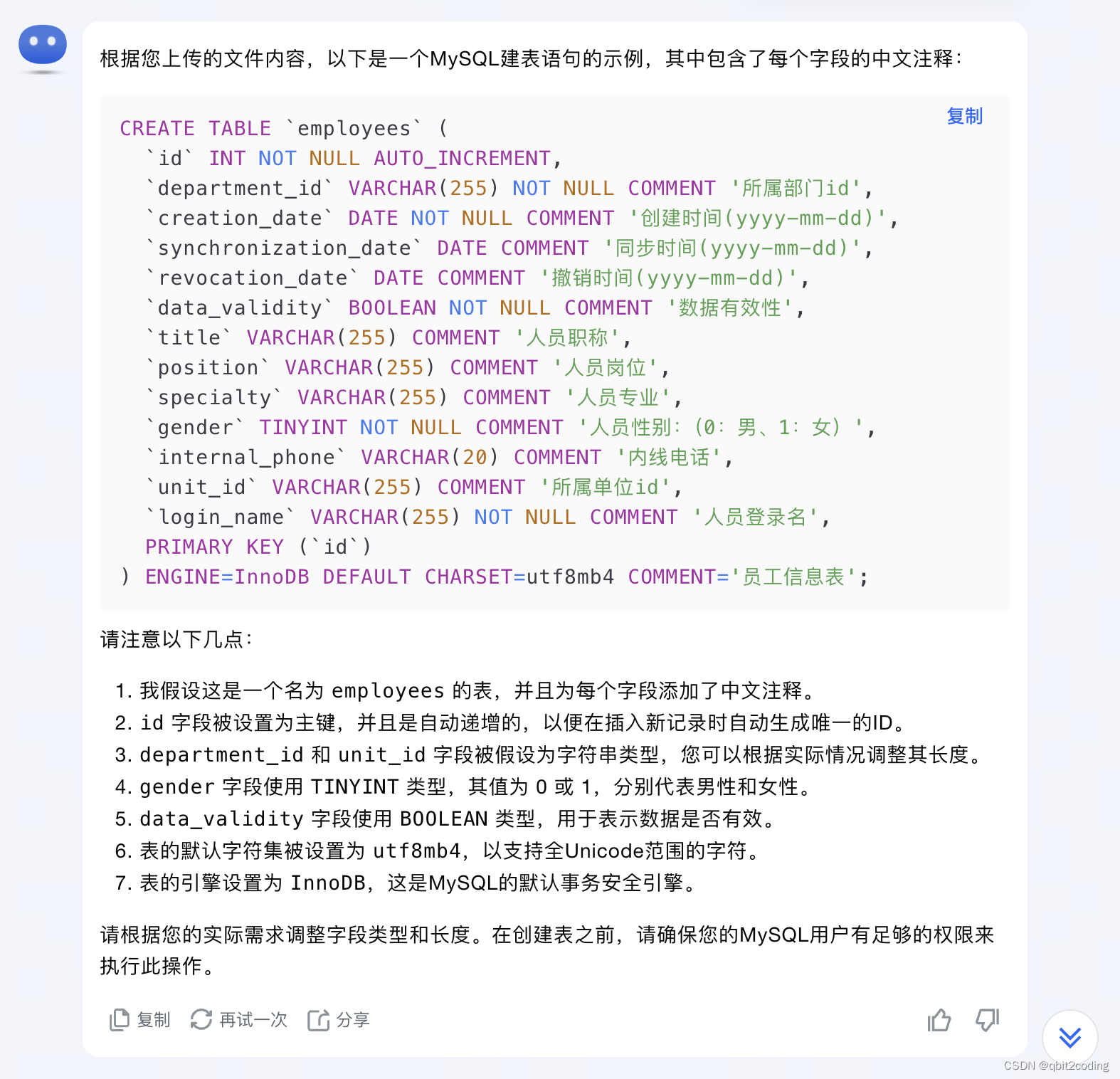
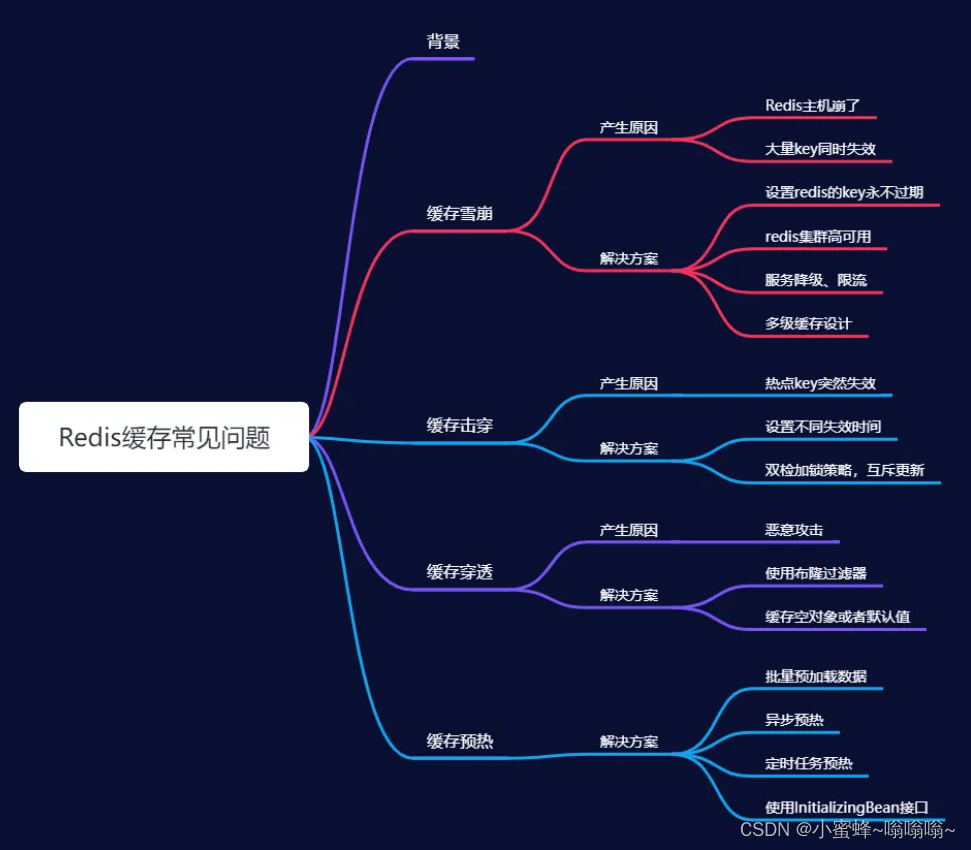
在实际工程中,Redis 缓存问题常伴随高并发场景出现。例如,电商大促、活动报名、突发新闻时,由于缓存失效导致大量请求访问数据库,导致雪崩、击穿、穿透等问题。因此,新系统上线前需预热缓存,以应对高并发,减轻数据库压力。本章主要围绕这几个核心问题,针对产生场景、分析原因、并给出相应的解决方案。
常见问题:
1. 缓存穿透
1.1 什么是缓存穿透
一句话,就是查询一条根本没有的记录。它既不存在于redis中,也不存在数据库中。一般我们的查询顺序是先查redis、再查数据库。每次请求最终都会访问到数据库。造成数据库访问压力。这种现象叫缓存穿透。
问题描述
key 对应的数据在数据源并不存在,每次针对此 key 的请求从缓存获取不到,请求都会压到数据源(数据库),从而可能压垮数据源。比如用一个不存在的用户 id 获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
1.2 产生原因
-
查询记录在redis和数据库均不存在
-
恶意攻击
缓存穿透发生的条件:
- 应用服务器压力变大
- redis 命中率降低
- 一直查询数据库,使得数据库压力太大而压垮
其实 redis 在这个过程中一直平稳运行,崩溃的是我们的数据库(如 MySQL)。
缓存穿透发生的原因:黑客或者其他非正常用户频繁进行很多非正常的 url 访问,使得 redis 查询不到数据库。
1.3 解决方案
方案一:使用布隆过滤器
使用布隆过滤器解决缓存穿透问题具体流程如下:

流程说明:
-
Web端发起请求到App服务应用
-
经过布隆过滤器判断key是否存在
-
若不存在,直接返回null
-
若key存在或者被误判(下文详述),查询redis
-
若redis中有结果,直接返回
-
未查到,则查询数据库返回结果
-
数据库查到结果,返回结果。并将对应key回写redis
-
未查到,则返回null
方案二:缓存空对象或者默认值
针对要查询的数据,需求层面沟通,可以在Redis里存一个缺省值(比如,零、负数、defaultNull等)。

流程描述:
-
先去redis查键user:xxxxxx没有,再去mysql查没有获得 ,这就发生了一次穿透现象;
-
第一次来查询user:xxxxxx,redis和mysql都没有,返回null给调用者;
-
将 user:xxxxxx,defaultNull 回写redis;
-
第二次查user:xxxxxx,此时redis就有值了。
可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。
但是,此方法只能解决key相同的情况,但是无法应对黑客恶意攻击。
解决方案:
- 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟。
- 设置可访问的名单(白名单):使用 bitmaps 类型定义一个可以访问的名单,名单 id 作为 bitmaps 的偏移量,每次访问和 bitmap 里面的 id 进行比较,如果访问 id 不在 bitmaps 里面,进行拦截,不允许访问。
