线程池简介
Java在使用线程执行程序时,需要调用操作系统内核的API创建一个内核线程,操作系统要为线程分配一系列的资源;当该Java线程被终止时,对应的内核线程也会被回收。因此,频繁的创建和销毁线程需要消耗大量资源。此外,由于CPU核数有限,大量的线程上下文切换会增加系统的性能开销,无限制地创建线程还可能导致内存溢出。为此,Java在JDK1.5版本中引入了线程池。
线程池是一种重用线程的机制,用于提高线程的利用率和管理线程的生命周期,常用于多线程编程和异步编程。
线程池的优点:
- 降低资源消耗:线程池中的线程可以重复使用,避免因频繁创建和销毁线程而带来的性能开销。
- 提高响应速度:向线程池中提交任务时,无需创建线程即可执行任务处理。
- 方便线程管理:线程池可以对其中的线程进行统一管理、监控,避免因大量创建线程而导致内存溢出。
线程池实现原理
Java线程池的核心实现类为ThreadPoolExecutor。
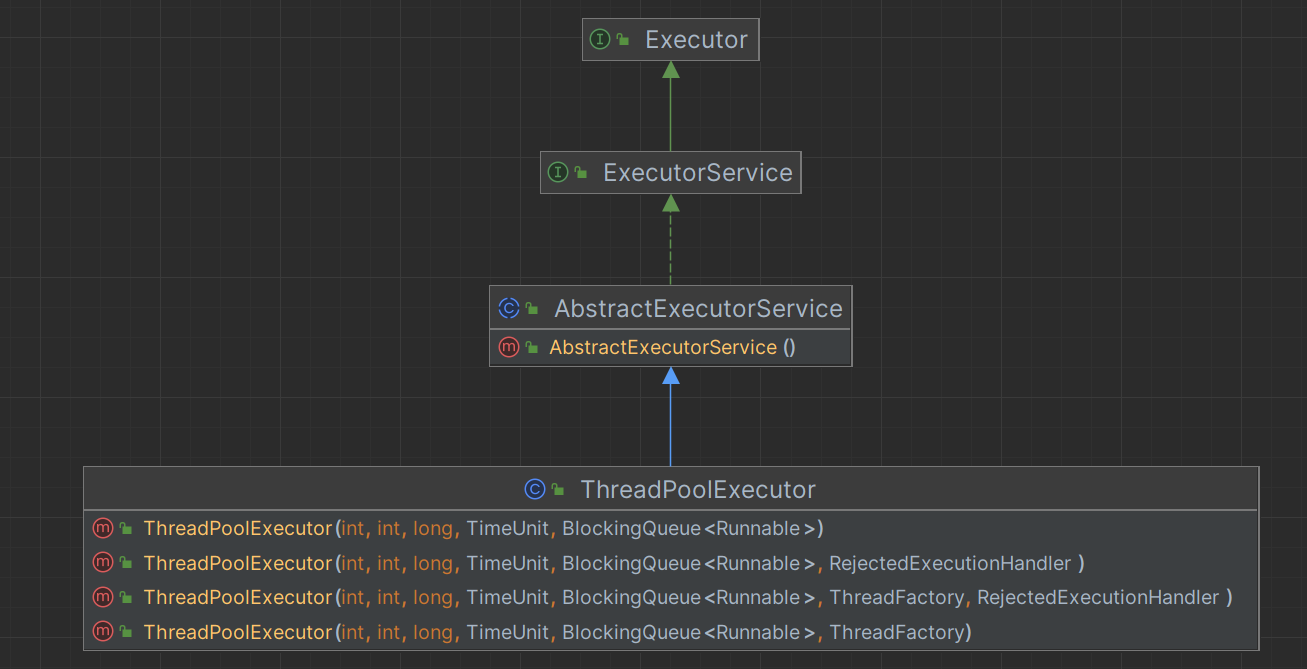
ThreadPoolExecutor依赖关系
ThreadPoolExecutor依赖关系图:
其中:
- Executor(接口):该接口线程池处理任务的顶级接口,定义了一个用于执行任务的方法execute(Runnable command)。其中参数command为实现了Runnable或Callable接口的Task任务。
- ExecutorService(接口):该接口继承了Executor接口,它扩展了Executor接口,并添加了一些管理线程池的方法(如:提交任务、关闭线程池等)。
- AbstractExecutorService(抽象类):该类实现了ExecutorService接口。
构造函数
如ThreadPoolExecutor依赖关系图所示,ThreadPoolExecutor类提供了四个构造函数,其中原始的构造函数(另外三个构造函数由原始构造函数衍生而来):
线程池的构造函数:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;
}
核心参数:
-
corePoolSize:线程池中的核心线程数,当向线程池中提交任务时,线程池创建新线程执行任务处理,直到当前线程数达到corePoolSize设定的值。此时提交的新任务会被添加到阻塞队列中,等待其他线程执行完成。默认情况下,空闲的核心线程并不会被回收(即:属性allowCoreThreadTimeOut的值默认为false),如果需要回收空闲的核心线程,设置属性allowCoreThreadTimeOut的值为true即可。
-
maximumPoolSize:线程池中的最大线程数,当线程池中的线程数达到corePoolSize设定的值且核心线程均被占用时,如果阻塞队列已满并向线程池中继续提交任务,则创建新的线程执行任务处理,直到当前线程数达到maximumPoolSize设定的值。
-
keepAliveTime:线程池中线程的存活时间,该参数只会在线程数大于corePoolSize设定的值时才生效,即:非核心线程的空闲时间超过keepAliveTime设定的值时会被回收。
-
unit:线程池中参数keepAliveTime的时间单位,默认为TimeUnit.MILLISECONDS(毫秒),其他时间单位:
-
- TimeUnit.NANOSECONDS(纳秒)
