi: 10.3724/SP.J.1004.2013.00745