- 采用布隆过滤器:布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量 (位图) 和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
- 进行实时监控:当发现 Redis 的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务。
2. 缓存击穿
2.1 什么是缓存击穿
一句话,就是热点key突然失效了,大量请求暴击数据库。关键词:大量请求、同一个热点key、正好失效。
问题描述
key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端数据库加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端数据库压垮。
2.2 产生原因(发生场景)
-
某个key以到过期时间,但是还是被访问到
-
key被删除,但是被访问到
-
如,某电商网站的今日特卖
缓存击穿的现象:
数据库访问压力瞬时增加,数据库崩溃
redis 里面没有出现大量 key 过期
redis 正常运行
缓存击穿发生的原因:redis 某个 key 过期了,大量访问使用这个 key(热门 key)。
2.3 解决方案
方案一:差异失效时间
差异失效时间,对于访问频繁的热点key,不设置过期时间。和上边类似,这里不再赘述。
方案二:采用互斥锁,双检加锁策略更新
双检锁通常用于解决懒加载中的并发问题,即只有当数据在缓存中不存在时,才进行数据库查询,并且确保只有一个线程进行数据库查询。
基本流程如下:
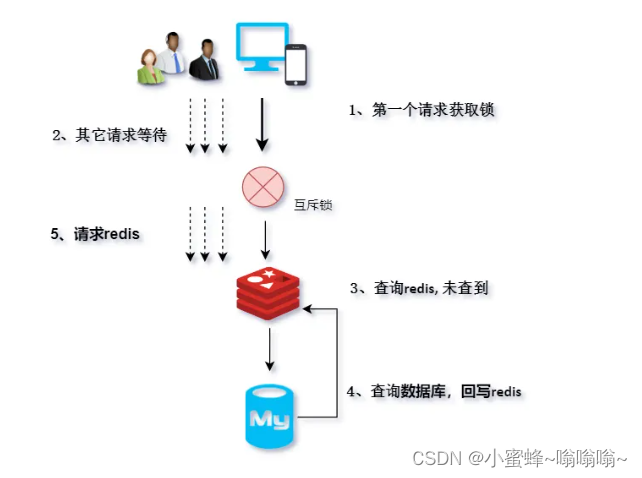
-
当大量请求进来,多个线程同时去查询数据库获取同一条数据;
-
在第一个查询数据的请求上使用一个
互斥锁来锁定; -
其他的线程走到这一步拿不到锁排队等着;
-
第一个线程查询到了数据,然后做缓存;
-
后面的线程进来发现已经有缓存了,就直接走缓存。
解决方案
key 可能会在某些时间点被超高并发地访问,是一种非常 “热点” 的数据。
预先设置热门数据:在 redis 高峰访问之前,把一些热门数据提前存入到 redis 里面,加大这些热门数据 key 的时长。
实时调整:现场监控哪些数据热门,实时调整 key 的过期时长。
使用锁:
就是在缓存失效的时候(判断拿出来的值为空),不是立即去 load db。
先使用缓存工具的某些带成功操作返回值的操作(比如 Redis 的 SETNX)去 set 一个 mutex key。
当操作返回成功时,再进行 load db 的操作,并回设缓存,最后删除 mutex key;
当操作返回失败,证明有线程在 load db,当前线程睡眠一段时间再重试整个 get 缓存的方法。
3. 缓存雪崩
3.1 什么是缓存雪崩
指在一个高并发的系统中,由于大量的缓存数据在同一时间段内过期或失效,导致大量请求无法从缓存中获取数据,因此大量并发请求可能导致数据库服务器过载,甚至宕机,从而引发整个系统崩溃。