- TimeUnit.MICROSECONDS(微秒)
- TimeUnit.MILLISECONDS(毫秒)
- TimeUnit.SECONDS(秒)
- TimeUnit.MINUTES(分钟)
- TimeUnit.HOURS(小时)
- TimeUnit.DAYS(天)
-
workQueue:线程池中保存任务的阻塞队列,当线程池中的线程数达到corePoolSize设定的值,继续提交任务时会将任务添加到阻塞队列中等待。默认为LinkedBlockingQueue,可选择的阻塞队列:
-
- LinkedBlockingQueue(基于链表实现的阻塞队列)。
- ArrayBlockingQueue(基于数组实现的阻塞队列)。
- SynchronousQueue(只有一个元素的阻塞队列)。
- PriorityBlockingQueue(实现了优先级的阻塞队列)。
- DelayQueue(实现了延迟功能的阻塞队列)。
-
threadFactory:线程池中创建线程的工厂,可以通过自定义线程工厂的方式为线程设置一个便于识别的线程名,默认为DefaultThreadFactory。
-
handler:线程池的拒绝策略(又称饱和策略),当线程池中的线程数达到maximumPoolSize设定的值且阻塞队列已满时,继续向线程池中提交任务,就会触发拒绝策略,默认为AbortPolicy。可选的拒绝策略:
-
- AbortPolicy:丢弃任务,并抛出RejectedExecutionException异常。
- DiscardPolicy:丢弃任务,不抛出异常。
- DiscardOldestPolicy:丢弃队列中最早的未处理的任务,执行当前任务。
- CallerRunsPolicy:由调用者所在的线程来执行任务。
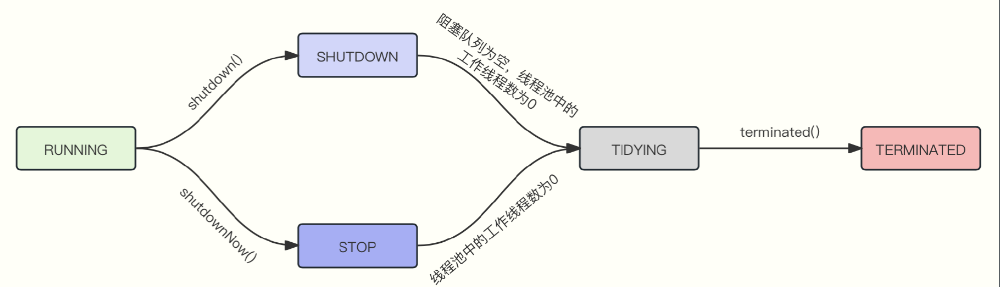
线程池生命周期
在ThreadPoolExecutor类中定义了线程池的五种状态。
源码如下:
// ctl共32位,其中高3位表示线程池运行状态,低29位表示线程池中的线程数量。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;// 二进制为0001 1111 1111 1111 1111 1111 1111 1111
private static final int CAPACITY = (1 << COUNT_BITS) - 1;// runState is stored in the high-order bits
// RUNNING状态:二进制为111 00000000000000000000000000000
private static final int RUNNING = -1 << COUNT_BITS;
// SHUTDOWN状态:二进制为000 00000000000000000000000000000
private static final int SHUTDOWN = 0 << COUNT_BITS;
// STOP状态:二进制为001 00000000000000000000000000000
private static final int STOP = 1 << COUNT_BITS;
// TIDYING状态:二进制为010 00000000000000000000000000000
private static final int TIDYING = 2 << COUNT_BITS;
