JAX简介
https://www.bilibili.com/video/BV1Sb4y1b7rK/?spm_id_from=333.999.0.0&vd_source=b2549fdee562c700f2b1f3f49065201b
JAX is NumPy wiht Autograd , XLA and Composable (function) transformations, brought together for high-performance machine learning research on the CPU, GPU, and TPU.
-
JAX 可以进行异步调度。所以需要调用
.block_until_ready()以确保计算已经实际发生。 -
XLA:XLA (Accelerated Linear Algebra)是Google为TensorFlow设计的一款编译器,主打JIT (Just-in-Time)编译和跨设备(CPU/GPU/TPU)执行,所以JAX介绍中凡是涉及到JIT、high-performance、CPU/GPU/TPU,都指的是XLA。使用XLA(一种加速线性代数计算的编译器)将Python和JAX代码JIT编译成优化的内核,可以在不同设备(例如gpu和tpu)上运行。而优化的内核是为高吞吐量设备(例如gpu和tpu)进行编译,它与主程序分离但可以被主程序调用。JIT编译可以用jax.jit()触发。XLA相对于JAX是一个更加底层的概念,JAX中的算子
jax.lax看做是对XLA算子的Python封装。
from jax import lax
- NumPy:NumPy就不用提了,Python生态下只要涉及到数据分析/机器学习/数值计算中对数组/tensor进行操作,都离不开它,不夸张的说,NumPy API已经成为了数组/tensor操作的半个工业标准,包括各家深度学习框架中对tensor操作的函数接口也都是尽量靠近NumPy,JAX则更夸张,
jax.numpy重新实现一套了NumPy API ,让用户从NumPy无缝切入JAX,jax.numpy中的操作/算子是对更底层的jax.lax的封装,与 NumPy 数组不同,JAX 数组始终是不可变的,JAX 速度是 NumPy 的 150 倍以上:
from jax import numpy as jnp
- Autograd:这里的Autograd是哈佛大学HIPS实验室在14年开始开发的一款自动微分框架,特点是可以对Python/NumPy函数进行高阶求导。自动微分框架除了可以应用于数值计算,它还是深度学习框架的核心,可惜的是,由于性能(纯Python,只有CPU版本)以及其他原因,autograd库并没有推广起来,但是它却实实在在启发到了后续的torch-autograd、Chainer以及PyTorch中的autograd模块。直接看个例子,一个简单的函数 f ( x ) f(x) f(x),顺便求一下一阶、二阶、三阶导函数:
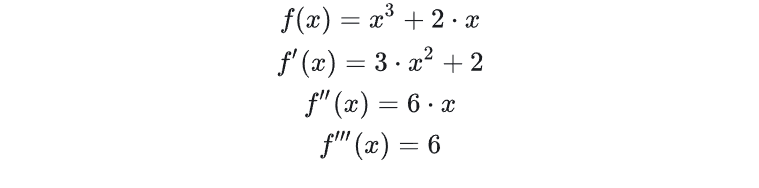
from autograd import graddef f(x):return x**3 + 2*xgrad_f = grad(f) # 一阶导函数
grad_grad_f = grad(grad_f) # 两次grad组合,就是二阶导函数
grad_grad_grad_f = grad(grad_grad_f) # 三次grad组合,就是三阶导函数
print(grad_f(2.), grad_grad_f(2.), grad_grad_grad_f(2.))
# 14.0 12.0 6.0
-
Composable (function) transformations (可组合的函数转换):composable transformations是JAX的核心,其实就是高阶函数 (Higher-order function),transformation的输入是Python函数,输出也是函数。JAX中经常用到的transformation主要有四个:
grad: reverse mode自动微分,用在深度学习中足够了jit: JIT实时编译,调用XLA进行JIT编译,用于优化代码vmap: vectorization/batching自动向量化/批处理,将函数扩展为支持批处理pmap: parallelization并行化计算,轻松实现数据并行 (data parallelism),类似PyTorch的DistributedDataParallel
from jax import grad, jit, vmap, pmap
grad
grad只是JAX自动微分机制中最基本的一个transform,实际上JAX支持前向(forward-mode)自动微分和后向(reverse-mode)自动微分以及二者的任意组合, 感兴趣的同学可以去查看jvp和vjp 的文档。考虑到常见的深度学习任务,grad绰绰有余, 其他transform这里就不介绍了,实际上是我没用过,压根没那个能力介绍。
from jax import numpy as jnp
from jax import graddef f(x):return jnp.sum(x * x) # 函数输出只能是标量grad_f = grad(f)
grad_f(jnp.array([1, 2, 3.]))