问题描述
key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端数据库加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端数据库压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多 key 缓存,前者则是某一个 key 正常访问。
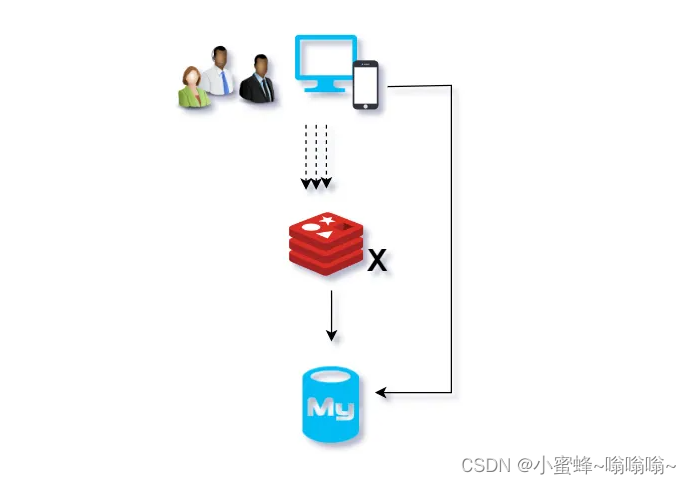
3.2 产生原因
- 硬件故障。 比如:机房着火、停电等导致
redis挂机。 - 软件设计。redis中有
大量key同时过期或者大面积失效。导致缓存中查不到对应key。此时访问压力给到数据库。如图示:
实际应用场景中,如:
-
金融系统股票价格、汇率等数据实时变动;
-
热点新闻缓存过期时,大量用户访问新闻详情页的请求;
-
电商平台在大促期间,如“618”、“双十一”等。
如果这些数据在缓存中的过期时间设置得过于集中,或者缓存服务器突然宕机,那么在数据过期或缓存失效的瞬间,大量请求会直接访问数据库,导致数据库负载剧增,可能引发雪崩。
3.3 解决方案
针对雪崩问题的解决方案,一般可以从以下几个角度考虑:
方案一:设置redis的某些key永不过期
简单地使用 SET 命令来添加这个key,不需要调用任何设置过期时间的命令:
SET product:500100 "{\"name\":\"ProductName\", \"price\":99.99, \"status\":\"上架中\"}"
在java中,可以使用Jedis或者RedisTemplate客户端
redisTemplate.opsForValue().set(productCode, productData);
值得注意的是,可能因为Redis的内存限制或其他原因(如使用了Redis的LRU淘汰策略)而被删除。因此,在设计系统时,除了考虑key的过期时间外,还需要考虑Redis的内存管理和淘汰策略。
方案二:搭建高可用redis集群+持久化
如图,一般线上环境都会有redis集群保证高可用。
对应集群模式:
-
主从模式(Master-Slave)
-
哨兵模式 (Sentinel)
-
分片模式 (Cluster)
关于三种集群模式的优缺点对比,配置这里不再赘述。图示只说明redis集群保障高可用的能力。
方案三:服务降级、熔断、限流
在Spring Cloud中使用Hystrix和Sentinel进行熔断降级和限流,这里给出简单的程序示例。
-
服务熔断降级 - Hystrix
配置pom.xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
在启动类上添加@EnableHystrix注解来启用Hystrix。
@SpringBootApplication
@EnableHystrix
public class MyApplication {public static void main(String[] args) {SpringApplication.run(MyApplication.class, args);}
