持久层框架
Hibernate
假设有个数据表,它有3个字段分别是id、rolename、note, 首先用IDEA构建一个maven项目Archetype选择org.apache.maven.archetypes:maven-archetype-quickstart即可,配置如下pom
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>ChapterNew</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><name>ChapterNew</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!-- https://mvnrepository.com/artifact/com.mysql/mysql-connector-j --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.3.0</version></dependency><!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-core --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.3.7.Final</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency></dependencies><build><!--读取配置文件--><resources><resource><directory>src/main/resources</directory></resource><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes><filtering>false</filtering></resource></resources></build>
</project>根据这个角色表,建立一个POJO(Plain Ordinary Java Object)和这张表的字段对应起来
package com.ssm;import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import java.io.Serializable;
@Entity //实体类
public class Role implements Serializable{@Id //主键@GeneratedValue(strategy = GenerationType.AUTO) //自增private int id;private String roleName;private String note;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getRoleName() {return roleName;}public void setRoleName(String roleName) {this.roleName = roleName;}public String getNote() {return note;}public void setNote(String note) {this.note = note;}
}无论是MyBatis还是Hibernate都是依靠某种方法,将数据库的表和POJO映射起来,然后工程师通过操作POJO来完成逻辑开发
数据表有了,POJO类有了,将他们建立起映射关系,则需要提供映射规则,无论是MyBatis或Hibernate都可以使用注解或者XML的方式提供映射规则,因为注解有一定的局限性,通常都会使用XML来完成表和POJO之间的映射规则设定,这就是POJO对象和数据库表相互映射的框架,即对象关系映射(Object Relational Mapping, ORM)框架
无论是MyBatis还是Hibernate都可以被称为ORM框架,只是Hibernate的设计理念完全面向POJO,而MyBatis不是,Hibernate基本不需要编写SQL就可以通过映射关系来操作数据库,它是一种全映射的体现;而MyBatis不同,它需要工程师编写SQL来运行,也因此体现出了两者的很大的区别,MyBatis灵活,几乎可以完全代替JDBC,同时提供了接口编程,MyBatis的数据访问层DAO(Data Access Objects)是不需要实现类的,它只需要一个接口和XML(或者注解),MyBatis提供自动映射、动态SQL、级联、缓存、注解、代码和SQL分离,也因此可以对SQL进行优化,也正是因为其封装少,映射多样化,支持存储过程,可以进行SQL优化等特点,使得他取代Hibernate成为首选
以下是一个基于Hibernate框架的Java Persistence Object (POJO)类与数据库表之间的映射文件示例,假设我们要为一个名为User的实体类创建映射。该映射文件通常命名为User.hbm.xml,并放置在项目的资源目录中,以便被Hibernate自动加载
<!-- t_role.hbm.xml -->