// TERMINATED状态:二进制011 00000000000000000000000000000
private static final int TERMINATED = 3 << COUNT_BITS;// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 线程池中的线程数量
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
其中:
ctl是一个AtomicInteger类型的变量:
- 高3位表示线程池的运行状态。
- 低29位表示线程池中的线程数量。
线程池运行状态:
- RUNNING:处于RUNNING状态的线程池会接受新任务提交,同时也会处理任务队列中的任务。
- SHUTDOWN:处于SHUTDOWN状态的线程池不会接受新任务提交,但是会处理任务队列中的任务。
- STOP:处于STOP状态的线程池不会接受新任务提交,也不会处理任务队列中的任务,并且会中断正在执行的任务。
- TIDYING:当所有的任务已终止、workerCount数量为0时,线程池会进入TIDYING状态,进入TIDYING状态会执行钩子方法terminated()。
- TERMINATED:执行完钩子方法terminated()后进入TERMINATED状态,此时线程池已终止。
线程池状态转换,如图所示:
工作线程
Worker(工作线程)是ThreadPoolExecutor的一个内部类,它继承了
AbstractQueuedSynchronizer(即:AQS)并实现了Runnable接口。其中:
- 通过继承AbstractQueuedSynchronizer类,可以控制在主线程中调用shutdown()方法时不会中断正在执行的工作线程。注意:调用shutdownNow()时会中断正在执行的工作线程。
- 通过实现Runnable接口,可以在run()方法中调用ThreadPoolExecutor#runWorker方法执行任务处理。
提交任务
向线程池中提交任务的方式有两种:
- 调用execute()方法。
- 调用submit()方法。
execute与submit的区别:
- 1)execute是Executor接口的方法,submit是ExecuteService接口的方法。
- 2)execute的入参为Runnable,submit的入参可以为Runnable、Callable、Runnable和一个返回值。
- 3)execute没有返回值,submit有返回值。
- 4)异常处理:execute会直接抛出异常,submit会在获取结果时抛出异常,如果不获取结果,submit不抛出异常。
以execute()方法为例,ThreadPoolExecutor实现了Executor接口定义的execute(Runnable command) 方法,该方法的主要作用是将任务提交到线程池中的执行。
execute(Runnable command) 方法源码如下:
public void execute(Runnable command) {// 如果command为null,则抛出空指针异常if (command == null)throw new NullPointerException();// 获取ctl变量值,ctl低29位用来表示线程池中的线程数量。int c = ctl.get();// 如果线程池中的线程数小于设定的核心线程数,则将任务封装成Worker线程并调用其start()方法启动线程if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 如果线程池处于运行状态并向任务队列中添加任务成功,则执行如下逻辑(此处线程池中的线程数大于等于核心线程数)if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 继续判断线程池处于运行状态,如果线程池不是运行状态且从线程池中移除任务成功,则执行拒绝策略if (! isRunning(recheck) && remove(command))reject(command);// 如果线程池中线程数为0,则创建Worker线程并执行任务else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 如果创建Worker线程失败,则执行拒绝策略else if (!addWorker(command, false))reject(command);
}
ThreadPoolExecutore#xecute()方法执行逻辑,如图所示:
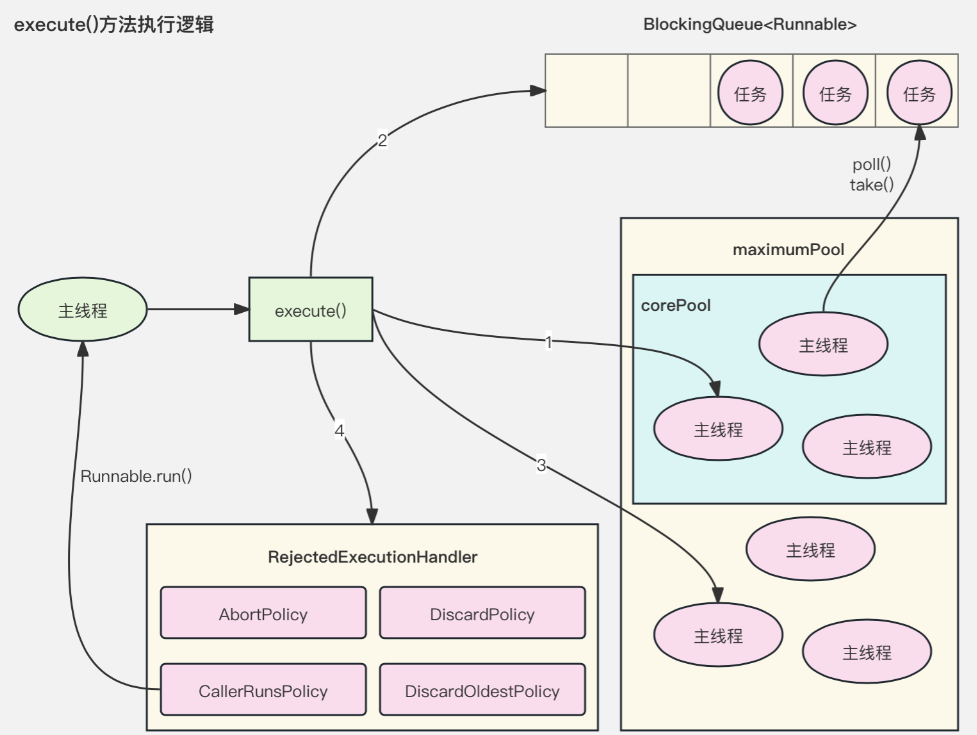
处理流程:
1)主线程通过execute()方法向线程池中提交任务:
-
线程池中的线程数小于核心线程数,继续向线程池中提交任务时,创建线程执行任务处理。
-
线程池中的线程数大于等于核心线程数:
a) 如果阻塞队列未满,继续向线程池中提交任务时,将任务添加到阻塞队列中,等待处理。
b) 如果阻塞队列已满且线程数小于最大线程数,继续向线程池中提交任务时,创建线程执行任务处理。
c) 如果阻塞队列已满且线程数大于等于最大线程数,继续向线程池中提交任务时,执行拒绝策略。
执行任务
任务提交到线程池中后,会执行工作线程(Worker)的ThreadPoolExecutor.Worker#run方法执行任务处理,而run()方法中会调用ThreadPoolExecutor#runWorker方法。
ThreadPoolExecutor#runWorker方法中,通过自旋的方式从Worker工作线程或阻塞队列中获取任务进行处理:
- 如果Worker工作线程中存在任务,则执行Worker工作线程中的任务。
- 如果Worker工作线程中不存在任务,则通过getTask()方法从获取任务,并执行该任务。
- 如果Worker工作线程和阻塞队列中没有可执行的任务,则退出并销毁Worker工作线程。
线程池工作流程
线程池工作流程,如图所示:
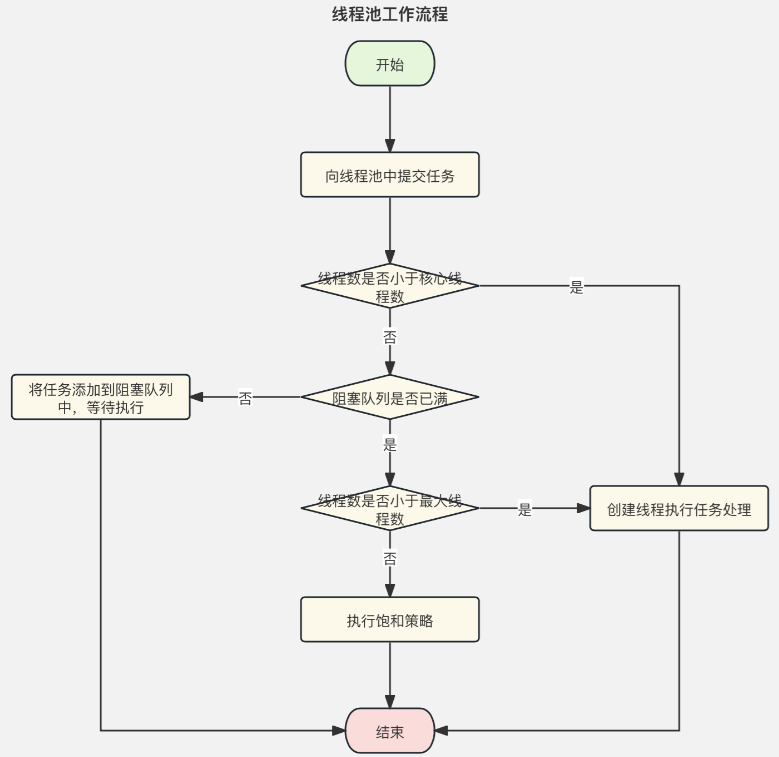
处理流程:
1)向线程池中提交任务,判断线程池中线程数是否小于核心线程数:
-
线程数小于核心线程数,则创建线程执行任务处理。
-
线程数大于等于核心线程数,则判断线程池中阻塞队列是否已满:
a) 阻塞队列未满,则将任务添加到阻塞队列中,等待执行。
b) 阻塞队列已满,则判断线程池中的线程数是否小于最大线程数:
线程数小于最大线程数,则创建线程执行任务处理。
线程数大于等于最大线程数,则执行拒绝策略。
线程池创建方式
线程池的创建方式一般分为两种:
- 通过Executors类创建线程池。
- 通过ThreadPoolExecutor类创建线程池。