}
在服务调用方法上添加@HystrixCommand注解,并配置相应的降级逻辑。
@Service
public class MyService {@HystrixCommand(fallbackMethod = "fallbackMyMethod")public String busiMethod() {// 调用远程服务}public String fallbackMyMethod() {// 降级逻辑return "Fallback response";}
}
对于Hystrix的YML配置,你可以在application.yml或application.properties中设置一些全局参数,例如超时时间、请求缓存等。
hystrix:command:default:execution:isolation:thread:timeoutInMilliseconds: 5000 # 设置命令执行的超时时间fallback:enabled: true # 启用降级逻辑
-
限流 - Sentinel
在pom.xml中添加了Sentinel的依赖。
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
在启动类上添加@EnableDiscoveryClient和@EnableSentinel注解。
@SpringBootApplication
@EnableDiscoveryClient
@EnableSentinel
public class MyApplication {public static void main(String[] args) {SpringApplication.run(MyApplication.class, args);}
}
Sentinel的限流规则通常不是在YML文件中配置的,而是通过Sentinel Dashboard进行动态配置。这里设置一些基础配置,例如数据源等。
在application.yml中,你可以配置Sentinel的数据源类型以及Dashboard的地址。
spring:cloud:sentinel:transport:dashboard: 127.0.0.1:8080 # Sentinel Dashboard的地址datasource:flow:default:type: filefile:file-name: classpath:flow-rules.json # 规则文件路径rule-type: flow
需要创建一个规则文件,例如flow-rules.json,并在其中定义限流规则。
[{"resource": "some-resource","count": 10,"grade": 1,"limitApp": "default","strategy": 0}
]
这里我们针对some-resource的QPS限流规则,允许每秒最多10个请求。Sentinel的主要优势在于其动态规则管理能力,因此通常建议通过Sentinel Dashboard进行实时配置和监控。
当然,对于限流,也可以在网关层面使用Spring Cloud Gateway实现。如下图:
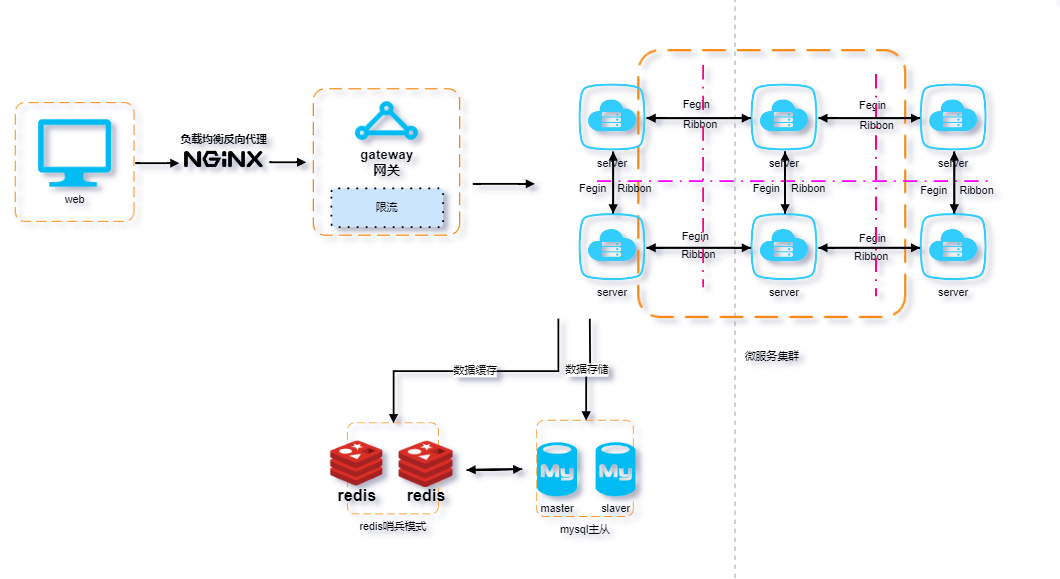
Spring Cloud Gateway是分布式系统中流量的入口。它需要对大量的请求进行管理和控制,以防止服务调用失败(如超时、异常)导致的请求堆积在网关上。通过在网关层面进行限流,可以快速失败并返回给客户端,从而保护后端服务的稳定性。
方案四:设计多级缓存架构
多级缓存主要从:redis缓存、本地缓存、Nginx缓存考虑
构建多级缓存架构:nginx 缓存 + redis 缓存 + 其他缓存(ehcache 等)。
使用锁或队列:用加锁或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上,该方法不适用高并发情况。
设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际 key 的缓存。
将缓存失效时间分散开:比如可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
4. 缓存预热
缓存预热是一种缓存优化技术,其核心思想是在系统上线或服务重启之前,提前将相关的缓存数据加载到缓存系统中。这样做的目的是为了避免在实际请求到达时进行缓存项的加载,从而减少了响应时间,提升了系统的性能。
以下是一些常见的缓存预热实现方案:
方案一:批量预加载数据
在系统启动或服务重启时,可以批量查询数据库并将结果存入缓存中。这种方式适用于数据量相对固定且比较小的情况。比如:常用的字典配置信息。
public void preloadCache() {List<String> keys = ... // 获取需要预热的缓存键列表for (String key : keys) {Object value = dao.get(key); // 从数据库中获取数据if (value != null) {redis.set(key, serialize(value), cacheExpiration); // 将数据存入缓存}}
}方案二:异步预热
如果预热的数据量很大,或者预热过程比较耗时,可以考虑使用异步任务来执行预热操作。这样可以避免阻塞系统启动,并且可以利用系统的空闲时间来预热缓存。
@PostConstruct
public void startPreloadCacheAsync() {CompletableFuture.runAsync(() -> preloadCache());
}方案三:定时任务预热
对于某些周期性变化的数据,可以用定时任务来定期预热缓存。例如,对于每天更新的数据,可以在每天的某个固定时间执行预热操作。
@Scheduled(fixedRate = 24 * 60 * 60 * 1000) // 每天执行一次
public void schedulePreloadCache() {preloadCache();
}方案四、使用SpringBoot InitializingBean接口实现
下面是一个使用InitializingBean接口实现缓存预热的示例:
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;@Component