<!DOCTYPE hibernate-mapping PUBLIC"-//Hibernate/Hibernate Mapping DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"><hibernate-mapping><class name="com.ssm.Role" table="t_role"><!-- 定义主键 --><id name="id" type="int"><column name ="id"/><generator class="identity"/></id><!-- 定义属性映射 --><property name="roleName" type="string"><column name="rolename" length="60" not-null="true"/></property><property name="note" type="string"><column name="note" length="255"/></property><!-- 如果存在一对多关系,例如每个用户有多个订单 --><!-- <set name="orders" inverse="true" cascade="all-delete-orphan"><key column="user_id"/><one-to-many class="com.example.entity.Order"/></set> --><!-- 如果存在一对一关系,例如每个用户有一个头像 --><!-- <one-to-one name="profilePicture" class="com.example.entity.ProfilePicture" cascade="all"/> --><!-- 如果存在多对一关系,例如每个用户属于一个角色 --><!-- <many-to-one name="role" column="role_id" class="com.example.entity.Role" not-null="true"/> --><!-- 如果存在多对多关系,例如每个用户可以关注其他多个用户 --><!-- <bag name="followingUsers" table="user_following"><key column="follower_id"/><many-to-many column="following_id" class="com.example.entity.User"/></bag> --></class>
</hibernate-mapping>
解析说明:
- DOCTYPE声明:指定了使用的Hibernate映射文件DTD版本,确保XML语法正确性。
<hibernate-mapping>标签:整个映射配置文件的根节点。<class>标签:- name属性指定对应的Java POJO类全名。
- table属性指定对应的数据库表名。
<id>标签:- 定义实体类的主键字段。此处以long类型的id为例,对应数据库表中的id列。
- generator class=“identity” 在Hibernate映射文件中表示所映射的实体类主键字段的生成策略使用数据库的内置标识符生成机制。
<property>标签:- 对应POJO类中的非主键属性与数据库表中相应列的映射。
- name属性指定POJO类中的属性名。
- column属性指定数据库表中的列名。
- type属性指定数据类型,如string、long、timestamp等。
- 可选属性如length定义字符串长度限制,not-null和unique分别设置是否允许为空和唯一性约束。
- 关联关系映射(已注释掉,根据实际需求启用):
<set>、<one-to-one>、<many-to-one>、<bag>等标签用于定义不同类型的关联关系,如一对多、一对一、多对一、多对多。- 关联关系的具体配置包括关系名称、外键列、目标类、级联操作等。
请根据实际项目中的Role类及其关联关系调整上述映射文件内容。如有其他复杂特性(如继承、嵌套集合等),还需添加相应的映射元素进行配置
Hibernate核心配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"><hibernate-configuration><session-factory><!-- 第一部分: 配置数据库信息 必须的 --><property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property><property name="hibernate.connection.url">jdbc:mysql://localhost:3306/ssm1</property><property name="hibernate.connection.username">root</property><property name="hibernate.connection.password">Ms123!@#</property><!-- 使用MYSQL的 innodb引擎 --><property name="hibernate.dialect.storage_engine">innodb</property><!-- 第二部分: 配置hibernate信息 可选的--><!-- 输出底层sql语句 --><property name="hibernate.show_sql">true</property><!-- 输出底层sql语句格式 --><property name="hibernate.format_sql">true</property><!-- hibernate帮创建表,需要配置之后update: 如果已经有表,更新,如果没有,创建--><property name="hibernate.hbm2ddl.auto">update</property><!