通过Executors类创建线程池
Executors类是JDK提供的一个创建线程池的工具类,内部通过调用ThreadPoolExecutor构造函数来实现,通过该类提供的静态方法可以快速创建一些常用线程池。
newFixedThreadPool
创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待。
静态方法:
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
其中:
- 核心线程数为初始化时指定的线程数,核心线程数等于最大线程数。
- 线程存活时间keepAliveTime为0,表示线程空闲时立刻被回收。
- 阻塞队列为LinkedBlockingQueue(默认值)。
newCachedThreadPool
创建一个可缓存的线程池,该线程池的大小为Integer.MAX_VALUE,对于提交的新任务:
- 如果存在空闲线程,则使用空闲线程来执行任务处理。
- 如果不存在空闲线程,则新建一个线程来执行任务处理。
- 如果线程池中的线程数超过处理任务需要的线程数,则空闲线程缓存一段时间(60s)后会被回收。
静态方法:
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
其中:
- 核心线程数为0。
- 最大线程数为Integer.MAX_VALUE。
- 线程存活时间keepAliveTime为60s。
- 阻塞队列为SynchronousQueue(同步队列)。
newSingleThreadExecutor
创建一个单线程化的线程池,它只有一个工作线程来执行任务,所有任务按照先进先出的顺序执行。
静态方法:
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
其中:
- 核心线程数为1。
- 最大线程数为1。
- 线程存活时间keepAliveTime为0,表示线程空闲时立刻被回收。
- 阻塞队列为LinkedBlockingQueue。
newScheduledThreadPool
创建一个计划线程池,支持定时或周期性的执行任务(如:延时任务)。
静态方法:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
其中:
- 核心线程数为初始化时指定的线程数。
- 最大线程数为Integer.MAX_VALUE。
- 线程存活时间keepAliveTime为0,表示线程空闲时立刻被回收。
- 阻塞队列为DelayedWorkQueue(延时队列)。
其他线程池
Executors工具类除了能快速创建以上的常用线程池外,还可以创建很多其他线程池。如:
- Executors.newSingleThreadScheduledExecutor:创建一个单线程化的计划线程池(newScheduledThreadPool的单线程版本)。
- Executors.newWorkStealingPool:创建一个抢占式执行的线程池(任务执行顺序不确定),该线程池JDK1.8添加。
代码示例:
ExecutorsExample.java
@Slf4j