public class CachePreloader implements InitializingBean {@Overridepublic void afterPropertiesSet() throws Exception {// 获取需要预热的缓存键列表List<String> keysToPreload = ...; for (String key : keysToPreload) {// 从数据源获取数据Object value = dbService.get(key); if (value != null) {// 将数据放入缓存cacheService.put(key, value);}}}
}总结:
本文主要介绍了redis缓存使用中常见的问题:缓存雪崩、缓存击穿、缓存穿透、缓存预热等。详情归纳如下:
| 缓存问题 | 产生原因 | 解决方案 |
|---|---|---|
| 缓存雪崩 | 大量缓存失效,导致数据库过载 | 1. 分散缓存失效时间 2. 多级缓存 3. 缓存高可用 4. 服务降级限流 |
| 缓存穿透 | 查询不存在的数据,导致数据库过载 | 1. 布隆过滤器 2. 空值缓存 |
| 缓存击穿 | 热点数据失效,导致数据库过载 | 1. 热点数据永不过期 2. 使用互斥锁 |
关于热点数据:
Redis中的热点数据是指在一段时间内访问频次极高、热度很高的数据。这些数据在短时间内被大量请求访问,成为整个Redis缓存系统中被频繁查询或更新的对象。热点数据的特点是访问集中在少数几个Key上,可能导致以下几个问题:
-
缓存命中率下降:热点数据如果在缓存中失效,短时间内大量请求涌向数据库以获取该数据,缓存命中率急剧下降,增加了数据库的压力。
-
缓存雪崩风险:如果热点数据集中设置了相同的过期时间,过期后同时失效,可能会引发缓存雪崩效应,即大量请求瞬间落库,可能导致数据库不堪重负。
-
缓存穿透:在极端情况下,热点数据频繁访问的同时,如果该数据恰巧不在缓存中或者已经被移除,每一条请求都会直接穿透缓存到达数据库,加重数据库的负载。
为了避免和优化热点数据带来的问题,可以采取以下策略:
- 延长热点数据的缓存有效期:适当延长热点数据在缓存中的存活时间,以减少数据库查询的次数。
- 使用互斥锁:在更新热点数据时使用分布式锁,确保数据更新时的一致性和完整性,避免频繁更新导致的缓存失效问题。
- 缓存预热:预测和主动加载热点数据到缓存中,确保在高峰期到来之前数据已经存在于缓存中。
- 缓存淘汰策略优化:选用合适的淘汰策略,例如Redis的LFU(Least Frequently Used)策略可以优先保留访问频次最高的数据,即热点数据。
- 数据分片与扩容:如果热点数据集中度非常高,可以考虑将热点数据单独存储或分片存储,并根据访问情况进行动态扩容。
总之,妥善管理和优化Redis中的热点数据对于维持系统性能和稳定性至关重要。

![[Arduino学习] ESP8266读取DHT11数字温湿度传感器数据](https://img-blog.csdnimg.cn/img_convert/b60776036a0db552385d149d48c7bd4f.png)