-- 配置数据库方言在mysql里面实现分页 关键字 limit,只能使用mysql里面在oracle数据库,实现分页rownum让hibernate框架识别不同数据库的自己特有的语句--><property name="hibernate.dialect">org.hibernate.dialect.MySQL8Dialect</property><property name="hibernate.connection.autocommit">true</property><!--for (non-JTA) DDL execution was not in auto-commit mode;the Connection 'local transaction' will be committed and the Connection will be set into auto-commit mode.--><!-- 第三部分: 把映射文件放到核心配置文件中 必须的--><mapping resource="mapper/t_role.hbm.xml"/></session-factory></hibernate-configuration>
先对POJO和角色进行映射,再对POJO进行操作,从而影响角表的数据,如下代码所示
package com.ssm;import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.boot.MetadataSources;
import org.hibernate.boot.registry.StandardServiceRegistry;
import org.hibernate.boot.registry.StandardServiceRegistryBuilder;
import org.junit.Test;/*** Unit test for simple App.*/
public class RoleTest {@Testpublic void testInit() {StandardServiceRegistry registry = null;SessionFactory sessionFactory = null;Session session = null;Transaction transaction = null;try {//初始化注册服务对象registry = new StandardServiceRegistryBuilder().configure()//默认加载hibernate.cfg.xml,如果配置文件名称被修改:configure("被修改的名字").build();//获取Session工厂sessionFactory = new MetadataSources(registry).buildMetadata().buildSessionFactory();//从工厂创建Session连接session = sessionFactory.openSession();//开启事务transaction = session.beginTransaction();//创建事例Role role = new Role();role.setRoleName("zhang");role.setNote("123");session.save(role);//提交事务transaction.commit();} catch (HibernateException e) {e.printStackTrace();//回滚事务transaction.rollback();} finally {if(session!=null && session.isOpen())//关闭sessionsession.close();}}
}
代码中并未写任何SQL,因为Hibernate会根据映射关系生成对应的SQL,应用系统首先考虑的是业务逻辑实现,然后才是性能提升,使用Hibernate的建模方式非常有利于业务分析,因此Hibernate一度成为主流选择
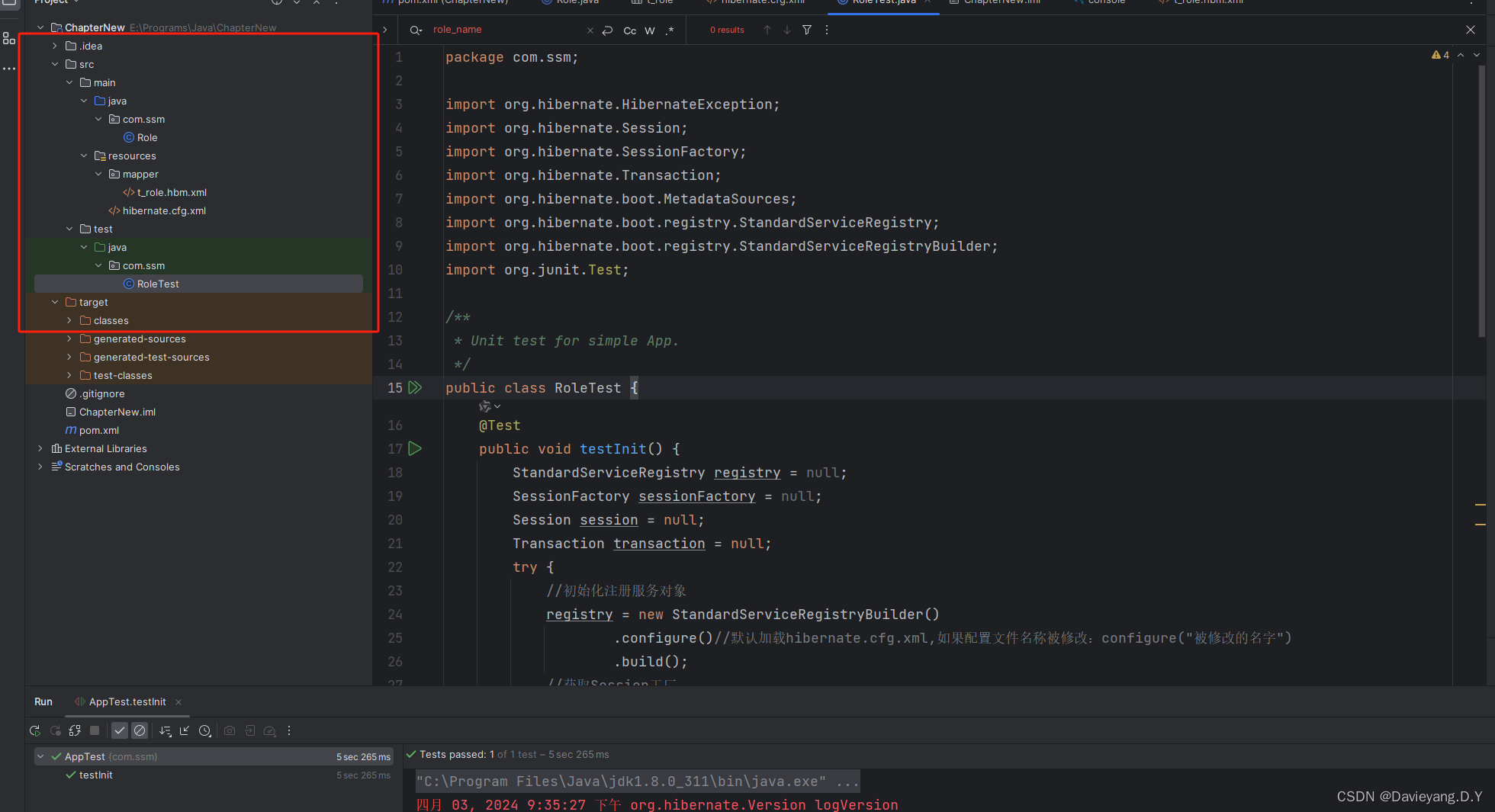
至此一个简单的Hibernate的框架就可以运转起来了,项目结构如下
MyBatis
前面已经讲了几句MyBatis和Hibernate的些许区别,应该说MyBatis不屏蔽SQL,让它更具灵活性但复杂度也随之而来,但在优化SQL的层面上缺存在巨大的差别,而SQL操作数据往往是系统瓶颈的重要维度之一,因此MyBatis框架逐渐成为了当前Java互联网持久层的首选,它更符合移动互联网高并发、大数据、高性能、快响应的要求,程序员可以自定制定SQL规则,而不是由Hibernate自动生成规则
与Hibernate一样,MyBatis需要一个映射文件把POJO和角色表对应起来
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.example.mapper.RoleMapper"><resultMap id="roleMap" type="com.ssm.pojo.Role"/><id property="id" column="id"/><result property="roleName" column="role_name"/><result property="note" column="note"/></resultMap><!-- 插入Role --><insert id="insertRole" parameterType="com.ssm.pojo.Role">INSERT INTO t_role(role_name, note)VALUES (#{roleName}, #{note})</insert><!-- 根据ID查询Role --><select id="getRoleById" parameterType="long" resultMap="roleMap">SELECT id, role_name, note FROM t_role WHERE id = #{id}</select><!-- 更新Role --><update id="updateRole" parameterType="com.ssm.pojo.Role">UPDATE t_role SET role_name = #{roleName}, note = #{note} WHERE id = #{id}</update><!-- 删除Role --><delete id="deleteRole" parameterType="long">DELETE FROM t_role WHERE id = #{id}</delete>