public class ExecutorsExample {/*** 创建一个固定大小的线程池*/private static ExecutorService executor = Executors.newFixedThreadPool(10);public static void main(String[] args) {for (int i = 0; i < 10000; i++) {// 在线程池中执行任务executor.execute(new Task());}}/*** 任务线程*/static class Task implements Runnable {@Overridepublic void run() {try {Thread.sleep(1000);log.info("执行线程:{}", Thread.currentThread().getName());} catch (InterruptedException e) {log.info("线程中断异常");}}}
}
不推荐使用Executors类创建线程池,主要原因:Executors类创建线程池默认使用LinkedBlockingQueue,LinkedBlockingQueue默认大小为Integer.MAX_VALUE(相当于无界队列),在高负载情况下很容易导致OOM。因此,强烈建议使用有界队列创建线程池。
通过ThreadPoolExecutor类创建线程池
通过ThreadPoolExecutor类手动创建线程池(推荐方式)。
代码示例:
ThreadPoolExecutorExample.java
@Slf4j
public class ThreadPoolExecutorExample {/*** 定义线程池*/private static ExecutorService pool ;public static void main(String[] args) {// 创建线程池pool = new ThreadPoolExecutor(10, 20, 0,TimeUnit.SECONDS,new ArrayBlockingQueue<>(5),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());// 在线程池中执行任务for (int i = 0; i < 10000; i++) {pool.execute(new ThreadPoolExecutorExample.Task());}}/*** 任务线程*/static class Task implements Runnable {@Overridepublic void run() {try {Thread.sleep(1000);log.info("执行线程:{}", Thread.currentThread().getName());} catch (InterruptedException e) {log.info("线程中断异常");}}}
}
其他推荐方式:通过commons-lang3、com.google.guava等工具包创建线程池,创建示例自行查阅相关资料即可。
线程池大小设置
在并发编程领域,提升性能本质上就是提升硬件的利用率(即:提升CPU和I/O设备综合利用率)的问题。因此,线程池大小需要根据CPU密集型和I/O密集型场景进行设置:
- 对于CPU密集型场景,线程池大小一般设置为:CPU核数 + 1。
- 对于I/O密集型场景,线程池大小一般设置为:CPU核数 * [1 +(I/O耗时 / CPU耗时)]。
以上公式仅作为参考值,具体情况需要根据压测情况进行设置。