# DeviceArray([2., 4., 6.], dtype=float32)
grad不但好用,而且数学上更直观,如果我们不局限在深度学习领域,从优化 (optimization)的角度看,大多数机器学习模型的学习都可以表示为: y ~ = f ( x ) , max y p ( y ∣ x ) , max y p ( x , y ) p ( x ) \tilde{y}=f(x), \ \max _{y} p(y \mid x), \ \max _{y} \frac{p(x, y)}{p(x)} y~=f(x), maxyp(y∣x), maxyp(x)p(x,y) 的一种
LR可以表示为 f ( x ) f(x) f(x) ,神经网络也可以表示为 f ( x ) f(x) f(x) ,损失函数是 l o s s = g ( f ( x ) , y ) loss=g(f(x),y) loss=g(f(x),y) ,如果用SGD算法来解决,需要计算参数的梯度,想一下高数课上我们是怎么做的,直接对损失函数求导函数 g r a d ( g ) grad(g) grad(g) ,然后代入 x x x ,现在 grad 用的就是这种方式。并且这种方式在数学上可以自然的泛化到高阶导数优化求解问题上。
jit
jit 是用户显式的调用XLA对代码进行优化(包括算子融合、内存优化等),执行时间可能缩短很多:
import numpy as np
from jax import numpy as jnp
from jax import jitdef norm(X):X = X - X.mean(0)return X / X.std(0)norm_compiled = jit(norm)
X = jnp.array(np.random.rand(10000, 100))%timeit norm(X).block_until_ready()
%timeit norm_compiled(X).block_until_ready()
# 585 µs ± 85.4 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 216 µs ± 12.3 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)# 好像提升不是很显著,再来看一个例子
from jax import randomkey = random.PRNGKey(0)def selu(x, alpha=1.67, lmbda=1.05):return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha)selu_jit = jit(selu)
x = random.normal(key, (1000000,))
%timeit selu(x).block_until_ready()
%timeit selu_jit(x).block_until_ready()
# 1.06 ms ± 26.8 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
# 187 µs ± 19.6 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)# 哦豁,效果还不错
vmap
vmap可以自动让函数支持batching,看个例子,原始函数表示的是向量-向量乘法,使用vmap可以得到矩阵-向量乘法的函数:
from jax import numpy as jnp
from jax import vmapdef vec_vec_dot(x, y):"""vector-vector dot, ([a], [a]) -> []"""return jnp.dot(x, y)x = jnp.array([1,1,2])
y = jnp.array([2,1,1,])
vec_vec_dot(x, y)
# DeviceArray(5, dtype=int32)mat_vec = vmap(vec_vec_dot, in_axes=(0, None), out_axes=0) # ([b,a], [a]) -> [b] (b is the mapped axis)
xx = jnp.array([[1,1,2], [1,1,2]])
mat_vec(xx, y)
# DeviceArray([5, 5], dtype=int32)
解释下vmap中的in_axes和out_axees两个参数,前者表示对输入参数中哪一个的哪一维度进行batch扩充,这里(0, None)表示对x的第0维扩充,由原来的[a] -> [b,a]。后者表示对返回结果的哪一维度进行扩充,这里表示由原来的[] - > [b]。
pmap
pmap让并行编程变的非常丝滑,可以用于数据并行训练,注意pmap包含了jit操作,下面我就在TPU v3-8 VM演示下:
import jax
from jax import numpy as jnp
from jax import pmapjax.device_count() # 8个core
# 8jax.devices()
"""
[TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]
"""x = jnp.arange(8)
y = jnp.arange(8)vmap(jnp.add)(x, y)
# DeviceArray([ 0, 2, 4, 6, 8, 10, 12, 14], dtype=int32)pmap(jnp.add)(x, y)
# ShardedDeviceArray([ 0, 2, 4, 6, 8, 10, 12, 14], dtype=int32)
看到上面vmap和pmap执行后的区别没,一个返回数据类型是DeviceArray,一个则是SharedDeviceArray,后者表示数据分散在多个device中。
组合
上面介绍的transformation不仅仅可以单兵作战,最重要的是可以任意组合,比如
pmap(vamp(some_func))
jit(grad(grad(vmap(some_func))))
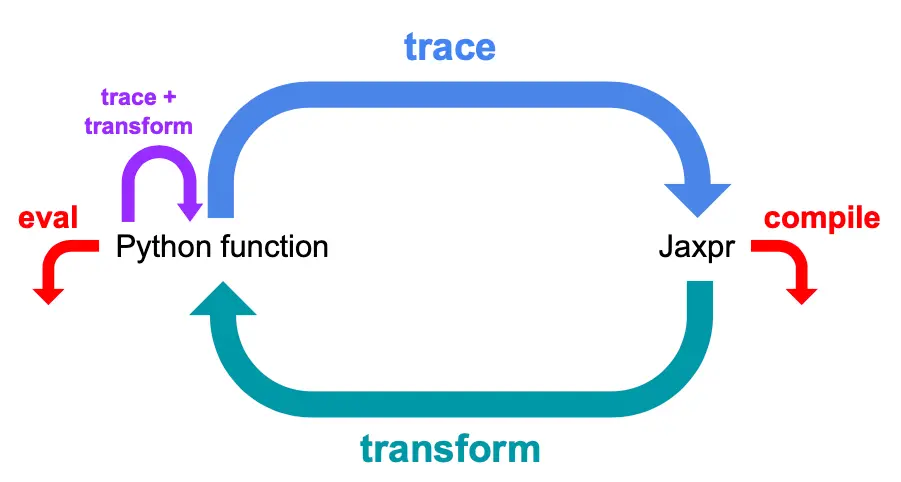
jaxpr
稍微聊一下transformation背后的故事,JAX中定义了一种中间表示语言(jaxpr),每个transformation的执行都分两步:
- 先将原Python函数翻译为jaxpr,这个过程被称为"tracing"
- 再对jaxpr进行transform (转换),可以将每个transformation看作一个独立的jaxpr interpreter,对于JAX中每个原子操作 (primitive)都有相应的转换规则
jaxpr的优势是语法简单,相比于直接对Python函数transform,对jaxpr进行transform容易得多。
Flax+JAX 实现 NN model
有了jax.numpy、jax.grad、jax.pmap、jax.jit,现在就可以编写网络,实现训练过程了,但是想象下用NumPy实现一个ResNet,实现一个Transformer,能做,但是也太复杂了,但是我们可以使用Flax,一个基于JAX的NN library,来轻松实现网络训练流程。
https://zhuanlan.zhihu.com/p/544216783
Flax/JAX开发者大会
pmap 实现 数据并行
https://zhuanlan.zhihu.com/p/544349452