</mapper>解析说明
在这个MyBatis的Mapper XML文件中:
<mapper>元素定义了命名空间(namespace),他要和一个接口的全限定名保持一致- resultMap用于定义映射规则,实际上当MyBatis满足一定的规则时,可以自动完成映射
- 对于每个CRUD操作,分别使用了
<insert>、<select>、<update>、<delete>标签来编写SQL语句。 - id属性指定了在Mapper接口中对应的方法名,也要完全保持一致
- parameterType属性指定传递给SQL语句的参数类型,这里是
com.example.pojo.Role或long。 - resultType属性(仅在SELECT语句中使用)指定查询结果应映射到的Java类型,也可以类似于XML所写,指定resultMap,Java类在resultMap里指定,这里是
com.ssm.pojo.Role。
//定义MyBatis映射接口
package com.ssm.chaptertwo.mapper;
import com.ssm.chaptertwo.pojo.Role;
public interface RoleMapper{public Role getRole(Integer id);public int deleteRole(Integer id);public int insertRole(Role role);public int update(Role role);
}
//工作这个映射接口完成CRUD
SqlSession sqlSession=null;
try{sqlSession = MyBatisUtil.getSqlSession();RoleMapper roleMapper = sqlSession.getMapper(RoleMapper.class);Role role = roleMapper.getRole(1);//查询System.err.println(role.getRoleName());role.setRoleName("update_role)name");roleMapper.updateRole(role);//更新Role role2 = new Role();role2.setNote("note2");role2.setRoleName("role2");roleMapper.insertRole(role);//插入roleMapper.deleteRole(5);//删除sqlSession.commit();//提交事务}catch (Exception ex){ex.printStackTrace();if(sqlSession!=null){sqlSession.rollback();//回滚事务}}finally{//关闭链接if(sqlSession !=null){sqlSession.close();}}
整条链路下来,显然MyBatis在业务逻辑上的实现和Hibernate是大同小异的,区别在于MyBatis需要提供接口和SQL,这意味着他的工作量会大于Hibernate,但由于自定义SQL、映射关系,所以其灵活性和可优化的属性超过了Hibernate
如何取舍完全取决于技术面向业务的业务对象的复杂度
总结对比
- Hibernate和MyBatis的CRUD对于业务逻辑来说大同小异,对于映射层,Hibernate的配置不需要接口和SQL,而MyBatis需要
- Hibernate不需要编写大量的SQL就可以完全映射,同时提供了日志、缓存、级联(级联比MyBatis强大)等特性,此外还提供了HQL(Hibernate Query Language)对POJO进行操作使用起来很方便,但也存在致命缺陷,由于无须SQL,当关联超过3个表的时候,通过Hibernate的级联会造成很多性能的损失,例如财务表会关联财产信息表,财产信息表又细分为机械、原料等等,很显然这些字段是不一样的,关联字段只能根据特定的条件变化而变化,而Hibernate就不具备这样的灵活性;遇到存储过程Hibernate也无法很好地支持
- MyBatis可以自由编写SQL,支持动态SQL、处理列表、动态生成表名、支持存储过程,从而解决了以上Hibernate遇到的问题,更灵活的满足移动互联网的特性
系统性能决定了用户忠诚度 - MyBatis需要编写SQL和映射规则,工作量会大于Hibernate,且它支持的工具很有限,而Hibernate有许多的插件可以帮助生成映射代码和关联关系,开发者只需要优化或者简化生成内容
- 对于性能要求不苛刻的系统,例如管理系统、ERP等使用Hibernate完全可以,对于性能要求较高的系统MyBatis更佳



![CTF下加载CTFtraining题库以管理员身份导入 [HCTF 2018]WarmUp,之后以参赛者身份完成解题全过程](https://img-blog.csdnimg.cn/direct/16f5aad85bd64fc3b1f1ca9c27766b57.png)